Don't fly solo! 量化人如何使用AI工具
在投资界,巴菲特与查理.芒格的神仙友谊,是他们财富神话之外的另一段传奇。巴菲特曾这样评价芒格:他用思想的力量拓展了我的视野,让我以火箭的速度,从猩猩进化到人类。
人生何幸能得到一知己。如果没有这样的机缘,在AI时代,至少我们做量化时,可以让AI来伴飞。
这篇文章,分享我用AI的几个小故事。
在讲统计推断方法时,需要介绍分位图(Quantile-Quantile Plot)这种可视化方法人类天生就有很强的通过视觉发现pattern的能力,所以介绍这种可视化方法几乎是不可缺少的。
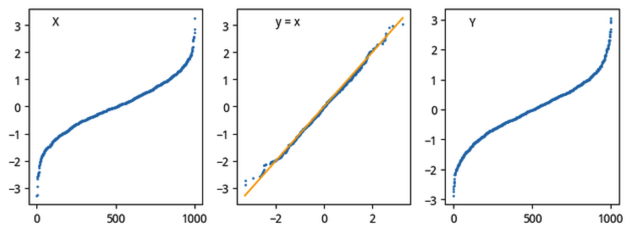
但当时在编这部分教材时,我对QQ-plot的机制还有一点不太清晰:为什么要对相比较的两个随机变量进行排序,再进行绘图?为什么这样绘图如果得到的是一条直线,就意味着两个随机变量强相关?难道不应该是按随机变量发生的时间顺序为序吗?
启用GPT-4的多角色数据科学家扮演¶
这个问题无人可请教,哪怕我搜遍全网。后来,即使我通过反复实验和推理,已经明白了其中的道理,但毕竟这个知识点似乎无人提及过,心里多少有点不确定。于是,我请教了GPT-4。
最初的几次尝试没有得到我想要的结论,于是,我用了一点技巧,要求GPT-4把自己想像成为数据科学家。并且,为了避免错误,我使用了三个数据科学家进行角色扮演,让A和B分别提出观点,再让C来进行评论,这一次,我得到了非常理想的结果,即使请教人类专家可能亦不过如此。
先给GPT-4提供问题背景:
Quote
Q-Q图的原理是,如果X是一个有序数据集,那么[X, X]在二维平面上的图像一定是一条45度角的直线。
如果我们有随机变量X和设想中的理论分布Y,如果随机变量X服从估计中的理论分布Y,那么就应该有:
在50%分位处,X的采样点\(x_1\)应该与50%分位处的\(y_1\)非常接近(由于是随机变量,所以也很难完全相等);在25%分位处,75%分位处,或者进一步推广,在任意分位数处,两者的采样都非常接近。
在实际绘图中,我们的做法是,假设X服从正态分布,共有n个数据,我们先对X进行z-score变换,然后从标准正态分布中,也随机抽样取n个数,记为Y,对两个数组都进行排序后,对[X, Y]进行绘图,如果它的图形接近于直线,则说明X服从正态分布。
从背景可以看出,我已经掌握了QQ图的大致原理。如果X与Y是同分布的,那么,将X,Y排序后,分别以\([I,X]\)和\([I,Y]\)(\(I\)为数组坐标)为点绘制的曲线,将会是相似曲线。
但QQ图将其进行了变换,直接取每一个坐标\(I_i\)对应的\(X_i\)和\(Y_i\)作为曲线的坐标,从而将只绘制出一条曲线。如果二者同分布,则该曲线将是一条直线。当时我对这个变换的性质还不太了解。
我的问题一共有4个:
Question
- 这段话中是否有事实错误?
- 如果不对X进行z-score化,这样[X,Y]还会是直线吗?
- n值对绘制图形的影响是?
- 假设X确实服务正态分布,从标准正态分布中进行抽样得到的Y,是如何保证它与X一一对应的?
最后一问,实际上就是要问这个变换为什么能成立。
GPT-4的角色 -- 数据科学家A发现了背景中第一段的一个错误。\([X,X]\)的图像为45度直线的条件并不需要\(X\)是有序的。任何数据集的\([X,X]\)图像都会是45度直线(显然)。对于第2问,A的回答是:
Quote
If we don't standardize X (i.e., perform a z-score transformation), the Q-Q plot may not form a 45-degree line. The reason we standardize is to put X and Y on the same scale, which makes it easier to compare them.
对于第三问,数据科学家A认为:
Quote
The number of data points (n) can affect the Q-Q plot in terms of its granularity. The more points we have, the smoother and more precise the plot will be. However, even with a small n, if the data follows the theoretical distribution, the points should still fall roughly along the line of equality.
n只影响图像的平滑度和我们判断时的精度。这一点非常准确。但我最关注的是第四位,随机变量X与Y究竟是如何对应的,为什么可以将它们按大小排序?A的回答是:
Quote
Y, sampled from a standard normal distribution, does not necessarily correspond one-to-one with X in terms of specific data points. Instead, it corresponds to X in terms of the order of data points. When we sort X and Y, the smallest value of X is paired with the smallest value of Y, the second smallest with the second smallest, and so on.
答案几乎已经呼之欲出了。即使两个随机变量服从同一分布,它们的值也不会相等,但是,出现在同一位置上的随机变量值,它们的差值会很小。因此,这样绘制出来的图,就是一条45度直线。
B和C主要是对A的结论进行质疑、比较,这里不赘述了。
无论A、B还是C都没有给出最终的解释:为什么如果随机变量X和Y服从同一分步的话,那么在同一位置i处的\(X_i\)和\(Y_i\)应该是接近的。但它们确实证实了我们绘制QQ图之前,先对随机变量进行排序的思路是正确的。
Info
关于这一点,应该从CDF/PPF的概念入手来理解。如果\(X\)和\(Y\)是同分布的,那么在任一分位\(i\)上,随机变量的值(通过ppf,即cdf的逆函数来计算)都应该非常接近。而排序后的数组,其坐标天然就有了分位数的意义。既然\(X\)与\(Y\)在任一坐标\(i\)上都应该接近,那么点\(X_i, Y_i\)就应该落在直线\(y=x\)上。这个变换的作用,是利用人眼对直线更为敏感的现象,把不易分辨的两条曲线相似度的检测,转换成一条曲线是否为直线的检测。
事实上,这一概念在英文wiki上解释的比较清楚。但我当时只看了中文的wiki。
如果上述概念还不好理解,我们可以再举一个更直观的例子。通过QQ图来判断两个证券标的是否存在强相关性。比如,我们以两支同行业个股为例,取它们最近250期日线,计算每日回报率,对其进行排序后绘图:
1 2 3 4 5 6 7 8 9 | |
我们将得到如下的分位图:

这就非常直观地显示出,两支个股的走势确实相关:在涨幅4%以下的区域,如果A下跌,那么B也下跌,并且幅度都差不多;如果A上涨,那么B也上涨;幅度也差不多。这正是相关性的含义。这里我们排除了时间,只比较了两个随机变量即日收益率。
Tip
注意看这张图中涨幅大于4%的部分。它意味着,某个标的涨幅大于4%时,另一个标的的上涨幅度没有跟上。这里可能隐藏了潜在的机会。你知道该怎么分析吗?
跟着copilot学编程¶
有两个版本的copilot。一个是copilot,另一个,现在被叫作github copilot,是vscode中的一个扩展。后者2022年中就发布了,当时有6个月的免费试用期。试用期内一炮而红,迅速开启了收费模式。这也直接导致了同年11月同赛道的工具软件Kite的退出。
现在github copilot每月$10,尽管物有所值,但作为不是每天都coding的人来说,感觉如果能推出按token付费的模式是最好了。
它的两个免费版本,一个是对学生免费。有edu邮箱的可以抓紧在github上申请下。另一个是如果你的开源项目超过1000赞,则有机会申请到免费版。
一般我使用copilot作为编程补充。它在错误处理方面可以做得比我更细腻,另外,在写单元测试用例时(建议每个量化人都坚持这样做),自动补齐测试数据方面是一把好手。
但是我没有想到的是,有一天它还能教我学编程,让我了解了一个从来没有听说过的Python库。
整个事情由ETF期权交割日引起。近年来似乎形成了这样一个规律,每逢期权交割日,A股的波动就特别大,而且以向下波动为主。因此,量化程序需要把这些交割日作为因子纳入交易体系。
但是这些交割日的确定,出入意料地--难。它的规则是:
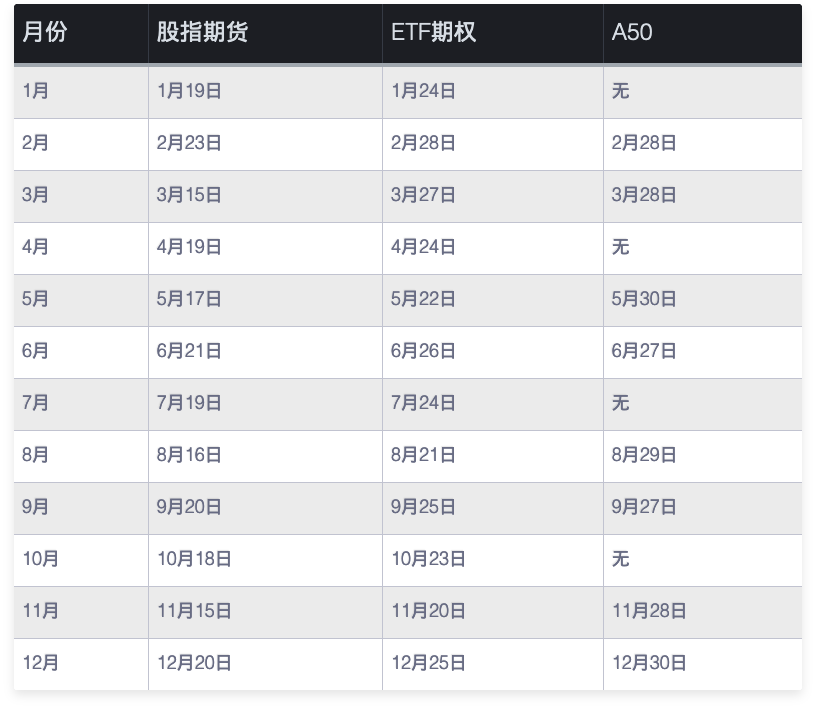
股指期货的交割日为每月的第三周周五;ETF期权交割日为每月第四周的周三;A50交割日为相关月的倒数第二个交易日。
在刚刚过去的4月19日,是一个股指期货交割日。接下来的4月24日,则是ETF交割日。今年的交割日如下:
随手写了几行代码,发现这个日子还是比较难算的。于是打开copilot chat,问它:
Quote
股指期货的交割日为每月的第三周周五;ETF期权交割日为每月第四周的周三;A50交割日为相关月的倒数第二个交易日。
根据上述信息,写一个方法,求出2018年到2024年12月31日止的各个交割日。
Copilot并不知道股市日历,所以无法独立完成上述任务。这并不奇怪。令人惊喜地是,它使用了calendar.monthcalendar这个方法。尽管calendar是一个标准库,但我之前并不知道它还有这个用法。
1 2 3 | |
在这个基础上改就容易多了。另一个有趣的例子,是让copilot帮我想函数名。
我喜欢使用这样一个因子,最近20天内,涨幅中位数与跌幅中位数的比率。显然,这个比值越大,说明做多的力量越强。
最初我使用caculate_ratio这个函数名。但几乎所有的因子计算都可以使用这个名字。因此,我让copilot给一个准确点的名字。copilot回答说,根据函数的功能,我们可以将函数名从calculate_ratio改为calculate_downward_exceeding_upward_median_ratio。这个名字更准确地描述了函数的功能:计算下跌幅度超过上涨中位数的比例。
不过,这个名字太长了,也不优雅。于是,我问copilot,名字可以再短一点吗?可以使用metaphore吗?Coplilot回答说:
Quote
当然可以。我们可以使用"bear_bull_ratio"作为函数名。这个名字较短,且使用了金融市场的术语"bear"和"bull",分别代表市场下跌和上涨,这样可以更好地传达函数的含义。