06 10 倍速!高效编码
Table of Content
1. AI 赋能的代码编写¶
传统上,IDE 的重要功能之一,就是代码自动完成、语法高亮、文档提示、错误诊断等等。随着人类进入深度学习时代,AI 辅助编码则让程序员如虎添翼。
我们首先介绍几个 AI 辅助编码的工具,然后再介绍常规的语法高亮、文档提示等功能。
1.1. github copilot¶
github copilot 是 github 官方出品的 AI 辅助编码工具。它是基于大规模语料、超大规模的深度学习模型,结合了大量的编程经验,为开发者提供代码补全、代码片段联想、代码推荐等功能。copilot 可以根据用户输入的一行注释,自动生成代码片段甚至整个函数,功能十分强大。
Info
2023 年 12 月,微软把他们基于 chatGPT 的人工智能搜索引擎技术也称为 copilot,它是您在使用 bing 搜索引擎时,出现的一个对话机器人。Github 现在也是微软的资产。
比如,我们写一段注释如下:
1 | |
1 2 3 4 5 | |
我们再举一个例子,如果有以下注释:
1 | |
1 | |
我们再试一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
更令人惊叹的是 main 函数。我只定义了 main() 方法的函数头,copilot 居然自动完成了所有功能的串联,而且应该说,符合预期。
如果上面的例子过于简单,你可以写一些注释,请求 copilot 为你抓取加密货币价格,通过正则表达式判断是否是有效的邮箱地址,或者压缩、解压缩文件等等。你会发现,copilot 的能力是非常强大的。
copilot 的神奇之处,绝不只限于上面的举例。作者在实践中确实体验过它的超常能力,比如在单元测试中,自动生成数据序列,或者在生成的代码中,它的错误处理方案会比你自己能写出来的更细腻,等等。但是,要演示那样复杂的功能,已经超出了一本书能够展现的范围了。
这是一些使用者的感言:
Quote
我的一部分工作内容从编写代码转成了策划。作为一个人类可以观察并修正一些代码,不必亲自动手做每一件事。
我对冗余代码的容忍度变高了。让 AI 去做重复的工作,把代码写得更详细,可以提高可读性。
我更愿意重构代码了。对于那些已经能用但写的不够理想的代码,Copilot 可以灵活的完成重构,比如把复杂函数拆分或对关键部分抽象化。
所以,Don't fly solo(copilot 广告语)!如果有可能,当你在代码的世界里遨游时,还是让 copilot 来伴飞吧。当然,copilot 也有其不足,其中最重要的一点是,不能免费使用(学生除外),而且每个月 10 美金的费用对中国程序员来讲可能并不便宜。不仅如此,目前它只接受信用卡和 paypal 付款,因此在支付上也不够方便。
1.2. tabnine¶
另一个选项是 tabnine,与 copilot 一样,它也提供了从自然语言到代码的转换,以及整段函数的生成等功能。一些评论认为,它比 copilot 多出的一个功能是,它能基于语法规则在一行还未结束时就给出代码提示,而 copilot 只能在一行结束后给出整段代码,即 copilot 需要更多的上下文信息。
tabnine 与 copilot 的值得一提的区别是它的付费模式。tabnine 提供了基础版和专业版两个版本,而 copilot 只能付费使用。tabnine 的专业版还有一个特色,就是你可以基于自己的代码训练自己的私有 AI 模型,从而得到更为个性化的代码完成服务。这个功能对于一些大型公司来说,可能是一个很好的选择。它的另一个优势就是,它在训练自己时只使用实行宽松开源许可证模式的代码,因此,你的代码不会因为使用了 tabnine 生成的代码,就必须开源出去。
GPT code clippy 是 Github copilot 的开源替代品,如果既不能用 copilot,也不能使用 tabnine,也可以试试这个。不过在我们成文的时候,它还没有提供一个发行版的 vscode 扩展,只能通过源码安装。
Info
说到 AI 辅助编码,不能不提到这一行的先驱 - Kite。Kite 成立于 2014 年,致力于 AI 辅助编程,于 2021 年 11 月关闭。由于切入市场过早,kite 的技术路线也必然相对落后一些,其 AI 辅助功能主要是基于关键词联想代码片段的模式。等到 2020 年 github 的 copilot 横空出世时,基于大规模语料、超大规模的深度学习模型被证明才是最有希望的技术路线。而此时 kite 多年以来的投入和技术积累,不仅不再是有效资产,反而成为了历史包袱。切换到新的技术路线上的代价往往是巨大的 -- 用户体验的改变在所难免,而且新的模型所需要的钞能力,kite 也并不具备。
2021 年 11 月 16 日,创始人 Adam Smith 发表了一篇告别演说,对 kite 为什么没有成功进行了反思,指出尽管 Kite 每个月有超过 50 万月活跃用户,但这么多月活跃用户基本不付费,这最终压垮了 kite。当然,终端用户其实也没有错,毕竟 copilot 的付费模式能够行得通。人们不为 kite 付费,也确实是因为 kite 还不够好。
属于 kite 的时代已经过去了,但正如 Adam Smith 所说,未来是光明的。AI 必将引发一场编程革命。kite 的试验失败了,但催生这场 AI 试验的所有人:投资人,开发团队以及最终用户,他们的勇气和贡献都值得被铭记。
作为一个曾经使用过 kite,也欠 Kite 一个会员的使用者,我也在此道声感谢与珍重!
尽管 AI 辅助编程的功能很好用,但仍然有一些场景,我们需要借助传统的工具,比如 pylance。pylance 是微软官方出品的扩展。vscode 本身只是一个通用的 IDE 框架,对具体某种语言的开发支持(编辑、语法高亮、语法检查、调试等),都是由该语言的扩展及语言服务器(对 python 而言,有 jedi 和 pylance 两个实现)来实现的,因此,pylance 是我们在 vscode 中开发 python 项目时,必须安装的一个扩展。
它可以随用户输入时,提示函数的签名、文档和进行参数的类型提示,如下图所示:
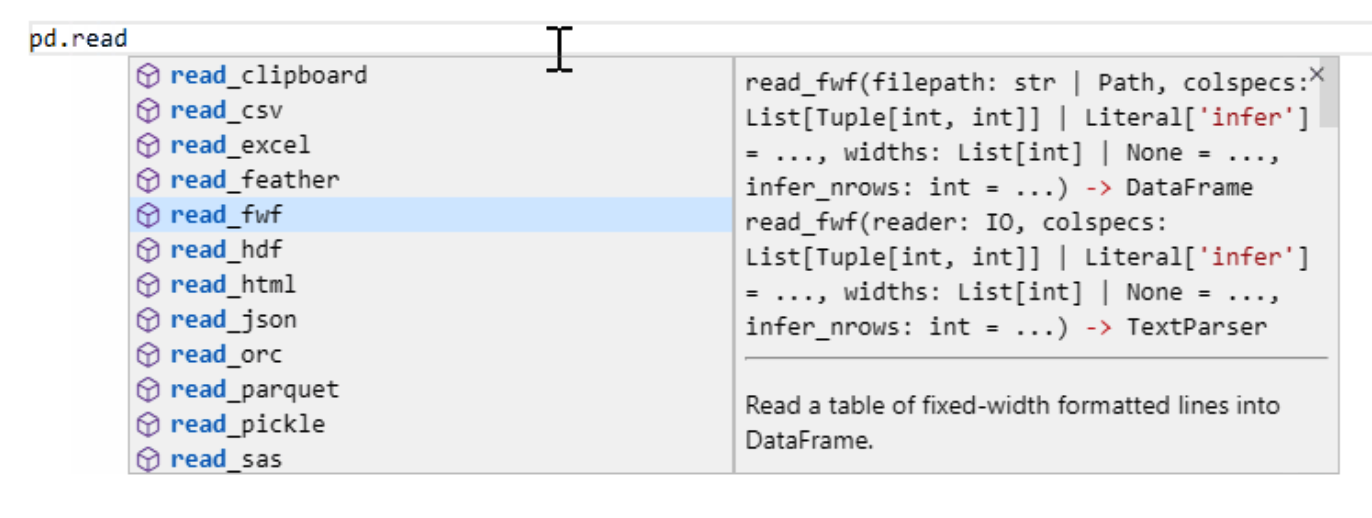
Pylance 在上面提到的代码自动完成之外,还能实现依赖自动导入。此外,由于它脱胎于语法静态检查器,所以它还能提示代码中的错误并显示,这正是到目前为止,像 copilot 这样的人工智能还做不太好的地方。源码级的查错,使得我们可以尽早修正这些错误,这也正是很多使用静态语言的程序员认为诟病 Python 的地方 – 现在我们知道,这只是一种无知的偏见。
Tips
Pylance 安装后,需要进行配置。配置文件是 pyrightconfig.json,放置在项目根目录下。
1 2 3 4 5 6 7 8 9 10 | |
2. Type Hint (Type Annotations)¶
很多人谈到 Python 时,会觉得它作为一种动态语言,是没有类型检查能力的。这种说法并不准确,Python 是弱类型语言,变量可以改变类型,但在运行时,仍然会有类型检查,类型检查失败,就会抛出 TypeError:
下面的例子演示了 Python 中变量是如何改变类型的,以及类型检查只在运行时进行的这一特点:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Python 曾经确实缺少静态类型检查的能力,这是 Python 一直以来为人诟病的地方。毕竟,错误发现的越早,修复成本就越低。但这正在成为历史。
类型注解从 python 3.0(2006 年,PEP 3107,当时还叫 function annotations)时被引入,那时它的用法和语义并没有得到清晰定义,因而也没有引起广泛关注和运用。数年之后,PEP 484(type hints including generics)被提出,定义了如何给 python 代码加上类型提示,这样,type annotation 就成为实现 type hint 的主要手段。因此,当今天人们提到 type annotation 和 type hint 时,两者基本上是同一含义。
PEP 484 是类型检查的奠基石。但是,仍然有一些问题没有得到解决,比如如何对变量进行类型注解?下面的语法在当时还是不支持的:
1 2 | |
2016 年 8 月,PEP 526(syntax for variable annotations) 提出,从此,像上文中的注解也是允许的了。
Info
PEP 526 从提出到被接受为正式标准不到 1 月的时间,可能是最快被接受的 PEP 之一。
PEP 563 (Postponed Evaluation of Annotations) 解决了循环引用的问题。在这个提案之后,我们可以这样写代码:
1 2 3 4 5 6 | |
在这几个重要的 PEP 之后,随着 Python 3.7 的正式发布,社区也开始围绕 Type Hint 去构建一套生态体系,一些非常流行的 python 库开始补齐类型注解,在类型检查工具方面,除了最早的 mypy 之外,一些大公司也跟进开发,比如微软推出了 pyright(现在是 pylance 的核心)来给 vscode 提供类型检查功能。google 推出了 pytype,facebook 则推出了 pyre。在类型注解的基础上,代码自动完成功能也因此变得更容易、准确,推断速度也更快了。代码重构也因此变得更加容易。
类型检查功能将对 Python 的未来发展起到深远的影响,可能足够与 typescript 对 js 的影响类比。围绕类型检查,除了上面提到的几个最重要的 PEP 之外,还有:
- PEP 483(解释了 python 中类型系统的设计原理,非常值得一读)
- PEP 544 (定义了对结构类型系统的支持)
- PEP 591 (提出了 final 限定符) 以及 PEP 561 等另外 18 个 PEP。此外,还有 PEP 692 等 5 个 PEP 目前还未被正式接受。
Python 的类型检查可能最早由 Jukka Lehtosalo 推动,Guido,Łukasz Langa 和 Ivan Levkivskyi 也是最重要的几个贡献者之一。Jukka Lehtosalo 出生和成长于芬兰,当他在剑桥大学计算机攻读博士时,在博士论文中,提出了一种名为“类型注解”(Type Annotations)的语法,从而一统静态语言和动态语言。最初的实验是在一种名为 Alore 的语言上实现的,然后移植到 Python 上,开发了 mypy 的最初几个版本。不过很快,他的工作重心就完全转移到 Python 上面来,毕竟,只有 Python 庞大的用户群和开源库才能提供丰富的案例以供实践。
2013 年,在圣克拉拉举行的 PyCon 会议上,他公布了这个项目,并且得到了与 Guido 交谈的机会。Guido 说服他放弃之前的自定义语法,完全遵循 Python 3 的语法,即 PEP 3107 提出的函数注解)。在随后他与 Guido 进行了大量的邮件讨论,并提出了通过注释来对变量进行注解的方案(不过后来的 PEP 526 提出了更好的方案)。
Jukka Lehtosalo 从剑桥毕业后,就接受了 Guido 的邀请,加入了 Dropbox,领导了 mypy 的开发工作。
这里也可以看出顶尖大学对待学术研究上的开放和不拘一格。大概在 2016 年前后,我看到斯坦福的网络公开课上还有讲授 ios 编程的课,当时也是同样的震撼。一是感叹他们选课之新,二是感叹这种应用型的课程,在国内的顶尖大学里,一般是不会开设的,因为大家会觉得顶尖的学术殿堂,不应该有这么“low”的东西。
在有了类型注解之后,现在我们应该这样定义一个函数:
1 2 3 4 5 | |
下面,我们简要地介绍一下 type hint 的一些常见用法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 | |
如果您的代码都做好了 type hint,那么 IDE 基本上能够提供和强类型语言类似的重构能力。需要强调的是,在重构之前,你应该先进行单元测试、代码 lint 和 format,在没有错误之后,再进行重构。如此一来,如果重构之后,单元测试仍然能够通过,则基本表明重构是成功的。
3. PEP8 - python 代码风格指南¶
PEP8 是 2001 年由 Guido 等人拟定的关于 python 代码风格的一份提案。PEP8 的目的是为了提高 python 代码的可读性,使得 python 代码在不同的开发者之间保持一致的风格。PEP8 的内容包括:代码布局,命名规范,代码注释,编码规范等。PEP8 的内容非常多,在实践中,我们不需要专门去记忆它的规则,只要用对正确的代码格式化工具,最终呈现的代码就一定是符合 PEP8 标准的。在后面的小节里,我们会介绍这一工具 -- black,因此,我们不打算在此处过多着墨。
4. Lint 工具¶
Lint 工具对代码进行逻辑检查和风格检查。逻辑检查是指像使用了未定义的变量,或者定义的变量未使用,没有按 type hint 的约定传入参数等等;风格检查是指变量命名风格、空白符、空行符的使用等。
Python 社区有很多 Lint 工具,比如 Plint, PyFlakes, pycodestyle, bandit, Mypy 等。此外,还有 Flake8 和 Pylama 这样,将这些工具组合起来使用的工具。
在选择 Lint 工具时,重要的指标是报告错误的完全度和速度。过于完备的错误报告有时候也不见得就是最好,有时候会把你的大量精力牵涉到无意义的排查中 -- 纯粹基于静态分析的查错,有时也不可避免会出现错误;同时也使得运行速度降低。
4.1. Flake8¶
ppw选择了 Flake8 和 mypy 作为 lint 工具。Flake8 实际上是一组 lint 工具的组合,它由 pycodestyle, pyflakes, mcccab 组成。
4.1.1. pycodestyle¶
pycodestyle 用来检查代码风格(空格、缩进、换行、变量名、字符串单双引号等)是否符合 PEP8 标准。
4.1.2. pyflakes¶
pyflakes 用来检查语法错误,比如,定义但未使用的局部变量,变量重定义错误,未使用的导入,格式化错误等等。人们通常拿它与 pylint 相对照。pyflakes 与 pylint 相比,所能发现的语法错误会少一些,但误报率更低,速度也更快。在有充分单元测试的情况下,我们更推荐初学者使用 pyflakes。
下面是一个 pylint 报告错误,而 pyflakes 不能报告的例子:
1 2 3 4 | |
但是 pylint 存在一定的误报率,上面的代码交给 pylint 来进行语法检查,其结果是:
1 2 3 4 5 6 | |
而最后一行的报告则显然是错误的,这里函数 add 没有返回值的错误,导致 pylint 误以为 value 是一个常量,而不是一个变量。事实上,当你修复掉 add 函数没有返回值的错误时,pylint 就不会报告这个错误了。
这是为什么我们推荐初学者使用 pyflakes,而不是 pylint 的原因。初学者很容易淹没在 pylint 抛出的一大堆错夹杂着误报的错误报告中,花费大量时间来解决这些误报,却茫然无计。另外,pylint 过于严格的错误检查,对还未养成良好编程习惯的初学者,可能会使他们感到沮丧。比如,上面关于缺少文档的错误报告,尽管是正确的,但对初学者来说,要一下子达到所有这些标准,会使得学习曲线变得过于陡峭,从而导致学习的热情降低。
mccabe 用来检查代码的复杂度,它把代码按控制流处理成一张图,从而代码的复杂度可以用下面的公式来计算: \(M = E - N + P\),其中 E 是路径数,N 是节点数,P 则是决策数。
以下面的代码为例:
1 2 3 4 5 6 7 8 9 | |
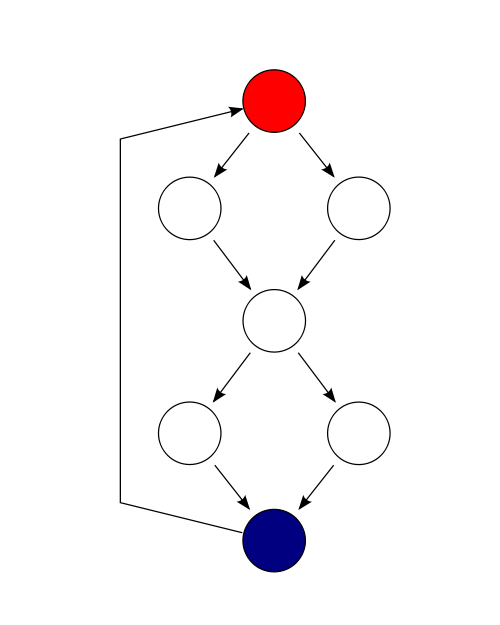
上述控制流图中,有 9 条边,7 个结点,1 个连接,因此它的复杂度为 3。
4.1.3. mccabe¶
mccabe 的名字来源于 Thomas J. McCabe,他于 1976 年在 IEEE 上发表了"A Complexity Measure"这篇论文,这篇重要文章,被其它学术论文引用超过 8000 次,被认为是软件工业领域最重要和最有影响力的论文之一,影响了一代人。33 年之后,Thomas J. McCabe 于 2019 年被 ACM 授予最有影响力论文奖。这个奖一年只授予一次,只有授奖当年 11 年之前的论文才有资格入选,迄今也只颁发了 15 届,约 40 人拿到了这个奖项。
Tom McCabe 提出,如果这个复杂度在 10 以下,该段代码就只是一段简单的过程,风险较低;11-20 为中等风险;21-50 属于高风险高复杂度;如果大于 50,则该段代码是不可测试的,具有非常大的风险。
4.1.4. Flake8 的配置¶
配置 Flake8,可以在根目录下放置.flake8 文件。尽管可以把配置整合到 pyproject.toml 文件中,多数情况下,我们都推荐使用单独的配置文件,以减少 pyproject.toml 的复杂度。对后面将提到的其它工具的配置文件,我们也是一样的态度。
.flake8 是一个 ini 格式的文件,以下是一个示例:
| .flake8 | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
我们排除了对 test 文件进行 lint,这也是 Flake8 开发者的推荐,尽管代码可读性十分重要,但是我们不应该在 test 代码的风格上花太多宝贵时间。这里最初几行配置,是为了与 black 兼容。如果不这样配置,那么经 black 格式化的文件,Flake8 总会报错,而这种报错并无任何意义。
4.2. Mypy¶
Flake8 承担了代码风格、部分语法错误和代码复杂度检查的工作。但是,它没有处理类型检查方面的错误,这项工作我们只能留给 mypy 来完成。
ppw 中已经集成了 mypy 模块,并会在 tox 运行时,自动进行类型检查。看上去,只要我们按照 PEP484 及几个关联的 PEP 来做好类型注解,然后简单地运行 mypy,似乎就应该万事大吉?然而,实践总是比理论要丰富得多,深刻得多。mypy 在运行检查时,常常会遇到第三方库还不支持类型注解的情况,或者因为配置错误,导致 mypy 得不到预期的结果。遇到这些问题时,就需要我们理解 mypy 的工作原理,并且对 mypy 进行一些配置,以便让它能够更好地工作。
Info
为什么 ppw 选择了 mypy?如果你使用 vscode 编程,那么很可能已经使用了 pyright 作为类型检查器。因为 pylance 给出的类型检查错误,都来自于 pyright。那么 ppw 为什么还要推荐另一个类型检查器呢?
这是因为,pyright 并不是一个纯粹的 python 解决方案。要安装 pyright,还必须安装 node。在开发环境下,node 一般只需要安装一次,并且安装 vscode 时,node 也自动安装了。但在由 tox 驱动的矩阵测试环境中,任何非纯 python 的解决方案都可能带来额外的复杂性。
首先,让我们从Any这个特殊的类型说起。Any类型用来表明某个变量/值具有动态类型。在代码中,如果存在过多的Any类型,将降低 mypy 进行代码检查的有效性。
难点在于,Any类型的指定,并不一定来源于我们自己代码中的显式声明(对这一部分,我们可以自行修改,只在非常必要时才小心使用Any)。在 mypy 中,它还会自动获得和传播。mypy 的规则是,在函数体内的局部变量,如果它们没有被显式地声明为某种类型,无论它们是否被赋初值,mypy 都会将其推导为Any。而在函数体外的变量,mypy 则会依据其初值将其推导为某种类型。mypy 这样处理的原因,可能是因为它无法在检查时真正运行这个函数。
我们先看函数体里的变量自动获得Any类型的例子:
| test.py | |
|---|---|
1 2 3 4 5 6 | |
1 | |
Any,因此,我们可以在 x 上调用任何方法,而不会引起 mypy 的错误提示。
下面的例子,揭示了函数体外的变量,mypy 是如何推导其类型的:
1 2 3 4 5 6 7 8 9 | |
Any类型的情况还包括导入错误。当 mypy 遇到 import 语句时,它将首先尝试在文件系统中定位该模块或者其类型桩 (type stub) 文件。然后 Mypy 将对导入的模块进行类型检查。但是,可能存在导入库不存在(比如名字错误、没有安装到 mypy 运行的环境中),或者该库没有类型注解信息等情况,这样,mypy 就会将导入的模块的类型推导为Any。
Info
注意到在第 4 章中,我们生成的样板工程中,在 sample\sample 目录下,存在一个名为 py.typed 的空文件。这个文件会在 poetry 打包过程中,被复制到打包后的包中。这个文件的作用是,告诉类型检查器 (type checker),这个包中的模块都是具有类型注解的,可以进行类型检查。如果你的包中没有这个文件,那么类型检查器将不会对你的包进行类型检查。
py.typed 并不是 mypy 的发明,而是 PEP 561 的规定。所有类型检查器都应该遵循这个规定。
需要注意的是,mypy 寻找导入库的方式与 python 寻找导入库的方式并不完全相同。首先,mypy 有自己的搜索路径。这是根据以下条目计算得出的:
- MYPYPATH 环境变量(目录列表,在 UNIX 系统上以冒号分隔,在 Windows 上以分号分隔)。
- 配置文件中的 mypy_path 配置项。
- 命令行中给出的源的目录。
- 标记为类型检查安全的已安装包(请见 PEP561)。
- typeshed repo 的相关目录。
其次,除了常规的 Python 文件和包之外,mypy 还会搜索存根文件。搜索模块的规则 foo 如下:
- 搜索查找搜索路径(见上文)中的每个目录,直到找到匹配项。
- 如果找到名为的包 foo(即 foo 包含__init__.py 或__init__.pyi 文件的目录),则匹配。
- 如果找到名为的存根文件 foo.pyi,则匹配。
- 如果找到名为的 Python 模块 foo.py,则匹配。

规则比较复杂,不过一般情况下,我们也只需要大致了解即可,在遇到问题时,我们可以通过查阅 mypy 的文档 如何找到导入库 来解决。总之,我们需要了解,如果某个导入库在上面的搜索之后不能找到,mypy 就会将该模块的类型推导为Any。
除了上述获得Any的情况外,mypy 还会自动将Any类型传播到其他变量上。比如,如果一个变量的类型是Any,那么它的任何属性的类型也是Any,并且任何对类型为Any的调用,也将获得Any类型。请看下面的例子:
1 2 3 4 5 | |
从 PEP 484 开始建构 Python 的类型提示大厦,直到 PEP 563 基本完成大厦的封顶之时,仍有大量的第三方库还不支持类型注解。针对这个现实,Python 的类型注解是渐进式的(见 PEP 483),任何类型检查器都必须面对这个现实,并给出解决方案。
Mypy 提供了大量的配置项来解决这个问题。这些配置项既可以通过命令行参数传入,也可以通过配置文件传入。
默认地,mypy 使用工程目录下的 mypy.ini 作为其配置文件;如果这个文件找不到,则会依次寻找.mypy.ini(注意前面多一个'.'),pyproject.toml, setup.cfg, $XDG_CONFIG_HOME/mypy/config, ~/.config/mypy/config,最后是、~/.mypy.ini。
一个典型的 mypy 配置文件包括全局配置和针对特定模块、库的设置,示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
示例中给出的配置项目是我们认为较为重要,并且与默认值不同的那些。关于 mypy 所有配置项目及其含义可以参考 官方文档。这些配置项,既可以通过配置文件设置,也可以通过命令行方式直接传递给 mypy。当然,使用命令行方式传递时,这些配置将在全局范围内发生作用。
下面,我们就对示例中的一些配置项适当展开说明。
4.2.1. disallow_untyped_defs¶
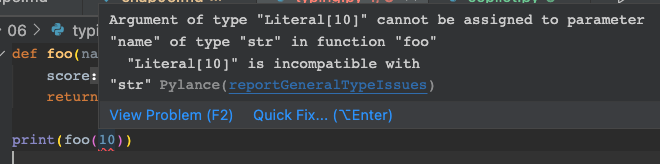
默认情况下,mypy 的类型检查相当宽松,以便兼容一些陈旧的项目。如果我们想要更严格的类型检查,可以将 disallow_untyped_defs 设置为 true。我们可以来测试一下:
| test.py | |
|---|---|
1 2 | |
1 | |
1 | |
1 | |
4.2.2. allow-incomplete-defs¶
在上面的配置中,还存在一个名为 allow-incomplete-defs 的选项,它针对的是函数参数只完成了部分注解的情况。有时候我们需要允许这种情况发生。此时,我们需要 mypy 仅针对个别场合进行以下配置:
1 2 3 | |
4.2.3. check_untyped_defs¶
在下面的代码中,我们把字符串与一个整数相加。这显然并不合理。
1 2 | |
1 | |
4.2.4. disallow_any_unimported 和 ignore_missing_imports¶
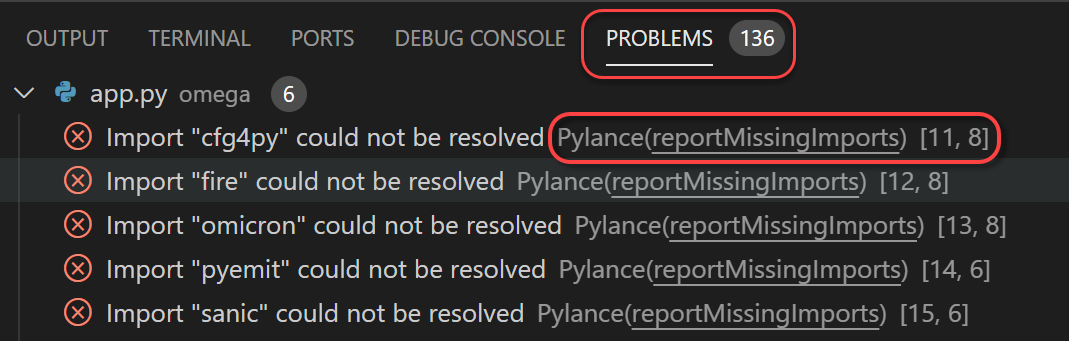
我们在前面介绍过,如果 mypy 无法追踪一个导入库,就会将该模块的类型推断为Any,从而进一步传播到我们的代码里,使得更多的类型检查无法进行。如果我们想要禁止这种情况,可以将 disallow_any_unimported 设置为 True。该参数的缺省值是 false。
一般地,我们应该在全局范围内将 disallow_any_unimported 设置为 True,然后针对 mypy 报告出来的无法处理导入的错误,逐个解决。在 ppw 生成的项目中,如果我们选择了 fire 作为命令行工具,则会遇到以下错误:
1 | |
fire,如果 pypi 上存在它的存根库,则它的名字一定是types-fire,于是我们可以这样纠正上述问题:
1 | |
fire.pyi文件,然后将它放到项目的根目录下。关于如何写.pyi 文件,请读者自行搜索。
但如果既找不到合适的存根库,我们也没时间来写 pyi 文件,那么,我们可以将 ignore_missing_imports 设置为 True,这样 mypy 就不会报错了。请参考上面的配置文件中的第 24~26 行,不过,我们应该尽力避免使用这个选项。
4.2.5. implicit_optional¶
如果有以下的代码:
1 2 | |
arg的类型推导为 Optional[str]。这个推导本身没有错,但是,考虑到 zen of python 的要求, explicit is better than implicit,我们应该将 arg 的类型声明为arg: Optional[str]。从 0.980 起,mypy 默认将 implicit_optional 设置为 Flase(即禁止这样使用),因此,这个选项也没有出现在我们的示例中。
4.2.6. warn_return_any¶
一般情况下,我们不应该让函数返回类型为Any(如果真有类型不确定的情况,应该使用泛型)。因此,mypy 应该检查这种情况并报告为错误。但是,mypy 的缺省配置并不会禁止这种行为,我们需要自行修改。
为了便于理解,我们给出以下错误代码:
1 2 3 4 5 6 7 | |
1 | |
4.2.7. show_errors_codes and warn_unused_ignores¶
当我们使用了 type ignore 时,我们一般仍然希望 mypy 能够报告出错误消息(但不会使类型检查失败)。这可以通过设置 show_errors_codes = True 来实现显示错误代码。这对于理解错误原因很有帮助。
随着代码的不断演进,有时候 type ignore 会变得不再必要。比如,我们依赖的某个第三方库,随着新版本的发布,补全了类型注解。这种情况下,针对它的 type ignore 就不再必要。及时清理这些陈旧的设置是一种良好习惯。
4.2.8. inline comment¶
我们还可以通过在代码中添加注释来控制 mypy 的行为。比如,我们可以通过在代码中添加# type: ignore来忽略 mypy 的检查。如果该注释添加在文件的第一行,那么它将会忽略整个文件的检查。如果添加在某一行的末尾,那么它将会忽略该行的检查。
一般我们更倾向于指定忽略某个具体的错误,而不是忽略整行检查。其语法是 # type: ignore[<error-code>]。
5. Formatter 工具¶
Formatter 工具也有很多种,但是我们几乎没有去考查其他的 formatter,就选择了 black,只因为它的 logo:

与其它 Formatter 工具提供了体贴入微的自定义配置不同,Black 坚持不让您做任何自定义(几乎)。这样做是有道理的,允许定制只会让团队陷入无意义地争辩当中,而风格并无对错,习惯就好。我们常常看到在团队里,一些人为代码风格争论,其实他们反对的并不是某种风格本身,他们只是在反对自己的同事而已。
当然 Black 还是开了一个小窗口,允许你定义代码行的换行长度,Black 的推荐是 88 字符。有的团队会把这个更改为 120 字符宽,按照阴谋论的观点,幕后的推手可能是生产带鱼屏的资本力量。
在 ppw 生成的项目中,我们把 black 的设置放在 pyproject.toml 中:
| pyproject.toml | |
|---|---|
1 2 3 | |
另外一个值得一提的工具是 isort。它的作用是对代码中的 import 语句进行格式化,包括排序,将一行里的多个导入拆分成每行一个导入;始终把导入语句置于正式代码之前等等。通过 ppw 向导生成的项目,这个工具也开箱即用的:
| pyproject.toml | |
|---|---|
1 2 | |
比较遗憾的是,在 vscode 下没有一个好的工具可以自动移除没有使用的导入。Pycharm 是可以做到这一点的。开源的工具中有可以做到这一点的,但是因为容易出错,这里也就不推荐了。
在 vscode 中,Lint 工具可以检查出未使用的导入,然后您需要手动移除。移除未使用的import是必要的,它可以适当加快程序启动速度,降低内存占用,并且避免导入带来的副作用。
Tips
导入不熟悉的第三方库可能是危险的!一些库会在全局作用域加入一些可执行代码,因此当你导入这些库时,这些代码就会被执行。
6. pre-commit hooks¶
我们把 pre-commit hooks 放在这一章里,是因为高效的编码也必须是正确的编码。有时候我们会觉得国内的公司不需要计划和文档,需求、设计和编码各方之间不需要反复协商和沟通,一个指令下来,就很快得到执行。这被认为是执行力强,是一大体制优势,但这些“执行力”强的公司,却往往又累得要死。方向不正确,累死又有何益?
pre-commit 是一个 python 包,可以通过 pip 安装:
1 | |
如果使用向导生成项目的话,向导已经为您安装了 pre-commit hooks, 当您运行git commit命令时,就会看到这样的输出:
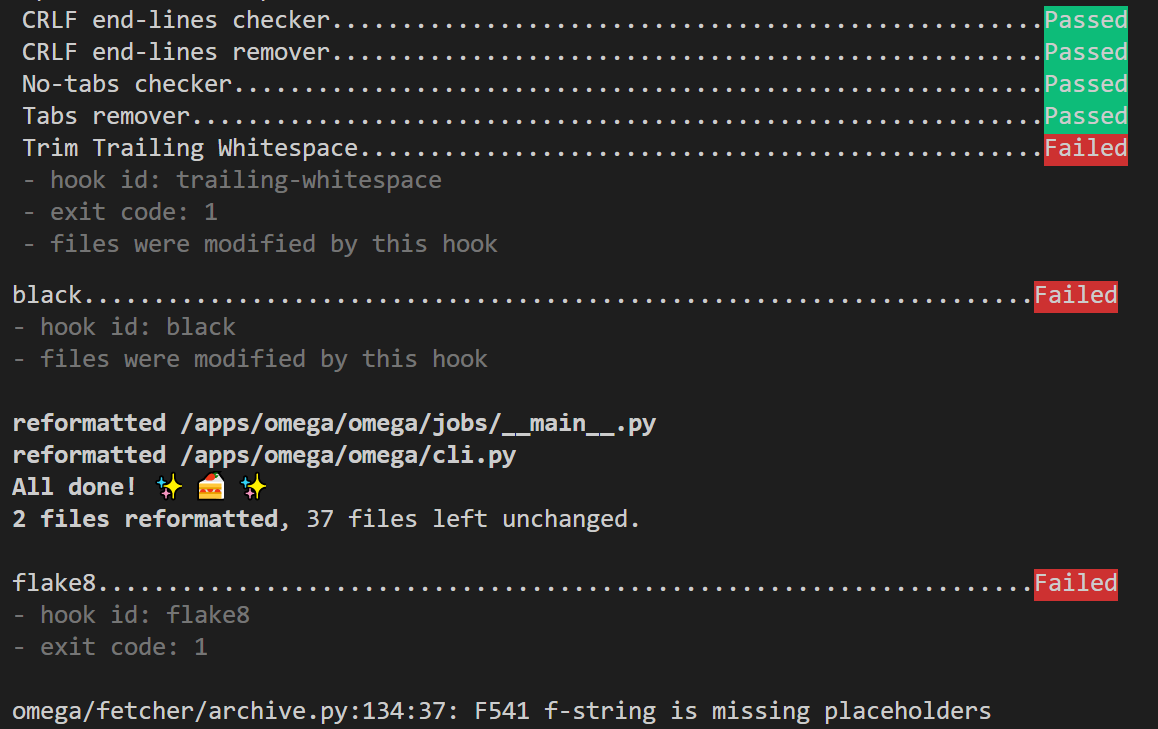
可以看出,pre-commit hooks 对换行符进行了检查和修复,调用 black 进行了格式化,以及调用 Flake8 进行了查错,并报告对 f-string 的错误使用。
一旦错误出现,您必须进行修复后,才能再次提交。
在 ppw 生成的项目中,我们已经集成了这些配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | |
其次,它禁止在文件中使用 tab 键,并且将 tab 键替换为空格。从语法上看,只要不混合使用 tab 键和空格键,这两种方式都是可以的。但是,不同的编辑器(特别是 unix/linux 下)在对文件进行视觉呈现时,会将 tab 键展开成不同的宽度,这使得同一份文件,在不同的编辑器里,看上去并不一致,而如果使用 space,则不会有这个问题。此外,只使用空格还有另外一个好处,就是赚钱更多:根据 stackoverflow 对 2.8 万名专业开发者(排除了学生)的调查,使用空格的开发者的薪资总体上要比使用 Tab 键的开发都高 8.6%。这项报告发表在 stackoverflow 的 2017 年 6 月 5 日的 博客。这当然是属于程序员的幽默,您可以当真,也可以不必当真。
需要注意的是,并非所有的文件中的 tab 键都需要被替换。典型的例子是在 csv 文件中,我们可能使用 Tab 键作为字段之间的分隔符,因此它们必须被保留。在上述配置中,我们已经将 csv 文件排除在外了。
第二组仍然是 pre-commit 提供的开箱即用的钩子。它首先移除了行尾的多余的空格。关于为什么要移除行尾多余的空格,在 PEP8 中有简要地说明。然后它检查是否存在未完成合并的代码文件,检查 yaml 文件是否合乎规范。
注意到这里有一个 end-of-file-fixer 钩子,这个钩子的作用是,在文件末尾添加一个仅含换行符的空行。相信很少有人真正理解它的含义。实际上,相关的问题在 quora 和 stackoverflow 上有很多提问,答案也莫衷一是。
其中一个说法是,POSIX 标准中,对一行文本的定义就是零个或多个非换行符加上终止换行符的序列。因此,如果一行文本不以换行符结尾,它就可能被各种工具当成二进制文件。但这并不能解释为什么我们需要给文件末尾添加一个空行。
作者更倾向于这种观点:这主要是为了照顾使用 Unix 和 Linux 的人。如果你用 vi 打开一个文件,想在后面添加一些新的内容,如果该文件以一个空行结尾,那么 Ctrl+G 就可以直接跳转到文件结尾,立即开始工作。反之,Ctrl+G 只能跳到最后一行的开头。
另外一个原因是,如果你想使用 cat 拼接几个文件文件,如果文件都不是以空行(带换行符)结尾的,那么前一个文件的最后一行将会与后一个文件的第一行混合在一起,而不是像期待的那样,各占一行。
在文件尾加上一个空行并不是什么重要的功能,只是 unix/linux 生态圈里几乎所有的工具都是这么运作的。我们尊重这个习惯就好。
接下来都是在 pre-commit 中调用第三方工具实现相关功能的配置。我们配置了 isort,black, Flake8 和 mypy。
mypy 的配置有点与众不同。它没有使用远程的 repo,而是使用了 local。mypy 官方并没有提供与 pre-commit 的集成,所以我们采用了直接在 pre-commit 中调用本地 mypy 命令的方法。
这一章的主题是高效编码。我们先是介绍了代码自动完成工具,然后讲述了如何利用语法检查工具尽早发现并修复错误,避免把这些错误带入到测试甚至生产环境中。在我们介绍的方案中,语法检查是随着您的 coding 实时展开的,并在向代码库提交时,强制执行一次检查。后面您还会看到,在运行测试时,还会再做一次检查,通过这样分层式的设防与检查,帮助您的项目避免出现重大错误。