二十四课内容详情
Table of Content
共 40 万字,461 段超过 7000 行代码(另有若干策略代码作为福利赠送,未计入),这门课用一句话介绍:涵盖了量化交易全流程、学完就能进入实战的课程。
这门课程共分六个部分,24 个章节。下面是各个部分及章节主要内容介绍,也透露出我们在选题与课程编排方面的考虑:
一、 数据从何而来¶
量化交易的前提是要有海量的可靠数据。
在数据源的选择上,机构投资者选择的金融终端主要有东方财富 Choice、Wind 资讯金融终端,数据源(库)供应商主要有 Wind 资讯、恒生聚源、朝阳永续、天软、巨潮、天相、巨灵、国泰安、通联等。朝阳永续在分析师一致预期、盈利预测数据以及私募基金数据方面占据优势。天软科技在高频行情数据上比较突出。国泰安数据库主要为学术用途其中公司金融数据较为完善。
个人及小型私募投资者主要使用的数据源有 tushare,akshare,jqdatasdk,qmt 等等。这也是这部分课程主要要介绍的内容。
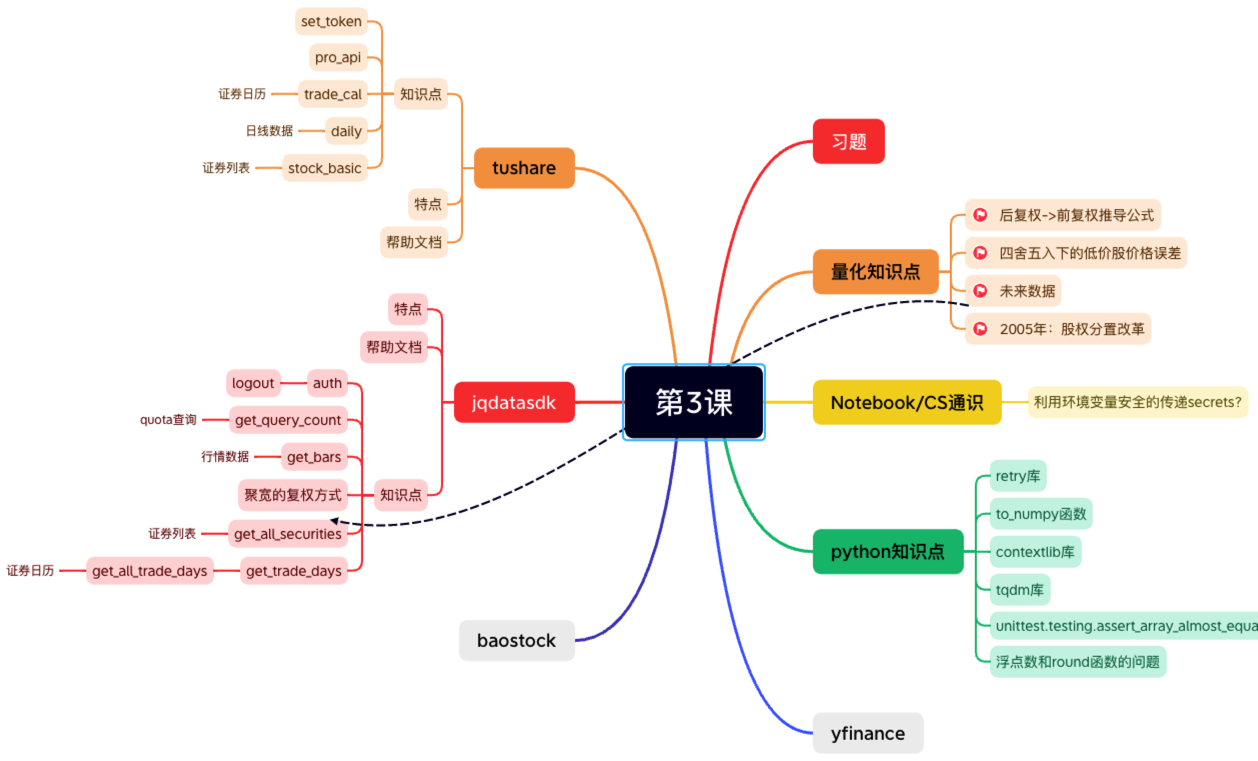
这一部分总共 5 课时。我们会重点介绍 akshare, tushare, jqdatasdk 和 omicron -- 这是大富翁框架自带的数据 sdk。也会提及 yfinance 和其它一些数据源。我们会告诉你哪些能用,哪些现在不能用了,以免耽误时间。
帮大家省时间,是本课程重要目标之一。 我们相信,即使没有我们这门课,您也可能自己拼湊一个量化教程出来,只不过可能要花很久才能找到正确的方向,会失去先发优势。
在介绍每一个数据源时,我们将介绍它的 API 风格,文档风格,API 归类,具体介绍如何实现获取交易日历、证券列表和行情数据。每个数据源都会提供几十个甚至更多的 API,所以归类介绍很重要。掌握每个框架的 API 风格和文档帮助之后,进行探索就是再容易不过的事儿了。
考虑到讲述量化课程时,如果让学员自己去购买数据(免费数据存在种种限制)似乎不太合理;但如果没有数据,很多程序也没法演示:为了确保更好的体验,我们构建了一个量化环境,提供实时行情和历史行情数据(约 40 亿条)和回测平台供大家使用。这就是为什么我们要介绍 omicron -- 很报歉我们在 2019 年时,取了这么个名字,这个名字火遍了全球,但我们还没有。
此外,这部分课也是整个系列中,打基础的部分。我们会介绍跟数据处理密切相关的知识,比如证券代码编码、交易所编码、复权、金融数据处理中的四舍五入问题。这里会涉及到一些看似简单,绝大多数人没有在意或者思考过,但却十分重要的问题:
你平常使用的四舍五入方法,是正确的吗?
你可能从来没想过这个问题。不就是用 math.round 嘛。难道这还会有错?但是你一定知道,四舍五入出错的后果:对于 2 元以下的低价股,四舍五入可能带来 1 分钱的误差,相当于至少 0.5 个百分点!
这还不是舍入误差惟一的影响。实际上,它还会从微观结构上,影响到价格自由度,影响到委买委卖的分布。感兴趣的读者,尤其是做高频的同学可以参考 Is Stock Price Rounded for Economic Reasons in the Chinese Markets 这篇论文,了解下整数价格、吉祥数字在 A 股价格中的特殊作用,以及通过参考文献发现在全球市场上的类似规律。
现在告诉你,Python 的实现真的错了!
一些量化教程建议不要使用前复权,而是使用后复权。我们会让你重新思考这个问题。当我们揭示前复权与后复权之间,只是一个线性变换关系之后,也许你会思考得更深入一些:因为你知道,线性变换不产生任何新的知识,那么前复权与后复权究竟有何区别?
在这一部分,我们还会向你揭示数据的价值。我们会介绍投资者人数、指数的 PE 值等数据如何获取,并且它们是如何与沪指的涨跌相关的,这对于我们进行大周期上的择时比较有帮助。
有一些库非常有用,也写得挺好。但软件也是一门充满遗憾的技术。我们也会对某些开源软件提供改进建议。如果你正在寻找如何在开源量化软件上做出贡献,也许你可以从我们的这些建议出发,帮助他们完善。
二、初识策略¶
我们用三个课时,从三个维度介绍了三个策略。我们把策略安排在第二部分,一方面上完第一部分的课,有的同学可能已经跃跃欲试了;更重要的是,这些策略会从不同的角度向我们展示,做好一个策略究竟需要哪些技能,帮助理解后面的课程为什么这样编排。
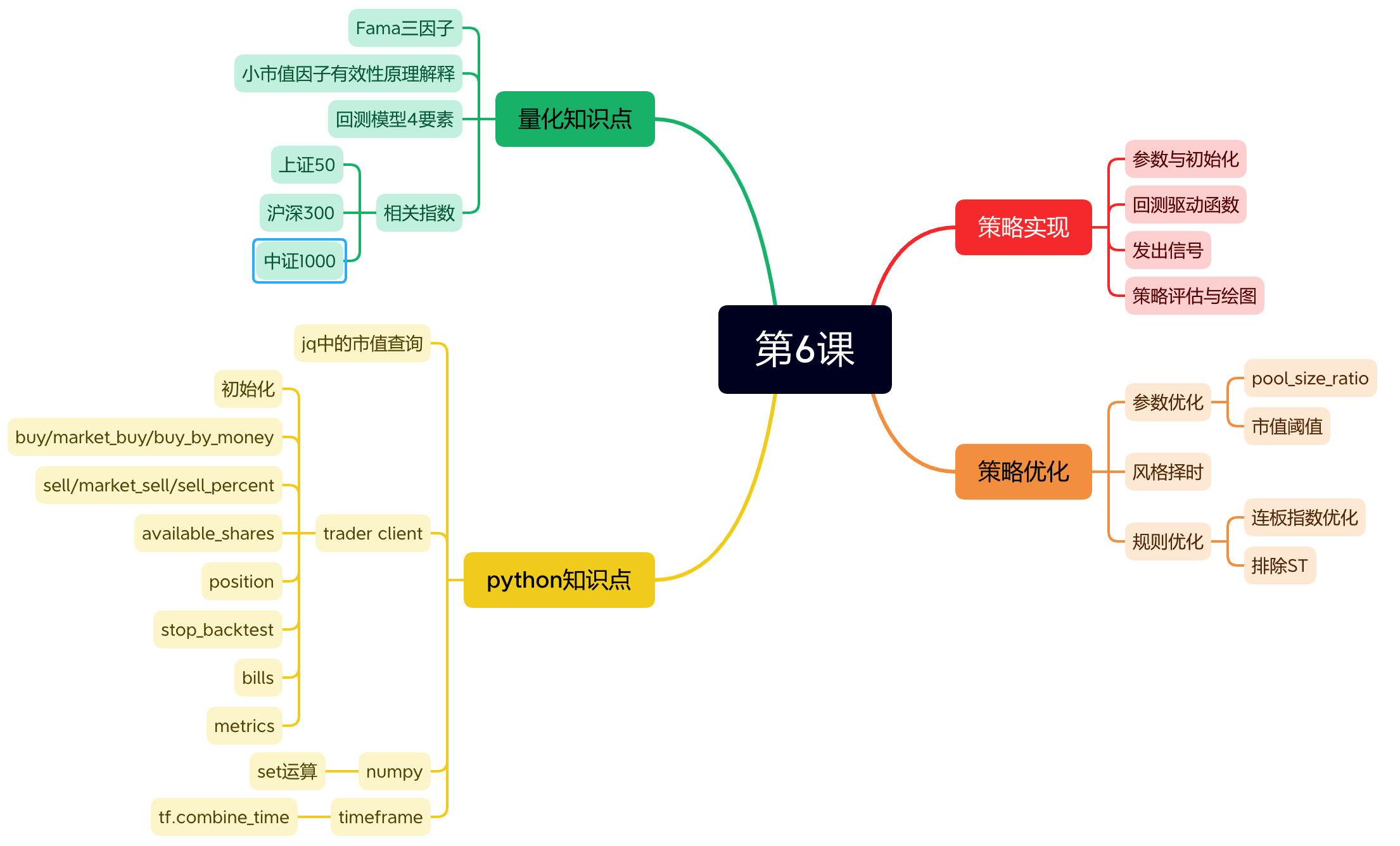
第 6 课,我们介绍了一个小市值策略,这是基本面维度。小市值因子是 Fama(又称 FF) 三因子。该因子的有效性得到了华尔街数十年的验证,在 A 股 2017 年之前也是非常有效,此后进入阶段性有效、阶段性失效的状态。这节课解答了这样几个问题:
- 一个最简单的策略,它至少要实现哪些功能?
- 回测结束,如何将资产曲线和策略指标绘制出来?
- 优化策略应该从哪些方向入手?
这节课的代码都是短平快的,容易理解,没有技巧。但是我们留下一道作业题,如何将策略和回测中的公共部分抽象出来,形成可复用的框架?
Easy saying than done. 当你自己手作过一次之后,对量化的理解一定会更深入一个层次。在第 19 课我们开始讲 backtrader 这样复杂的回测框架时,你就应该能很快进入状态,也能理解这样的问题:
为什么我的策略总是回测吃肉、实盘吃土?
这不一定是你的错。回测框架有他自己的选择和难处,没有开发过回测框架的人不知道,更不可能讲给你听。但如果你不了解自己的武器的缺陷,如何确保它们在战场上一定能打响?
第 7 课,我们介绍布林带策略。这是技术分析维度。布林带只使用了最简单的统计理论 -- 正态分布的一些特性,现在我们已不太会单独使用它了;但它作为一个单一策略,曾经大放异彩,成就了一家创业公司。而且正态分布原理是统计和金融数据分析中绕不过去的知识点。
技术分析(广义来讲,即除开基本面分析和宏观择时之外)是 A 股中等及以下规模资金最有效的策略方法。我们从最新一期的华泰金工的研报(2023 年 8 月)可以看出,7 月最有效的因子仍然是反转因子、波动率因子,小市值因子排第三,这仍然是一个技术为王的时代。
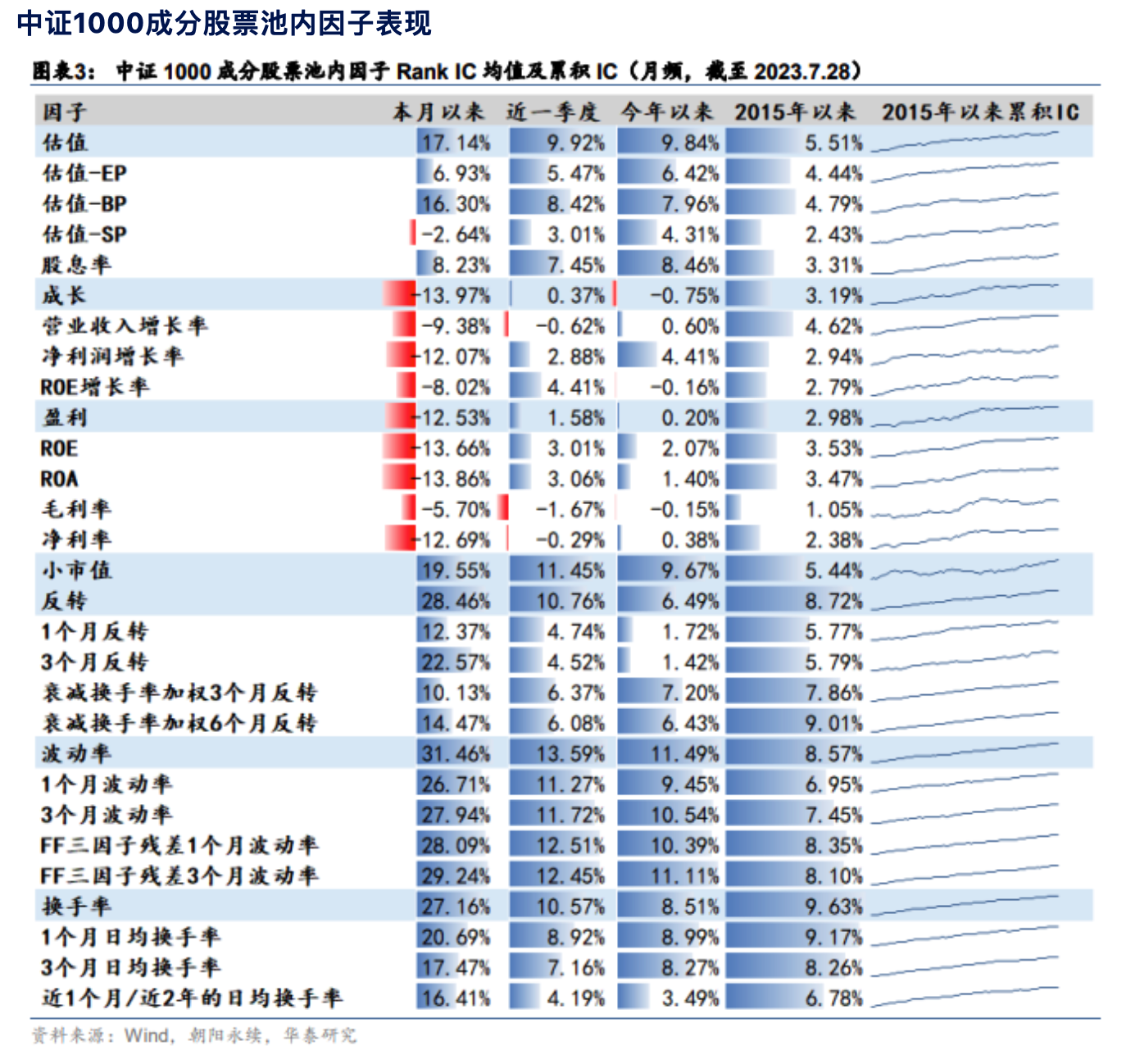
这些因子表现数据揭示了策略研究的大致方向,你应该有更好的方法去寻找反转、吃透波动。如果对这些因子的实现感兴趣,你可以在我们的《因子分析与机器学习策略》课程中找到答案。
第 8 课,我们介绍网格交易法,这是不需要策略的策略,是从交易维度构建策略。它充分体现了量化的优势:避免情绪化操作,严格按纪律执行,即使没有策略,也很有可能实现盈利。
当你有了一张渔网时,重要的是知道该在哪儿撒网。 网格交易成功的前提是,股价在区间内长期横盘。我们提示了什么样的情况下、或者什么样的标的容易产生长期横盘。这既有基于行为金融学原理得出的结论,也有基于交易规则得到的答案。而学完后面的课程,你将有能力通过程序来发现这样的标的。
三、 Python 量化交易数据分析¶
第 9 课将介绍 Numpy 和 Pandas,它们一般是作为量化交易的基础数据结构,同时我们也有大量的操作需要 numpy 和 pandas 来完成。
预测涨跌是困难的,但在某些极端场合下则是可能的。比如,上证已经出现了 7 连阳,明天上涨和下跌的概率是多大?这个时候预测下跌,将会有有很大概率正确。我们先放弃这个概率计算问题,回到一个最简单的问题上来,如何通过程序检测出某个标的当前出现了 N 连阳?
几乎每个能写程序、又略懂证券的人都能实现这个功能。但你需要实现得更好,比如,不使用循环,只用一行代码,并且把过去几年所有 N 连阳一次找出来。.. 速度是非常重要的。因为即使你每日只做一次交易,在收盘前进行调仓换股,那么实际上你只有 14:56 到 14:58 这样两分钟左右的时间,把市场上所有品种遍历一次(并且进行策略计算),你的程序最好得快点,实践表明,这并不容易。
这一课里,我们把常用量化框架中高频出现的 numpy 函数几乎都讲了一遍,这部分的习题也比较有技巧,掌握它们,快速成为 Numpy/Pandas 高手!
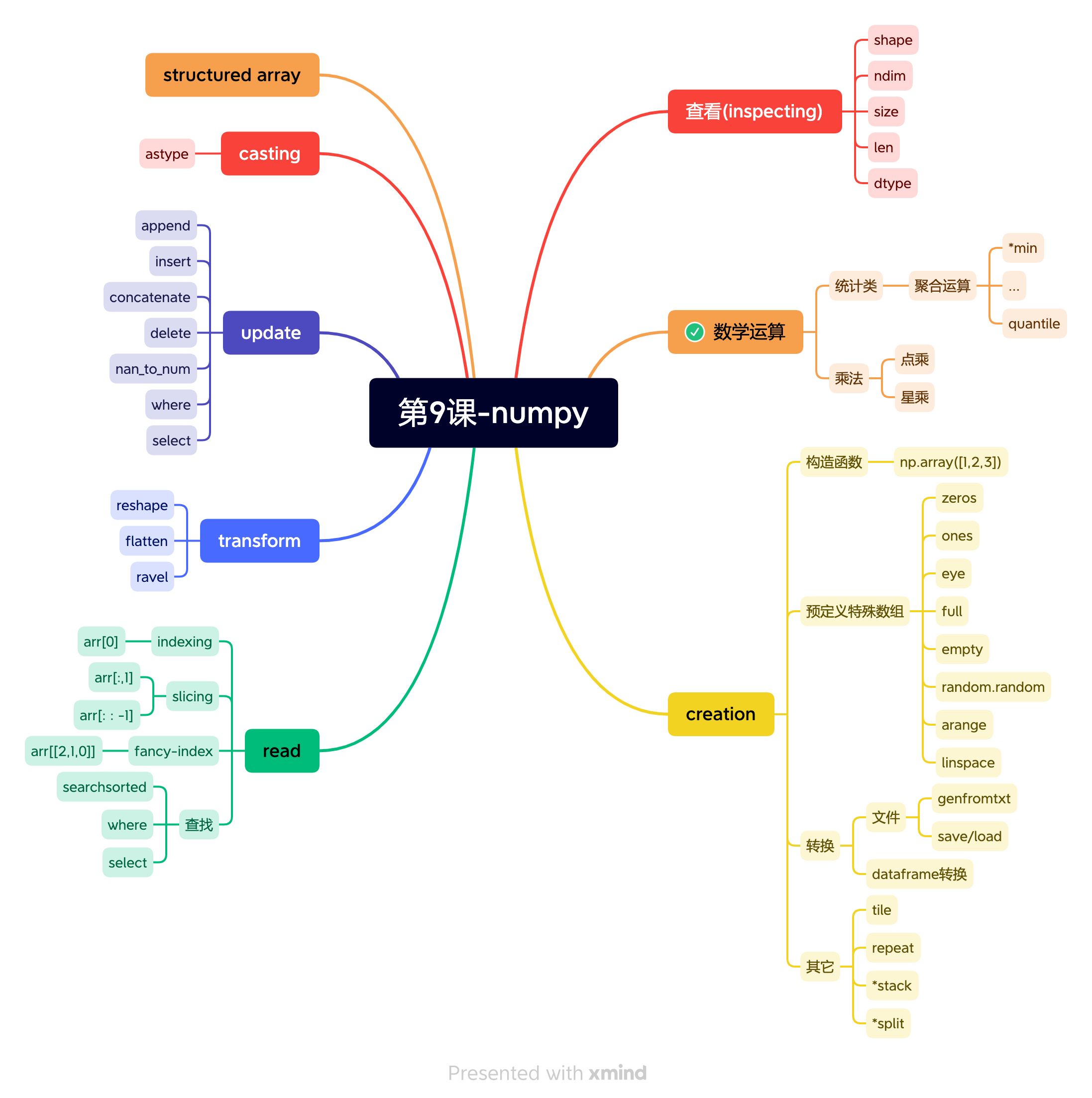
第 10 课我们介绍 talib,这是最重要的技术分析库之一,很多量化框架都集成了它。
第 11 课和第 12 课,我们介绍了一些统计知识。你很快就会看到它们的巨大威力!
这两课当中,我们验证了沪指究竟服从什么概率分布这一基础性问题 ,也回答了“如果上证指数下跌 4%,能抄底吗?”这样的问题。更多的类似问题,相信学完后,你自然能探索和解答了。
很多人认为,概率的东西比较难理解,比如象 pdf(概率密度函数)/cdf(累积分布函数)这样的概念就是。但我们从直方图讲起,再设想直方图的每个分箱大小趋近于 0,这样就得到了 pdf,相信如果这么讲,加上无数的图和代码,概率和统计也没那么难理解?
结合我们之前学过的知识,我们已经可以进行一些比较有难度的 k 线形态检测了。这就是第 13 课的主要内容 -- 技术形态分析。
K 线形态检测在一个散户为主的市场中非常有用,它是将波浪理论程序化执行的基础。短线交易的本质是筹码,任何上涨和下跌都必然落入有限的几种范式当中,因此,k 线形态检测,即使不能用来做预测,也能用来做事后确认。
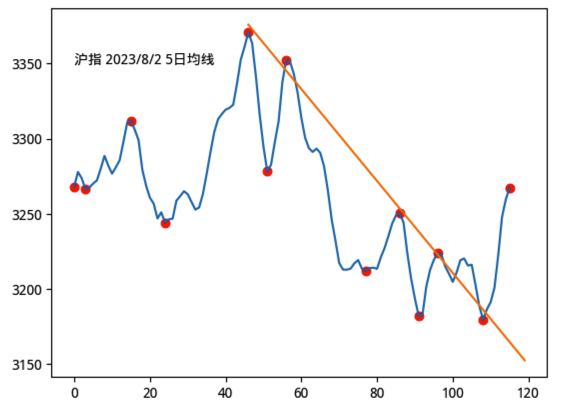
这一课中我们给出了一个完全自适应的检测顶底的方法:基于概率分布理论,有坚实的数学基础。
红点这是我们使用自适应算法检测顶底的结果,基于这些顶和底,我们进行了支撑线和压力线的测算。当事实摆在我们面前时,你不得不承认,画线派有时确实在 A 股掌控了市场:
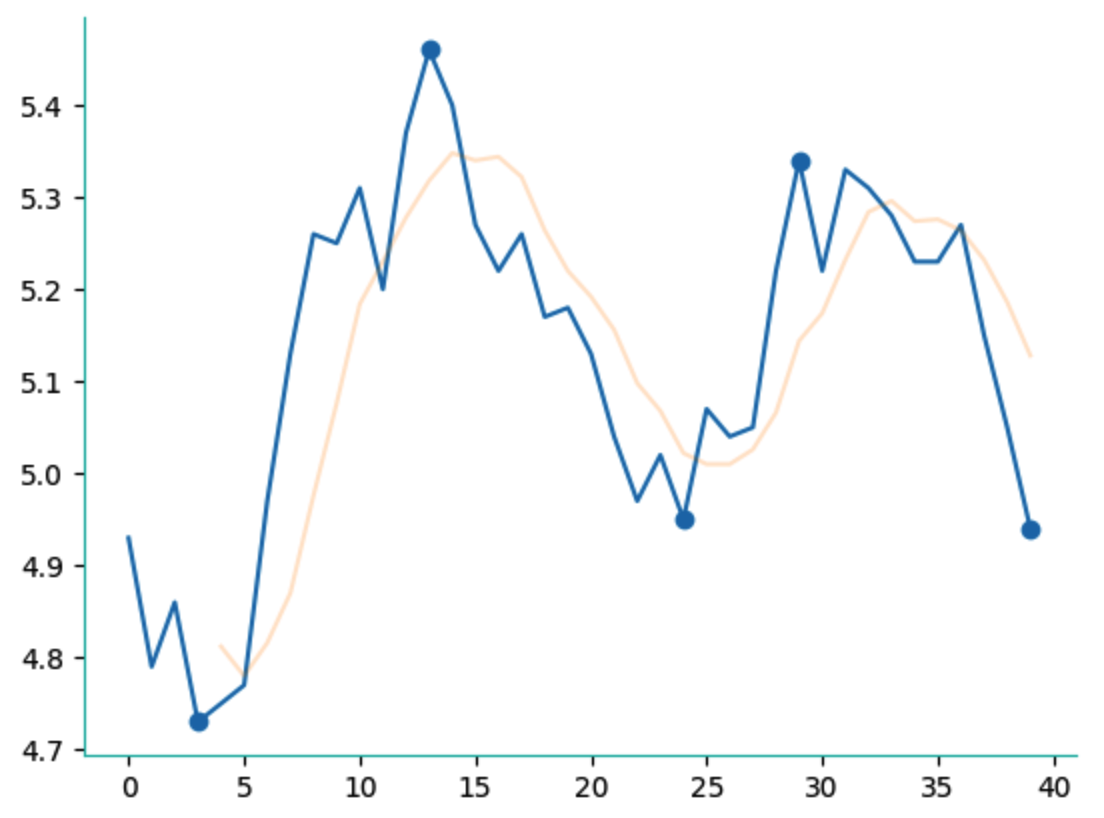
我们当然可以运用它来做更多的事情,比如检测 M 头和 W 底:
或者平台整理突破(这里我们把机器学习里的二维聚类算法移植到了一维时间序列上):
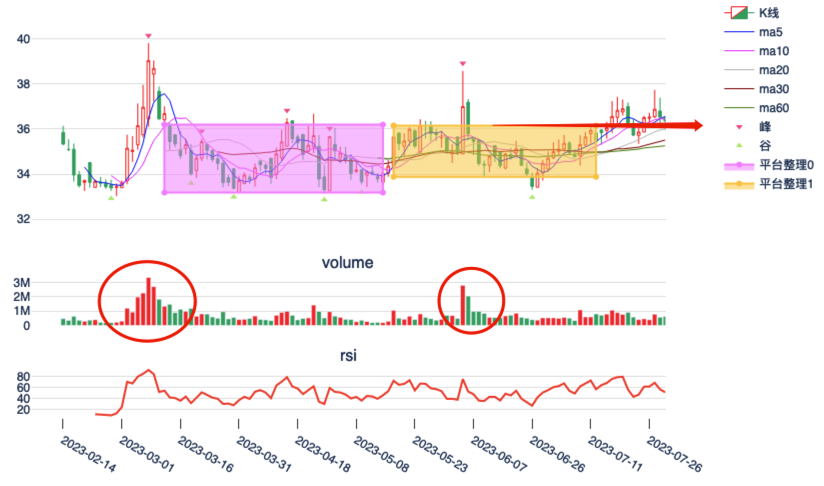
还有智能 RSI 的原理和算法,等等。
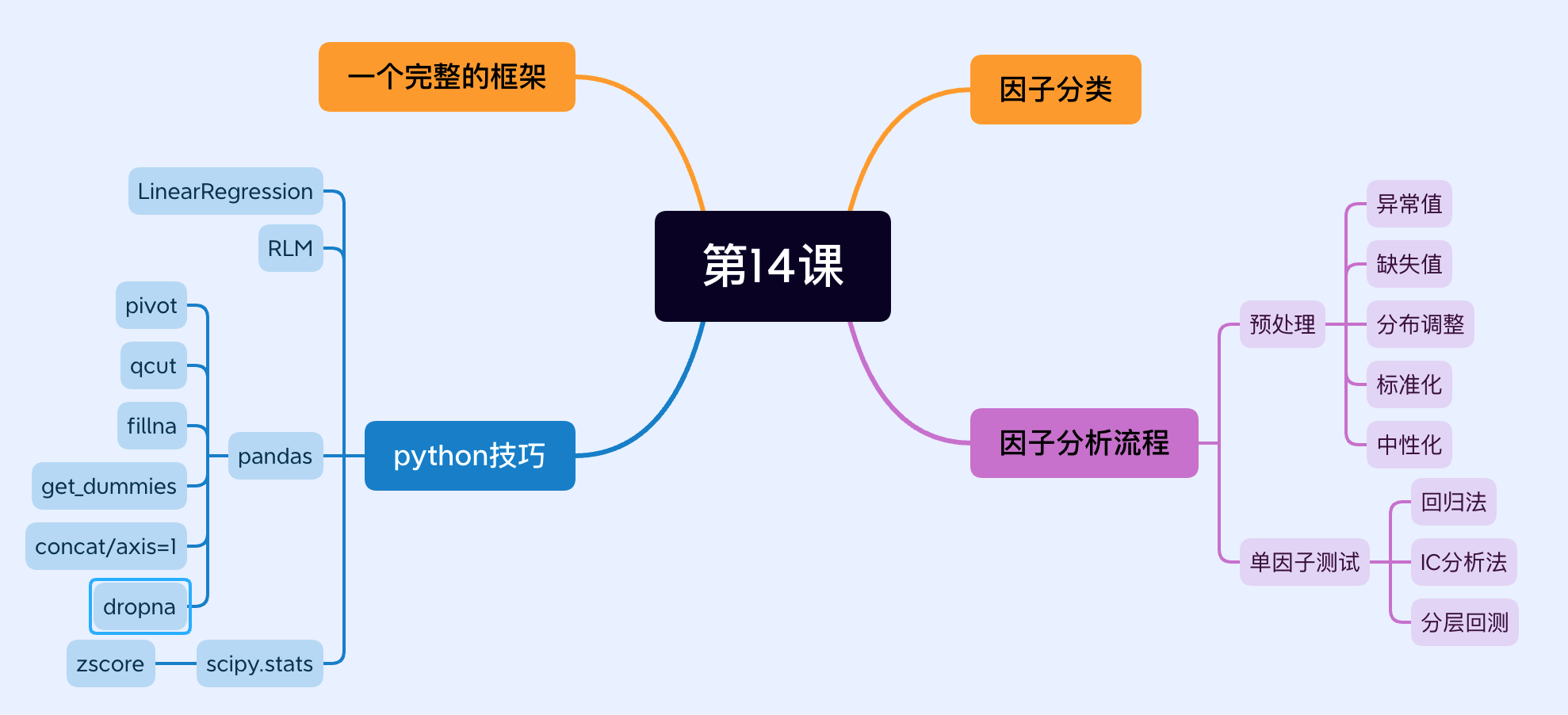
如果你学习课程的目标是为了换工作,那么第 14 课的内容--因子分析不可或缺。我们详细介绍了因子分析的方方面面:回归、IC 和分层,从原理到实现。
当你走完了因子分析的全流程,已一览大部分细节和框架之后,第 15 课把你带到了 Alphalens 面前。现在,学习 Alphalens 应该轻松许多,因为你已经知道它是什么,要干什么。
Info
Alphalens 是 Quantpian 开发的 pyfolio 库中的一部分。Quantpian 曾经是全球最大的开源 Quant 社区,它的成功,也推动了国内如聚宽, bigquant 等创业公司的发展。如今,Quantpian 已成为历史,Alphalens 已成为量化遗产,还没有新的维护者,如果你擅长程序开发,那么,在学完这门课程,掌握了足够的领域知识,也可能成为它的维护者,许这也是你可以取得成就的地方!
四、 数据可视化¶
第 16 课到第 18 课我们专注于可视化。
绘图不仅仅为了创造美丽的可视化效果,更是为了释放数据的全部潜力,并揭示原本隐藏的 insights,它是数字语言和故事语言之间的桥梁,使得个人和组织能够做出有明智的决策,并创造有意义的变革。
在量化交易中,我们固然以自动化程序为主,但仍然在因子探索、生成回测报告、算法研究等方面,借助我们的直觉。这种直觉正是来自于图形。
我们在课程中向大家介绍 matplotlib,plotly, seaborn 和 pyecharts 这些绘图界的超级明星们。同时,坚持本课程一以贯之的理念,解剖了绘图框架、部分还原了引擎盖下的运行机制,从而使得你在面临新的框架和新的问题时,决不会茫然无措。
五、 策略与回测¶
第 19 课和第 20 课,我们介绍 backtrader, 当下最流行的纯回测框架。
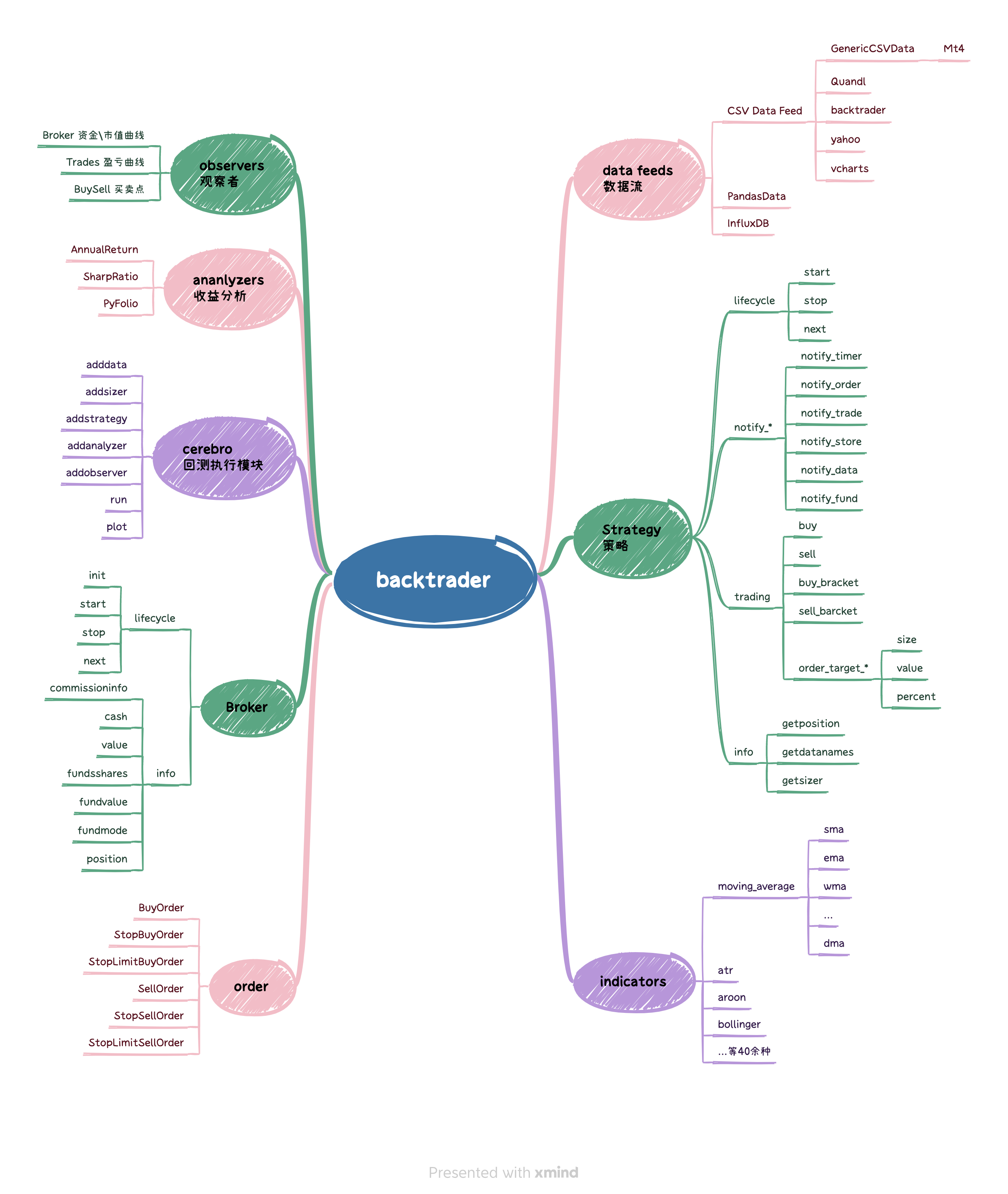
第 21 课,在能够熟练地进行回测之后,我们来学习应该如何评价我们的策略。我们会介绍 sharpe 率,sortino, annual return 等等众多指标,它们是如何揭示策略在风险与盈利之间的平衡特性;我们还会介绍一个专业而简单易用的策略评估指标绘图库 - quantstats。
回测就像人生一样,处处充满了陷阱,有一些是框架本身带来的 -- 比如一些框架无法使用真实复权(象 backtrader,如果是在__init__中一次性生成了指标,无论是使用哪种复权数据,你都使用了未来数据!);有一些则是你的策略、计算精度、误用未来函数、分红、交易规则等等带来的。我们将在这一课中,详细介绍这些 pitfall。
我们还会介绍大富翁的回测框架,这不是兜售私货,而是因为像 backtrader 这样的框架,要么避免不了前面提到的回测陷阱,要么你得花很多功夫去改造它。考虑到大富翁是开源的、并且回测框架几乎已经支持了分布式回测 -- 如果我要改动 backtrader,还不如接受大富翁回测框架 -- 如果你的公司正在寻找一款符合 A 股交易规则,能解决复权问题,最好还具有分布式基础 -- 建议你认真学完这一课。
这是第 22 课的内容。
六、 接入实盘¶
第 23 和第 24 课,我们将介绍如何接入实盘交易。你也将从这里离开彩排场,进入现场直播。
我们会介绍没有资金门槛的 easy_trader,和有一定资金门槛的 ptrade,qmt,和东财、华泰量化交易平台。QMT 是迅投推出的量化平台,除了内置策略编辑、回测运行功能之外,它还提供了一个名为 XtQuant 的 Python 库,我们可以使用它提供的数据和交易功能。目前 QMT 是量化程序接入实盘性价比最高的方案。
十年磨一剑,霜刃未曾试。过这么多课程的学习以及练习,我确信,你已经准备好,为自己制造一台印钞机了!