07 代码单元测试
Table of Content
Quote
Testing leads to failure. Failure leads to understanding.
单元测试的概念可能多数读者都有接触过。作为开发人员,我们编写一个个测试用例,测试框架发现这些测试用例,将它们组装成测试 suite 并运行,收集测试报告,并且提供测试基础设施(断言、mock、setup 和 teardown 等)。Python 当中最主流的单元测试框架有三种,Pytest, nose 和 Unittest,其中 Unittest 是标准库,其它两种是第三方工具。在 ppw 向导生成的项目中,就使用了 Pytest 来驱动测试。
这里主要比较一下 pytest 和 unittest。多数情况下,当我们选择单元测试框架时,选择二者之一就好了。unitttest 基于类来组织测试用例,而 pytest 则是函数式的,基于模块来组织测试用例,同时它也提供了 group 概念来组织测试用例。pytest 的 mock 是基于第三方的 pytest-mock,而 pytest-mock 实际上只是对标准库中的 mock 的简单封装。单元测试都会有 setup 和 teardown 的概念,unittest 直接使用了 setUp 和 tearDown 作为测试入口和结束的 API。在 pytest 中,则是通过 fixture 来实现,这方面学习曲线可能稍微陡峭一点。在断言方面,pytest 使用 python 的关键字 assert 进行断言,比 unittest 更为简洁,不过断言类型上没有 unittest 丰富。
另外一个值得一提的区别是,unittest 从 python 3.8 起就内在地支持 asyncio,而在 pytest 中,则需要插件 pytest-asyncio 来支持。但两者在测试的兼容性上并没有大的不同。
pytest 的主要优势是有:
- pytest 的测试用例更简洁。由于测试用例并不是正式代码,开发者当然希望少花时间在这些代码上,因此代码的简洁程度很重要。
- 提供了命令行工具。如果我们仅使用 unittest,则执行单元测试必须要使用
python -m unittest来执行;而通过 pytest 来执行单元测试,我们只需要调用pytest .即可。 - pytest 提供了 marker,可以更方便地决定哪些用例执行或者不执行。
- pytest 提供了参数化测试。
这里我们简要地举例说明一下什么是参数化测试,以便读者理解为什么参数化测试是一个值得一提的优点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
基于以上原因,在后面的内容中,我们将主要以 pytest 为例进行介绍。
1. 测试代码的组织¶
我们一般将所有的测试代码都归类在项目根目录下的 tests 文件夹中。每个测试文件的名字,要么使用 test_.py,要么使用_test.py。这是测试框架的要求。只有这样,在我们执行命令如pytest tests时,测试框架才能从这些文件中发现测试用例,并且组合成一个个待执行的 suite。
在 test_*.py 中,函数名一样要遵循一定的模式,比如使用 test_xxx。不遵循规则的测试函数,不会被执行。
一般来说,测试文件应该与功能模块文件一一对应。如果被测代码有多重文件夹,对应的测试代码也应该按同样的目录来组织。这样做的目的,是为了将商业逻辑与其测试代码对应起来,方便我们添加新的测试用例和对测试用例进行重构。
比如在 ppw 生成的示例工程中,我们有:
1 2 3 4 5 6 7 8 9 | |
这里虽然只有一级目录,但目录里的文件名是一一对应的。注意这里面的__init__.py 文件,如果缺少这个文件的话,tests 就不会成为一个合法的包,从而导致 pytest 无法正确导入测试用例。
2. PYTEST¶
使用 pytest 写测试用例很简单。假设 sample\app.py 如下所示:
1 2 3 | |
1 2 3 4 5 6 | |
2.1. 测试用例的组装¶
在 pytest 中,pytest 会按传入的文件(或者文件夹),搜索其中的测试用例并组装成测试集合 (suite)。除此之外,它还能通过 pytest.mark 来标记哪些测试用例是需要执行的,哪些测试用例是需要跳过的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
然后我们就可以选择只执行标记为 webtest 的测试用例:
1 2 3 4 5 6 7 8 9 10 11 | |
这里的 webtest 是自定义的标记。我们也可以用 pytest 的内置标记来筛选用例: 1. pytest.mark.filterwarnings, 给测试用例添加 filterwarnings 标记,可以忽略警告信息。 2. pytest.mark.skip,给测试用例添加 skip 标记,可以跳过测试用例。 3. pytest.mark.skipif, 给测试用例添加 skipif 标记,可以根据条件跳过测试用例。 4. pytest.mark.xfail, 在某些条件下(比如运行在某个 os 上),用例本应该失败,此时就应使用此标记,以便在测试报告中标记出来。
这些标记可以用 pytest --markers 命令查看。
2.2. pytest 断言¶
在测试时,当我们调用一个方法之后,需要将其返回结果与期望结果进行比较,以判定该测试是否通过。这被称之为测试断言。
pytest 中的断言巧妙地拦截并复用了 python 内置的函数 assert,由于您很可能已经接触过 assert 了,因而使得这一部分的学习成本变得非常低。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | |
有时候我们需要测试错误处理,看函数是否正确地抛出了异常,代码 32~37 演示了异常断言的使用。注意这里我们不应该这么写:
1 2 3 4 5 6 7 | |
2.3. pytest fixture¶
一般而言,我们的测试用例很可能需要依赖于一些外部资源,比如数据库、缓存、第三方微服务等。这些外部资源的初始化和销毁,我们希望能够在测试用例执行前后自动完成,即自动完成 setup 和 teardown 的操作。这时候,我们就需要用到 pytest 的 fixture。
Info
在单元测试中是否需要使用外部资源是一个见仁见智的问题。有的看法认为,一旦引入外部资源,测试用例就不再是单元测试,而是集成测试。时代总在发展,特别是进入容器化时代后,在测试中快速创建一个专属的数据库服务器变得十分快捷和容易,这可能要比我们通过大量的 mock 来进行外部资源隔离更容易,因此我们也没必要于拘泥于这些过去的看法。
假定我们有一个测试用例,它需要连接数据库,代码如下(参见 code/chap07/sample/app.py)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
这个测试显然需要连接数据库,因此我们需要在测试前创建一个数据库连接,然后在测试结束后关闭连接。并且,我们还会有多个测试用例需要连接数据库,因此我们希望数据库连接是一个全局的资源,可以在多个测试用例中共享。这就是 fixture 的用武之地。
fixture 是一些函数,pytest 会在执行测试函数之前(或之后)加载运行它们。但与 unitest 中的 setUp 和 tearDown 不同,pytest 中的 fixture 依赖是显式声明的。比如,在上面的 test_add_user 显式依赖了 db 这个 fixture(通过在函数声明中传入 db 作为参数),而 db 则又显式依赖 event_loop 这个 fixture。但除此之外,即使文件中还存在其他 fixture, 执行 test_add_user 也不会执行这些 fixture,因为依赖必须显式声明。
上面的代码中,我们演示的是对异步函数 add_user 的测试。显然,异步函数必须在某个 event loop 中执行,并且相关的初始化 (setup) 和退出操作 (teardown) 也必须在同一个 loop 中执行。这里是分别通过 pytest.mark.asyncio, pytest_asyncio 等 fixture 来实现的:
首先,我们需要将测试用例标注为异步执行,即上面的代码第 23 行。其次,test_add_user 需要一个数据库连接,该连接由 fixture db来提供。这个连接的获得也是异步的,因此,我们不能使用 pytest.fixutre 来声明该函数,而必须使用@pytest_asyncio.fixture(见代码第 15 行)来声明该函数。
我们还要介绍一下出现在第 8 行和第 15 中的 scope='session'。这个参数表示该 fixture 的作用域,它有四个可选值:function, class, module 和 session。默认值是 function,表示 fixture 只在当前测试函数中有效。在上面的示例中,我们希望这个 event loop 在一次 1 测试中都有效,所以将 scope 设置为 session。
上面的例子是关于异步模式下的测试的。对普通函数的测试更简单一些。我们不需要 pytest.mark.asyncio 这个装饰器,也不需要 event_loop 这个 fixture。所有的 pytest_asyncio.fixture 都换成 pytest.fixture 即可(显然,它必须、也只能装饰普通函数,而非由 async 定义的函数)。
Info
如果我们使用 unittest 来对异步代码进行测试,要注意:首先测试类要从 unittest.IsolatedAsyncioTestCase 继承,然后测试函数要以 async def 定义。并且 setup 和 teardown 都要换成它们的异步版本 asyncSetUp、asyncTearDown。
注意只有从 python 3.8 开始,unittest 才直接支持异步测试。在 python 3.7 及之前的版本中,我们需要使用第三方库 aiounittest。
我们通过上面的例子演示了 fixture。与 markers 类似,要想知道我们的测试环境中存在哪些 fixtures,可以通过 pytest --fixtures 来显示当前环境中所有的 fixture。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
这里我们看到 faker.contrib 提供了一个名为 faker 的 fixture, 我们之前安装的、支持异步测试的 pytest_asyncio 也提供了名为 event_loop 的 fixture(为节省篇幅,其它几个省略了),以及我们自己测试代码中定义的 event_loop 和 db 这两个 fixture。
Pytest 还提供了一类特别的 fixture,即 pytest-mock。为了讲解方便,我们先安装 pytest-mock 这个插件,看看它提供的 fixture。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
可以看到 pytest-mock 提供了 5 个不同级别的 fixture。关于什么是 mock,这是下一节的内容。
3. 魔法一样的 Mock¶
在单元测试时,我们希望测试环境尽可能单纯、可控。因此我们不希望依赖于用户输入,不希望连接无法独占的数据库或者第三方微服务等。这时候,我们需要通 mock 来模拟出这些外部接口。mock 可能是单元测试中最核心的技术。
Note
感谢容器技术!现在单元测试中,越来越多地连接数据库、缓存和第三方微服务了。因为对有一些接口进行 mock 的代价,已经超过了 launch 一个容器,初始化数据库再开始测试了。
无论是 unittest 还是 pytest,都直接或者间接使用了 unittest 中的 mock 模块。所以,当你遇到 mock 相关的问题时,都可以查阅 unittest 中的 mock 文档。我们接下来关于 mock 的介绍,也将以 Unittest 中的 mock 为主。不过,两个框架的 mock,在基本概念上都是相通的。
Info
python 从 3.8 起,才对 async 模式下的 mock 有比较完备的支持。由于 Python 3.7 已经走到生命尽头,所以本书也不介绍 Python 3.7 中, async 模式下的 mock 该如何实现了。
Unittest.mock 模块提供了最核心的 Mock 类。当我们用 Mock 类的一个实例来替换被测试系统的某些部分之后,我们就可以对它的使用方式做出断言。这包括检查哪些方法(属性)被调用以及调用它们的参数是否正确。我们还可以设定返回值或者令其抛出异常,以改变执行路径。
除此之外,mock 模块还提供了 patch 方法和 MagicMock 子类。MagicMock 区别于 Mock 的地方在于,它自动实现了对 Python 中类对象中的魔法函数的 mock(这是它的名字的来源!),魔法函数是指带双下划线的函数,比如__iter__等。patch 则是一个带上下文管理的工具,它能自动复原我们对系统的更改。
Info
实际上,多数时候,我们用到的是 MagicMock 对象,而不是 Mock。
3.1. 基础概念与基本使用¶
最基础的 mock 的概念可以通过下面的代码得到演示:
1 2 3 4 5 6 7 | |
这段代码假设我们有一个被测试类 ProductionClass,当我们调用它的 method 方法时,它有一些不便在单元测试下运行的情况(比如需要连接数据库),因此,我们希望能跳过对它的调用,而直接返回我们指定的一些值。
在这里我们能拿到 ProductionClass 实例对像的引用,所以,我们可以直接修改它的 method 属性,使之指向一个 MagicMock 对象。MagicMock 对象有一些重要的属性和方法。
第 3 行出现的 return_value 是第一个重要的属性。它的意思时,当被替换的对象(这里是 method)被调用时,返回值应该是 3。与之类似的另一个属性是 side_effect。它同样也在 mock 被调用时,返回设置的值。但 return_value 与 side_effect 有重要区别:两者的返回值都可以设置为数组(或者其他可迭代对象),但通过 side_effect 设置返回值时,每次调用 mock,它都返回 side_effect 中的下一个迭代值;而 return_value 只会将设置值全部一次返回。另外,如果两者同时设置,side_effect 优先返回。请看下面的示例:
1 2 3 4 5 6 7 8 9 10 11 | |
输出结果将是:
1 2 3 4 5 | |
我们给 side_effect 设置了 5 个值,在 5 次重复测试时,它分别依次返回下一个迭代值。注意这里我们通过 unittest.mock.DEFAULT,来让其中一次迭代,返回了 return_value 的设置值。当然,本质上,这仍然是对 side_effect 的一个迭代结果。
这里还出现了它的一个重要方法,assert_called_with,即检查被替换的方法是否被以期望的参数调用了。除此之外,还可以断言被调用的次数,等等。
Note
如果你之前接触过其它 mock 框架的话,可能需要注意,python 中的 mock 是action -> assertion模式,而不是其它语言中常见的record -> replay模式。
这个例子非常简单。但它也演示了使用 Mock 的精髓,即生成 Mock 实例,设置行为(比如返回值),替换生产系统中的对象(方法、属性等),最后,检验结果。
很多时候,我们会通过 patch 的方式来使用 mock。以下是在不同场景下使用 patch 的例子。
3.1.1. 作为装饰器使用¶
假如我们有一个文件系统相关的操作。要测试该操作,如果不使用 mock,就必须在测试环境下构建目录,增加某些文件。除非万不得已,一般我们不希望测试会改变我们的文件系统,这是我们应该使用 mock 的地方。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
我们对关键代码进行一些解释。首先,通过装饰器语法进行 mock 时,我们的测试函数会多一个参数(这里是 mocked,但名字可以由我们任意指定)。这里使用多个 patch 装饰器也是可以的,每增加一个装饰器,测试函数就会多增加一个参数。
其次,我们要对 Foo.get_files 进行 mock,但我们在 Foo.get_files 之前,加上了一个__main__的前缀。这是由于类 Foo 的定义处在顶层模块中。在 Python 中,任何一个符号(类、方法或者变量)都处在某个模块(module)之下。如果这段代码存为磁盘文件 foo.py,那么模块名就是 foo;我们在别的模块中引入 Foo.get_files 时,应该使用 foo.Foo.get_files。但在这里,由于我们是同模块引用,因此它的前缀是__main__。
Info
使用 mock 的关键,是要找到被 mock 对象正确的引用方式。在 Python 中,一切都是对象。这些对象通过具有层次结构的命名空间来进行寻址。以 patch 方法为例,它处在 mock 模块之中,而 mock 模块又是包 unittest 的下级模块,因此,我们就使用 unittest.mock.patch 来引用它,这也与导入路径是一致的。
但是,像这里的脚本,如果一个对象不是系统内置对象,又不存在于任何包中,那么它的名字空间就是__main__,正如这里的示例__main__.Foo 一样。关于寻址,还存在其他的情况,我们会在后面介绍 builtin 对象以及错误的引用那两节中进行介绍。
通过装饰器语法传入进来的 mock 对象,它的行为是未经设置的。因此,我们要在这里先设置它的返回值,然后再调用业务逻辑函数 foo.get_files -- 由于它已经被 mock 了,所以会返回我们设置的返回值。
3.1.2. 在块级代码中使用¶
当我们通过装饰器来使用 patch 时,它的上下文是函数级别的。在函数退出之后,mock 对系统的更改就复原了。但是,有时候我们更希望使用代码块级别的 patch,一方面可以更精准地限制 mock 的使用范围,另一方面,它的语法会更简练,因为我们可以一行代码完成 mock 行为的设置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
在实践中,使用 mock 可能并不像看起来那么容易。有一些情景对初学者而言会比较难以理解。而一旦熟悉之后,你就会发现,你对 Python 的底层机制,又有了更深入的理解。下面,我们就介绍在这些场景下如何使用 mock。
3.2. 特殊场合下的 mock¶
3.2.1. 修改实例的属性¶
前面的例子中,我们给 patch 传入的 target 是一个字符串,显然,在 patch 作用域内,所有的新生成的对象都会被 patch。如果在 patch 之前,对象已经生成了,我们则需要使用patch.object来完成 patch。这样做的另一个好处是,我们可以有选择性地 patch 部分对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
在 bar 方法里,两个 logger(root_logger 和'sample.core.foo'对应的 logger) 都被调用,但在测试时,我们只拦截了前一个 logger (第 2 行)的info方法,结果验证它被调用,且仅被调用一次。
这里要提及 pytest 中 mocker.patch 与 unitest.mock.patch 的一个细微差别。后者进行 patch 时,可以返回 mock 对象,我们可以通过它进行更多的检查(见上面示例代码中的第 11 行);但 mocker.patch 的返回值是 None。
这里要提及 pytest 中 mocker.patch 与 unitest.mock.patch 的一个细微差别。后者进行 patch 时,可以返回 mock 对象,我们可以通过它进行更多的检查(见上面示例代码中的第 15 行);但 mocker.patch 的返回值是 None。

3.2.2. 异步对象¶
从 3.8 起,unittest.mock 一般就不再区分同步和异步对象,比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
原函数 bar 的返回值为空。但输出结果是 "hello from async mock",说明该函数被 mock 了。
被 mock 的方法 bar 是一个异步函数,如果我们只需要 mock 它的返回值的话,仍然是用同样的方法,直接给 return_value 赋值就好。如果我们要将其替换成另一个函数,也只需要将该函数声明成为异步函数即可。
但是,如果我们要 mock 的是一个异步的生成器,则方法会有所不同:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
理解这段代码的关键是,bar 方法是我们要 mock 的对象,它的返回值(即 mocked.return_value)是一个 coroutine。我们需要对该 coroutine 的__aiter__方法设置返回值,这样才能得到正确的结果。此外,由于__aiter__本身就是迭代器的意思,所以,即使我们设置它的 return_value 为一个列表,它也会按次返回迭代结果,而不是整个 list。这是与我们前面介绍 return_value 和 side_effect 的异同时所讲的内容相区别的。
同样需要特别注意的是 async with 方法。你需要 mock 住它的__aexit__,将其替换成你要实现的方法。
3.2.3. builtin 对象¶
如果我们有一个程序,需要读取用户从控制台输入的参数,根据该参数进行一些计算。现在,我们需要测试这部分功能。显然,我们需要 mock 用户输入,否则单元测试没法自动化。
在 Python 中,接受用户控制台输入的函数是 input。要 mock 这个方法,按照前面学习中得到的经验,我们需要知道它属于哪个名字空间。可是,我们从来没有导入过它们,它们究竟该属于哪个名字空间呢?
在 Python 中,像 input, open, eval 等一类的函数大约有 80 个左右,被称为 builtin(内置函数)。在 mock 它们时,我们使用 builtins 名字空间来进行引用:
1 2 3 | |
执行上述代码时,我们就不再依赖用户输入了,因为 input 方法被 mock 替换了,并且总是会返回"input is mocked",这样我们的测试结果就能保证可重现。
3.2.4. 让时间就停留在这一刻¶
Quote
Verweile doch, du bist so schön! 你是如此美丽,请逗留片刻!
-- 浮士德
有时候我们会在代码中,通过 datetime.datetime.now() 来获取系统的当前时间。显然,在不同的时间进行测试,我们会得到不同的,这会导致测试结果无法固定。因此,时间也是需要被 mock 的对象。
要实现对这个方法的 mock,可能比我们一开始以为的要难一些。我们的推荐是,使用 freezegun 这个库,而避开自己去实现这个 mock。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
注意 Python 的时间库很多,如果您使用的是其它的库来获取当前时间,则 freeze_gun 很可能会不起作用。不过,对第三方的时间库,一般很容易实现 mock。
3.2.5. 如何制造一场“混乱”?¶
假设我们有一个爬虫在抓取百度的热搜词。它的功能主要由 crawl_baidu 来实现。我们另外有一个函数在调用它,以保存 crawl_baidu 的返回结果。我们想知道,如果 crawl_baidu 中抛出异常,那么调用函数是否能够正确处理这种情况。
这里的关键是,我们要让 crawl_baidu 能抛出异常。当然,我们不能靠拔网线来实现这一点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
crawl_baidu 依靠 httpx.get 来爬取数据。我们可以通过 mock httpx.get 方法,让它有时返回正常结果,有时返回异常。这是通过 side_effect 来实现的。
再强调一次!注意第 12 行,我们使用 self.assertRaises,而不是 try-except 来捕捉异常。两者都能够实现检查异常是否抛出的功能。但通过 self.assertRaises,我们强调了这里应该抛出一个异常,它是我们测试逻辑的一部分。而 try-except 则应该用来处理真正的异常。
3.2.6. 消失的魔法¶
再强调一遍,“使用 mock 的关键,是要找到被 mock 对象正确的引用方式。”而正确引用的关键,则是这样一句“咒语”:
Warning
Mock an item where it is used, not where it came from.
在对象被使用的地方进行 mock, 而不是在它出生的地方。
我们通过一个简单的例子来说明这一点:
1 2 3 4 5 6 7 8 9 10 | |
我们在 echo 方法中,调用了系统的 echo 命令。在测试中,我们试图 mock 住 os.system 方法,让它一被调用,就返回一个异常。然后我们通过 pytest 来检查,如果异常抛出,则证明 mock 成功,否则,mock 失败。
但是如果我们运行这个示例,只会得到一个友好的问候,No errors, No warnings! 为什么?
因为当我们在 echo() 函数中调用 system 函数时,此时的 system 存在于__main__名字空间,而不是 os 的名字空间。os 名字空间是 system 出生的地方,而__main__名字空间才是使用它的地方。因此,我们应该 patch 的对象是'main.system',而不是'os.system'。
现在,让我们将os.system改为__main__.system,重新运行,你会发现,魔法又生效了!
在配套代码中,还有一个名为 where_to_patch 的示例,我们也来看一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
测试代码会抛出 AssertionError: assert "Alice" == "Bob"的错误。如果我们把where_to_patch.foo改为where_to_patch.bar`,则测试通过。这个稍微扩展了一下的例子,进一步清晰地演示了如何正确引用被 mock 对象。
4. Coverage - 衡量测试的覆盖率¶
我们已经掌握了如何进行单元测试。接下来,一个很自然的问题浮现出来,我们如何知道单元测试的质量呢?这就提出了测试覆盖率的概念。覆盖率测量通常用于衡量测试的有效性。它可以显示您的代码的哪些部分已被测试过,哪些没有。
coverage.py 是最常用的测量 Python 程序代码覆盖率的工具。它监视您的程序,记录代码的哪些部分已被执行,然后分析源代码以识别已执行和未执行的代码。
我们可以通过下面的方法来安装 coverage.py:
1 | |
pytest arg1 arg2 arg3来进行测试,则现在我们使用:
1 | |
当测试运行完成后,我们可以通过coverage report -m来查看测试覆盖率的报告:
1 2 3 4 5 6 | |
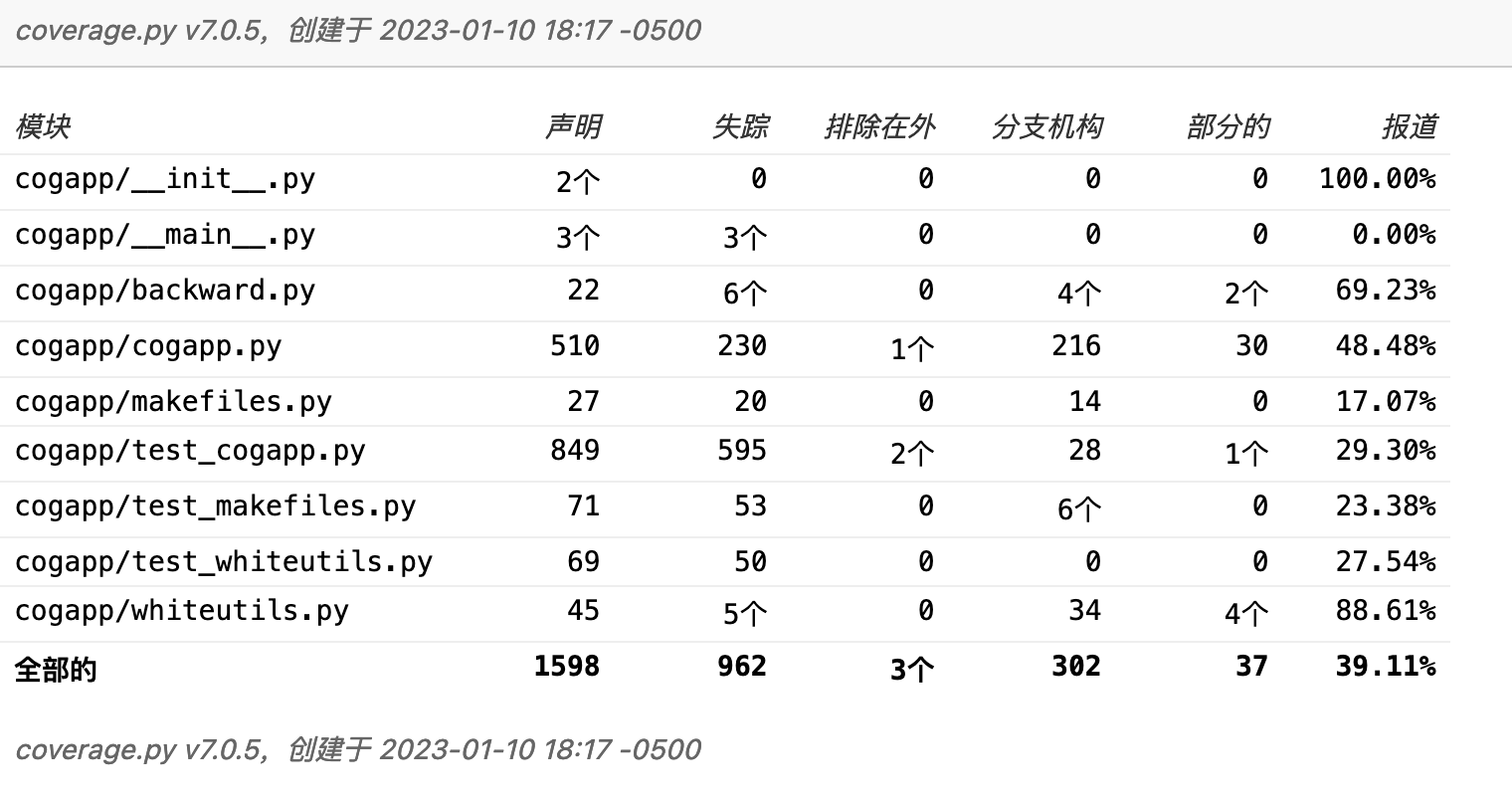
不过,更多人选择使用 pytest-cov 插件来进行测试覆盖率的收集。这也是 ppw 的选择。通过 ppw 生成的工程,pytest-cov 已被加入到测试依赖中,因此也就自然安装到环境中去了。
因此,通过 ppw 配置的工程,我们一般不需要直接调用 coverage 命令,而是使用 pytest 命令来进行测试。pytest-cov 插件会自动收集测试覆盖率数据,然后在测试完成后,将测试覆盖率报告打印到控制台上。如果希望生成带注释的 HTML 报告,可以使用pytest --cov-report=html命令。
默认情况下,coverage.py 将测试行(语句)覆盖率,但通过配置,还可以测量分支覆盖率。我们通过下面的示例代码来说明这两种覆盖分别是什么意思。
1 2 3 4 5 6 | |
在上面的代码中,第 2 行是一个 if 语句,根据 x 的取值,接下来可能运行到第 3 行,也可能运行到第 4 行。当 coverage 被配置为按语句计算覆盖时(这是默认的情况),只要该函数被执行,则 coverage 将统计为该函数的所有语句都已被执行过;但如果 coverage 被配置为按分支计算覆盖时,如果 x 求值的结果为 False,那么代码执行将从第 2 行直接跳到第 4 行。Coverage 将把第 2 行到第 4 行的代码标记为部分分支覆盖。
除了配置分支覆盖外,还有其它几种情况需要配置。接下来我们就介绍如何进行配置。
Coverage.py 配置文件的默认名称是。coveragerc,在 ppw 生成的工程中,这个文件处在项目根目录下(读者可以回到第 4 章的结束部分查看 ppw 生成的文件列表)。如果没有使用默认配置文件,Coverage.py 将从其他常用配置文件中,比如“setup.cfg”或“tox.ini”中读取设置。
在这些配置文件中,如果存在名称带有“coverage:”前缀的节 (section),则会被当成是 coverage 的配置,比如.coveragerc 中有一节名为 run,当它出现在 tox.ini 中,节名字就应该是 [coverage:run]。
我们也可以在 pyproject.toml 中配置 coverage。如果要使用这种方式,需要在 pyproject.toml 中添加一个名为 tool.coverage 的节,然后在这个节中添加配置项。
coverage 的配置项遵循 ini 语法,示例如下:
| .coveragerc | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
我们前面提到过可以让 coverage.py 按分支覆盖率来统计,这可以按照上面第 2 行一样进行配置。[report] 这一节中的配置项可以让 coverage.py 忽略一些不需要统计的代码,比如 debug 代码。[html] 这一节配置了生成的 html 文件应该存放在何处。如果没有指定,默认将存放在 htmlcov 目录下。
尽管在示例中没有提到,但 [run] 这一节比较常用的配置项还有 include 和 omit,用来特别把某个文件或者目录加入到测试覆盖,或者排除掉。在 [report] 这一节中,也有相同的配置项,两者有所区别。在 [report] 中指定 omit 或者 include,都仅适用于报告的生成,但不影响实际的测试覆盖率统计。
5. 发布覆盖率报告¶
如果我们的项目是开源项目,你可能希望把覆盖率报告发布到网上,这样其他人就可以看到你的项目的覆盖率了。这对推广你的开源项目非常有帮助。这里我们使用 codecov.io 来发布覆盖率报告。
codecov 是一个在线的代码覆盖率报告服务,它可以从 GitHub、Bitbucket、GitLab 等代码托管平台上获取代码覆盖率报告,然后生成一个在线的报告。这个报告可以让其他人看到你的项目的覆盖率情况。
在 github 中设置 codecov 集成很简单,在浏览器中打开 https://github.com/apps/codecov 页面,点击完成安装,然后在 CI 过程中增加一个上传动作就可以了。在通过 ppw 创建的项目中,我们已经集成了这一步。如果你想在自己的项目中手动执行,则可以分别执行以下命令(命令按不同的平台,分别给出)来完成上传:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |

并且还能在 pull request 的注释中看到覆盖率的变化:
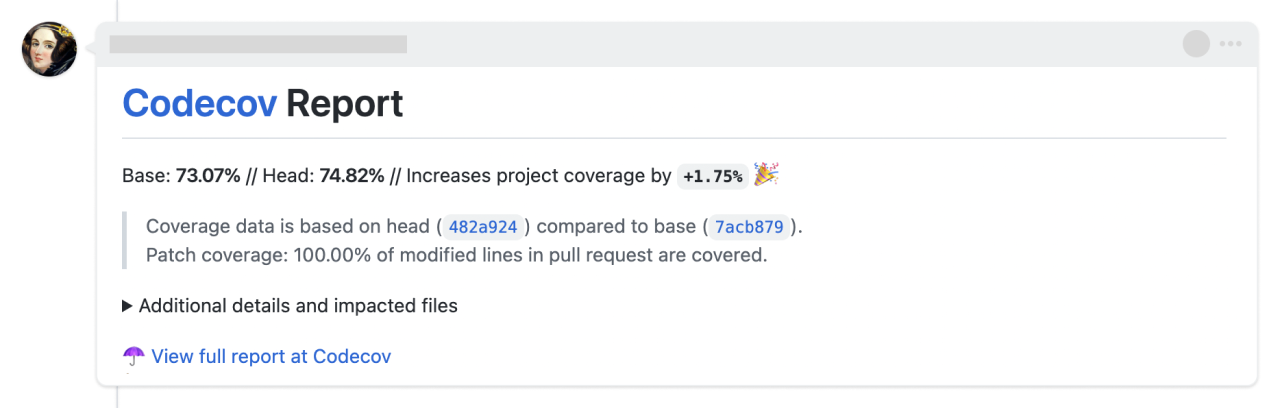
这会让你的开源项目看上去非常专业,不是吗?更重要的是,让你的潜在用户更加信任这是一个高质量的项目。
6. TOX 实现矩阵化测试¶
如果我们的软件支持 3 种操作系统,4 个 python 版本,我们就必须在 3 种操作系统上,分别创建 4 个虚拟环境,安装上我们的软件和依赖,再执行测试,上传测试报告。这个动作不仅相当繁琐,还很容易引入错误。
通过 tox 与 CI 结合,就可以帮助我们自动化完成这些环境的创建与测试执行。
6.1. 什么是 Tox?¶
Tox 是一个通用的 Python 虚拟环境管理和测试命令行工具,旨在自动化和标准化 Python 测试。它是简化 Python 软件的打包、测试和发布过程的更大愿景的一部分。大多数项目都使用它来确保软件在多个 Python 解释器版本之间的兼容性。
实际上,tox 主要完成以下工作: 1. 根据配置创建基于多个版本的 python 虚拟环境,并且保证这些虚拟环境的可复制性(需要与 poetry 或者其它依赖管理工具一起协作)。 2. 在多个环境中运行测试和代码检查工具,比如 pytest 和 flake8, black, mypy 等。 3. 隔离环境变量。tox 不会将系统的任何环境变量传递到虚拟环境中,这样可以保证测试的可重复性。
Tip
初学者可能并不习惯这个特性。这意味着如果你的测试或者代码需要读取某些环境变量,它们就不能设置在运行测试的主机中,而是必须在 tox 的配置文件中进行设置。这样做的目的,是为了保证测试结果的可重现性。
6.2. Tox 的工作原理¶
下图是 tox 文档显示的工作原理图:
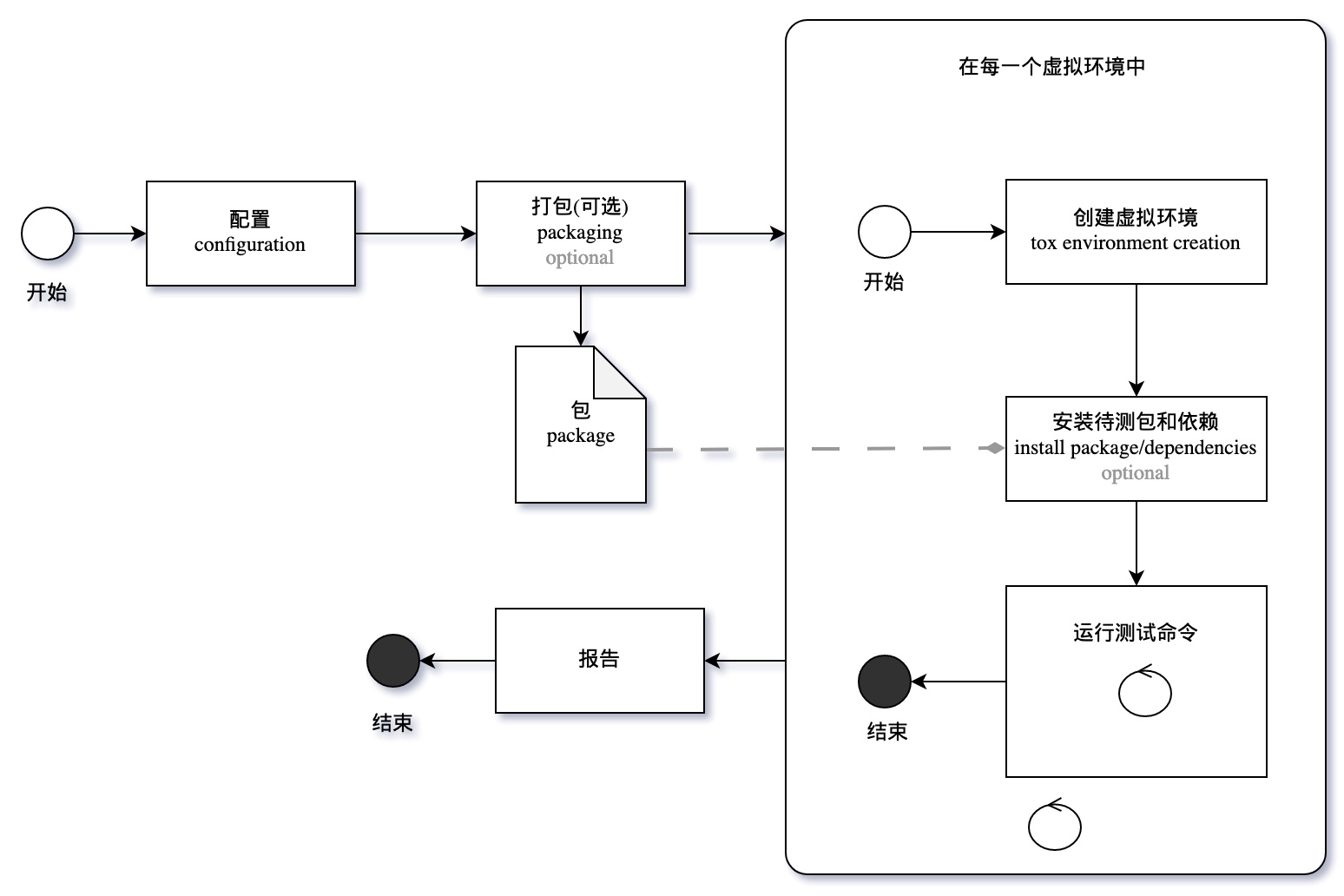
根据这张图,tox 读取配置文件,打包待测试软件,按照配置文件创建虚拟环境,并安装待测试软件和依赖,然后依次执行测试命令。最终,当所有虚拟环境下的测试都通过后,tox 会生成测试报告。
下面,我们主要通过一个典型的配置文件来介绍 tox 是如何配置和工作的。
6.3. 如何配置 Tox¶
在 ppw 生成的项目中,存在以下 tox.ini 文件:
| tox.ini | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
配置文件仍然是标准的 ini 文件格式(tox 也支持通过 pyproject.toml 来进行配置)。我们主要关注以下几个部分:
6.3.1. [tox] 节¶
在测试一个 package 之前,tox 首先需要构建一个 sdit 分发包。在打包这件事上,python 走过了很长的一段历程,打包工具和标准也经历了很多变化,这些我们将用专门的一章来介绍。现在我们需要知道的是,最新的标准是 PEP517 和 PEP518,tox 已经支持这两个标准。但是,如果项目本身不支持这两个 PEP,那么 tox 必须回到之前的打包方式。
因此,tox 引入了 isolated_build 这个选项,如果设置为 true,tox 会使用 PEP517 和 PEP518 的方式来打包项目。如果设置为 false,tox 会使用传统的方式 (setup.py) 来打包项目。如果通过 poetry 创建项目,并且在 pyproject.toml 中设置了 requires 和 build-backend 项的话,那么我们是需要设置 isolated_build 为 true 的。
在所有 ppw 创建的项目中,我们都设置了 isolated_build 为 true,这样才与 pyproject.toml 的设置一致。
envlist 选项的含义正如它的名字所示,表明了我们需要在多少个环境下分别运行测试。这里我们指定了 py38, py39, p310 和 lint 这 4 个虚拟环境。Tox 会自动根据环境名字来决定该环境中需要安装的 Python 版本,比如,它能从 py38 这个名字分析出来应该使用 Python 3.8 的版本。这里我们还指定了一个 lint 环境,它是用来执行代码检查的。我们没有为它专门指定 python 的版本,Tox 也无法从名字分析出来 Python 的版本,因此它会使用当前的 python 版本。
默认地,tox 会在项目根目录下创建.tox 目录,上述虚拟环境就创建在这个目录下:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
列目录时,显示出来存在 lint, py38 和 py39,我们可以进一步查看这些虚拟环境下的 python 版本。但是,我们没有看到 py310,这里因为在我测试时,系统还没有安装 python 3.10 这个版本,因此 tox 会暂时跳过这个版本,直到我们安装 Python 3.10,tox 才会在测试初始化时,创建 py310 的环境。
skipsdist 选项用来指示 tox 是否要跳过构建 sdist 分发包的步骤。这个设置主要是为了兼容 python 应用程序,因为 tox 的测试对象除了 library 之外,还可能是服务或者简单的脚本集,这些服务或者脚本集是没有 setup.py 文件,也无法构建 sdist 分发包的。如果没有一个标志让 tox 来跳过构建 sdist 分发包的步骤,那么 tox 会报错:
1 2 3 4 5 6 7 8 9 | |
这个选项在 tox 中是默认为 false 的,多数情况下无须配置。我们出于帮助大家理解 tox 工作原理的目的才在这里介绍它。
6.3.2. [testenv] 节¶
这一节的配置项适用于所有的虚拟环境。如果在某个虚拟环境下存在特别的选项和动作,需要象 [testenv:lint] 那样定义在自己的节中。
这里我们还额外设置了一些环境变量字段。比如设置了 PYTHONPATH,另外也忽略了一些警告信息(第 27 行)。如果我们使用的一些库没有更新,那么将在测试过程中打印大量的 deprecation 警告,从而干扰我们检查测试过程中的错误信息。当然,我们也应该至少在测试中打开一次这种警告,以便知道哪些用法已经需要更新。
一般情况下,tox 是不会把宿主机上的环境变量传递给测试环境的。但有一些情况,比如重要服务的账号和口令,并不适合写在配置文件中,只能配置在宿主机的环境变量中。在这种情况下,我们需要通过 passenv 选项来指定需要传递的环境变量。这个选项的值是一个逗号分隔的字符串,可以是单个的环境变量,也可以象示例中那样,是一个通配符。
Info
在团队开发中,并不是所有的开发者都有权接触到重要服务的账号与口令。如果这些秘密信息配置在代码文件或者相关的配置文件中,就会导致这些秘密暴露给了所有的开发者。此外,如果代码仓库使用的是 gitlab,还可能导致这些信息泄露到互联网上。正确的作法是将这些重要信息仅仅配置在宿主机的环境变量中,这样一来,就只有有权访问那台机器的人才能接触到这些秘密。
这是一种标准的做法,也得到了 github CI 的支持。在 github CI 中,可以通过在 workflow 文件中使用 env 选项来读取环境变量,再经由 tox 把这些环境变量传递给测试环境。
deps 选项声明了要在虚拟环境中安装的 python 库。不同的测试需要的依赖可能各不相同,但在 ppw 生成的项目中,一般我们只需要一个共同的依赖,即 poetry。因为后面的测试命令,我们都会通过 poetry 来调用。
Tox 在安装被测试包时,一般是不安装声明为 extra 类型的依赖的。但是,为了运行测试和进行 lint,我们必须安装 pytest, Flake8 等第三方库。在 ppw 生成的工程中,这些 extra 类型的依赖又被细分为 dev, test 和 doc。其中 test 依赖是所有测试环境(即 py38, py310 等)中需要安装的,而 dev 和 doc 一般只在 lint 时需要安装。因此,我们在 [testenv] 了对 test 的依赖,而 [testenv:lint] 则依赖到 dev 和 doc。
接下来就是 commands 字段。这是真正执行测试或者 lint 的地方。这里的命令是:
1 2 3 | |
在 ppw 生成的工程里,我们已经集成了 pytest-coverage 插件,因此,通过适当的配置,我们就可以在测试时同时完成测试覆盖率的统计。--cov 用来指示代码覆盖的范围,这里%package_under_test%需要替换成为我们的待测试程序库名字。--cov-append 表明此次测试的结果,将追加到之前的统计数据中,而不是完全替换之前的数据。--cov-report 将测试数据输出为 xml 格式。--cov-report 表明应该如何生成报告。
最后,tests 是我们测试代码所在的文件夹。
6.3.3. [testenv.lint]¶
这一节的语法与 [testenv] 并无二致。只不过要运行的命令不一样。这里就不再一一解释。
-
根据 pytest 文档,pytest session 是指通过 pytest 命令启动的一次测试过程。 ↩