Alphalens 因子分析 - 以低换手率因子为例(1)
 因子分析是量化研究的基本技能之一。通过因子分析,找出有效的因子,通过相关性去重后,就可以通过机器学习、线性回归等方法把因子组合起来,构成交易策略。
因子分析是量化研究的基本技能之一。通过因子分析,找出有效的因子,通过相关性去重后,就可以通过机器学习、线性回归等方法把因子组合起来,构成交易策略。
这一篇笔记我们就介绍如何使用 Alphalens 来进行单因子分析。我们使用的因子是低换手率因子。
股谚有一种说法,天量见天价,地量见地价。其背后的原理是,当成交量达到天量时,击鼓传花的游戏将后继乏人,难以持续,因而股价大概率回落。而成交量出现地量时,显示成交极为冷清,被套者无人愿割,因此由于失去做空力量,从而有可能向上反转。
衡量成交量的大小,我们可以有两种方法。
一种是在时间维度上,我们使用成交量是多少天(n)以来的最小值、最大值来表示。n 越大,包含的信息量就越大;另一种是在横截面维度上进行排名,此时需要先对成交量进行对齐,对齐的方式,就是将成交量转换成换手率。
Info
换手率是一定时间内,市场中标的转手买卖的频率,是反映标的交投活跃程度的指标之一。它的计算公式是 \(\(换手率 = \frac{成交额}{流通股数}\)\)
手工计算需要两方面的数据,一是每日的成交额,另一组是流通股数。流通股数是一个低频变化的数据,也需要进行复权,计算比较复杂。所以,我们一般直接从数据源处获得此数据。
这篇笔记我们仍然使用免费的 akshare 来获取相关数据。不过,考虑到 QMT 量化权限的开通门槛现在已经很低了,只要开通了 QMT,也就相当于免费获得了这些数据,因此后面的笔记就会主要使用 QMT 来获取数据了,只有在某些品种 QMT 还没有提供时,我们才会使用 akshare。
我们的低换手率因子将构建在沪深 300 成份股上。整个构建过程是:
💡 1. 获取沪深 300 成份股代码
💡 2. 获取一段时间内 300 成份股的价格和换手率数据
💡 3. 生成 alphalens 需要的 factor 和 forward returns 数据
💡 4. 进行因子检验分析
Alphalens 能生成的报告非常多(下图为其中之一),所以,第 4 步我们将分几篇笔记详细进行介绍。

一个完整的因子分析流程包括原始数据获取、生成因子、数据(及因子)预处理、因子检验。
预处理包括缺失值统计、中性化、去极值、标准化等操作;因子检验则有 IC 法、分层回测等方法。
因子生成因为涉及到核心算法,需要由研究员自己完成,其它的部分,我们掌握原理之后,就可以借助框架来完成。不过,在本例中,因子生成无须另外构造,我们直接使用换手率就好。
获取数据¶
我们通过下面的代码来获取沪深 300 成份股代码:
1 2 3 4 5 | |
我们通过 index_stock_cons_csindex 这个 API 来获取指数成份股,沪深 300 的代码是 000300。
你将会看到 000001, 000002 等输出。akshare 输出的证券代码很多时候是不带交易所(前)后缀的。
Warning
这里实际上已经引入了一个错误。通过 index_stock_cons_csindex 获取的指数成份股,都是最新的数据。而成份股列表实际上是在持续更新的。如果我们在 2023 年的元月获取沪深 300 成份股,结果很可能会与今天获取的不一致。
考虑到某所经常把创新高的标的纳入指数,下跌后的标的剔除指数,所以,因未能使用 PIT 数据,我们实际上上修了该因子的收益率。
接下来我们获取这些标的的收盘价和换手率。在 akshare 中,stock_zh_a_hist 这个 API 的返回值中,同时包含了收盘价和换手率:
1 2 | |

返回值有很多列,我们只关心日期、收盘和换手率这三项。这个 API 有一个 adjust 参数,即要求我们选择复权方式。在本例中我们使用 qfq 和 hfq 都没有任何区别,但是不能使用不复权数据。
熟悉了 akshare 的基本 API 之后,我们就正式获取数据,并将它转换成 alphalens 所需要的格式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
alphalens 进行分析时,需要的 factor 数据表的格式如下:
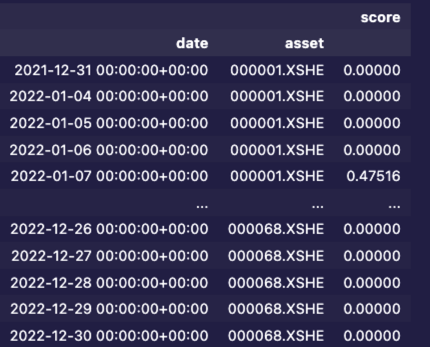
关键之处是,它是必须是一个由 date + asset 的双重索引的 DataFrame。而这个 dataframe 应该只有一列,列名字没有规定,但建议使用 factor 这样的列名字,这样更容易理解(bad example here!)。
stock_zh_a_hist 只能返回个股的行情数据。我们要先给它增加 asset 列(其值为个股代码),然后简单地将每支个股的换手率数据拼接成一个大的 dataframe,再进行重命名、设置多重索引就可以了。
这里要注意, alphalens 要注日期时间字段为 timezone-aware 数据,即要设置时区,并且两个表的时间要一致。
akshare 返回的日期字段类型为字符串,所以我们要进行一次转换。但像换手率、收盘价数据则已经是 float64 格式了。
1 2 3 4 5 6 7 8 9 10 11 12 | |
prices 表格必须转换成以下格式:

格式的要点是,它是以日期为索引,每个 asset 的代码为列的一个 dataframe,每一个 cell 的值则是当天某个 asset 对应的收盘价。
先将各个子 price frame 拼接起来,然后通过 pivot 函数,对表格进行转换,最终就得到上面的格式。这个转换如下图所示:

现在,我们就得到了符合 alphalens 要求的数据。数据准备工作已经完成。
数据预处理¶
处理缺失值、中性化、标准化等工作,如果有必要,alphalens 将会为我们处理。alphalens 提供了 get_clean_factor_and_forward_returns 这个 API:
1 2 3 4 5 6 7 8 9 | |
经过预处理后的结果如下:
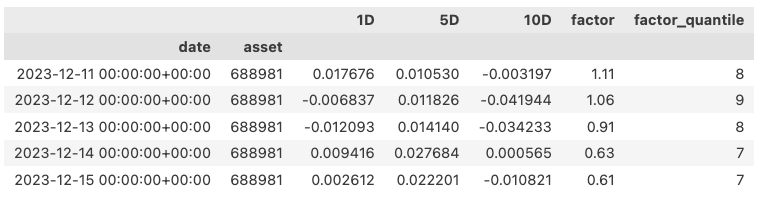
因子分析有绝对收益法、IC 法和分层法,这在 Alphalens 中是同步处理的 -- 你可以选择只看某个分析结果,但在预处理阶段,我们必须把相应的参数传递进去。这里的参数 bins/quantiles 就是用来分层的。
bins/quantiles 的用法类似于 dataframe 的 cut 或者 hist() 函数中的同名参数。这里我们简单介绍一下。
上例中我们指定了 quantiles=10,它是把每一天的因子数据从小到大排列后,按 len(df)/10 进行切分,即每个分片中,大致落入相等的因子记录(由于缺失值处理等原因,所以不会完全相等)。
我们可以 group 之后,看下结果:
1 | |
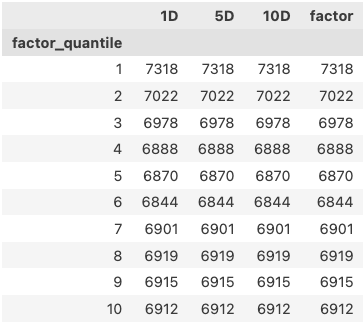
如果我们不使用 quantiles 参数,而是指定 bin 为 10,则它会把区间 [min(factor), max(factor)] 进行均匀划分,即每个 bins 的宽度一样,但落在 bin 中的个数不一样, groupby 之后的结果如下:
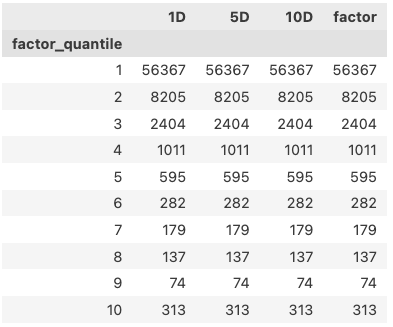
两相对照,两个参数的异同不言自明。
!!! faq 本例中,我们将使用 quantiles,为什么? 我们要验证的是地量见地价这句股谚。因此,我们应该选择换手率最低的个股买入。为了平衡风险,我们可能选择 30 支,也就是 10%左右的标的买入。因此,我们按 quantiles 划分才是合理的。
现在,我们就完成了因子分析的前三步,接下来,我们将在下一篇笔记中介绍低换手率因子的结果。
Tip
尽管有无数人使用,但 Alphalens 已经无人维护了。它依赖的 python 库却在不断前行。现在你使用 alphalens 的话,会遇到以下错误:
1 | |
好在 ml4trading 已经接手了这一工作,通过 alphalens-reloaded 来继续维护。如果你要使用这个库的话,也请在 Github 上为这个项目 star 吧。