量化数据免费方案之 QMT
学习要点
- xtquant 提供了数据和交易接口
- xtquant 可以独立于 QMT 之外运行
- download_history_data
- download_history_data2
- get_market_data
QMT 和 XtQuant 简介¶
QMT 是目前接入门槛最低的量化实盘接口之一。它提供了本地部署的量化平台(可以回测和实盘),也提供了可独立于该平台运行的 SDK,即 XtQuant。
XtQuant 仅提供行情数据和交易接口,不提供回测功能。目前通过 XtQuant 获取普通行情数据是免费的,但有流速限制,据测试,低于 1 秒获取一次是没有问题的。
XtQuant 获取行情数据¶
XtQuant 中,数据获取一般分两个阶段,首先是缓存阶段,然后是读取阶段。
缓存阶段的 API 一般以 download_开头。
因此,我们要获取历史行情数据,首先要进行缓存。使用的 API 是:
1 2 3 4 5 6 | |
如果我们要一次下载多支证券的行情数据,还可以使用download_history_data2这个 API。
如果在 start_time 到 end_time 区间的数据被缓存后,我们就可以调用get_market_data来获取行情数据。
1 2 3 4 5 6 7 8 9 | |
该方法可以获取'1m', '5m', '15m', '30m', '1h', '1d'和分笔 (tick) 数据。不同的周期下,返回的字段有所不同。除分笔外,能返回的数据包括时间,OHLC,volume(成交手)和 amount(成交金额)。
Warning
fill_data建议都设置为 False。它的行为是使用前一条数据进行填充,类似于 pandas 的 fillna 中的ffil。但行情软件在计算技术指标时,都是跳过这些缺失数据,而不是使用的填充数据。因此,我们也应该将fill_data设置为 False, 以避免与其它人行为不一致。
注意该方法不能返回复权因子。因此,如果我们不是为了直接使用返回的数据,而是要将其转存到其它数据库的话,我们还需要调用get_divid_factors来获得复权因子,与这里获得的未复权数据一起保存。直接转存任何已经复权的数据是没有意义的。即使是后复权,也存在出错的可能。
示例¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
get_market_data的返回结果是一个dict。它的key是行情字段,比如time, open, close等。其值则是以证券代码为索引,以时间为列的各个字段值。在上述示例的输出中,我们将其进行了转置,这也是我们正常情况下,使用它们的方式。
最终输出如下:
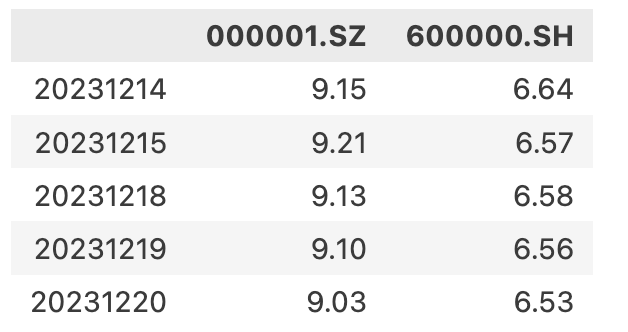
注意 xtquant 使用的日期格式,如果周期为 1d,则是"YYYYMMDD"。如果周期为分钟级,则为"YYYYMMDDHHmmss"。如果我们使用的时间是 datatime.datetime 的话,可以用以下方式来格式化:
1 2 3 4 5 6 7 | |
strftime的格式串不容易记忆, arrow 时间库在这点上进行了改进,周期由大到小,表示形式也实现了递进,比较容易记忆。在不涉及到性能的情况下,我们可以先将其转换为 Arrow 对象,再进行格式化。