21 天驯化 AI 打工仔:系统逻辑优化与分钟线数据合成
当分笔数据如潮水般涌来,如何让系统智能地将它们合成为有价值的分钟线数据?本文带你深入量化交易系统的核心——数据合成与系统架构优化的世界!
"007,我们的实时分笔数据订阅系统已经基本完成,但现在我遇到了一个新的挑战。"我一边查看着 Redis 中堆积如山的分笔数据,一边对我的 AI 助手说道。
"什么挑战?"007 立刻回应道。
"我们现在有了海量的分笔数据,但量化策略需要的是分钟线数据。而且,我希望系统能够智能地处理当日数据和历史数据,让多个客户端能够无缝查询。"我指着屏幕上密密麻麻的数据说道。
这是我们量化交易系统开发的第 9 天。前面几天,我们已经成功搭建了从 Tushare 获取数据的基础架构,也实现了 QMT 实时分笔数据的订阅。但在实际使用中,我发现了一个关键问题:分笔数据虽然精确,但对于大多数量化策略来说,分钟线数据才是真正需要的。
更重要的是,我需要一个智能的系统架构,能够:
- 实时将分笔数据合成为多周期分钟线数据
- 智能区分当日数据和历史数据的存储与查询
- 支持多个客户端同时查询,而不影响系统性能
- 确保数据的完整性和一致性
🎯 需求分析:构建智能数据合成系统
"在开始编码之前,我们需要明确系统的核心需求。"我对 007 说道。
经过深入思考,我梳理出了以下关键系统架构:
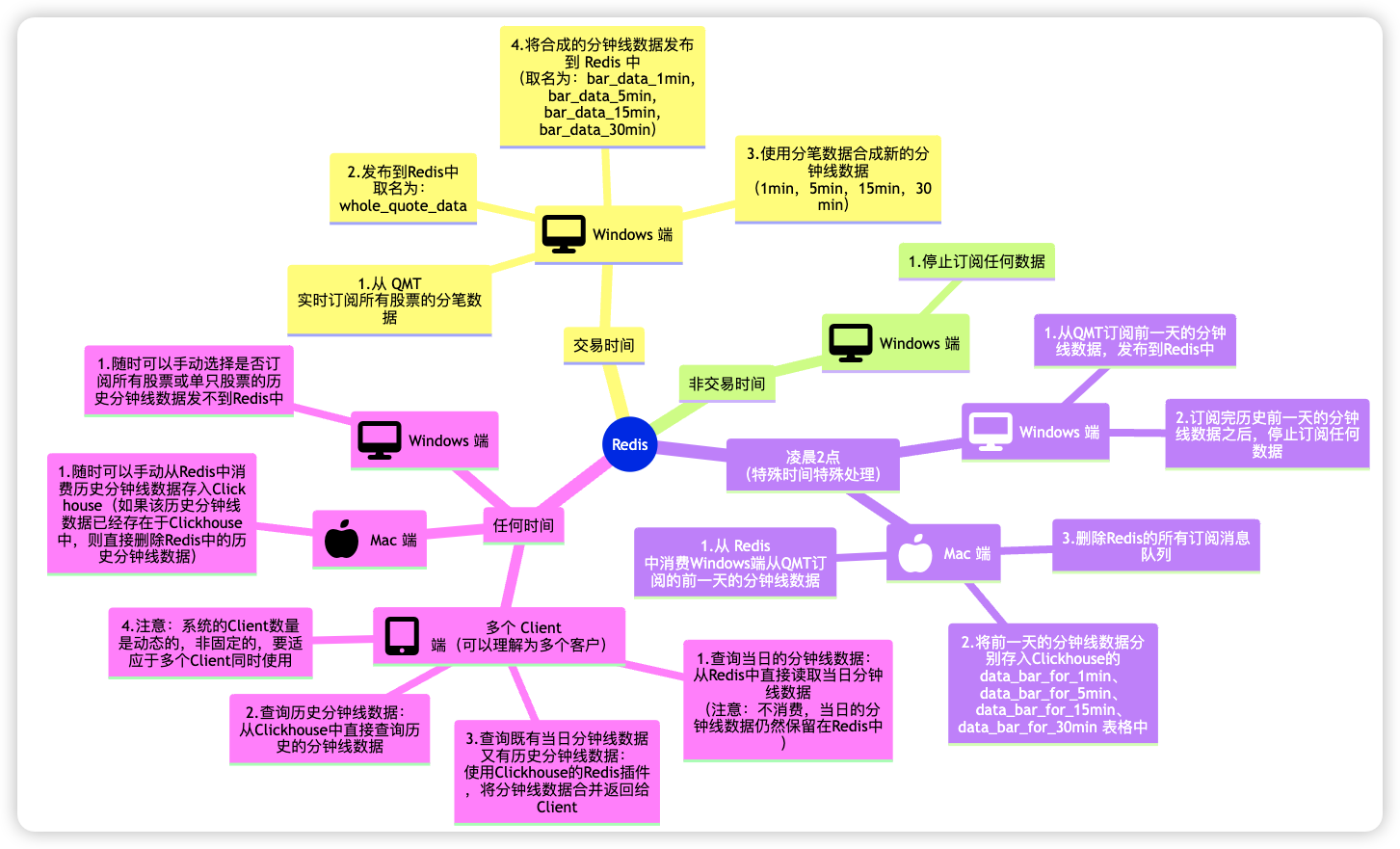
注意:
- 所有的分钟线数据(不论是当日合成的数据还是订阅的历史分钟线数据)都必须是交易时间内的数据。不然没有意义。
- 当日合成的分钟线数据是保存在Redis中的,不要存入Clickhouse。
- 只有从QMT订阅的历史的分钟线数据是通过Redis保存在Clickhouse中的,请注意与当日合成的分钟线数据进行区分。
参考内容:Clickhouse 的 Redis 插件 和 Clickhouse 的物化视图。
"这个架构看起来很复杂,特别是数据合成的部分。"我有些担心地说道。
"没关系!我们可以分步实现。先搭建基础架构,然后逐步优化数据合成算法。"007 信心满满地回答。
🏗️ 系统架构设计:三端分离的智能架构
"我们需要设计一个真正智能的三端分离架构。"007 开始了架构设计。
整体架构图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 | ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Windows端 │ │ 远程Redis │ │ Mac端 │
│ 数据生产者 │───▶│ 消息队列+缓存 │───▶│ 数据消费者 │
│ │ │ │ │ │
│ • QMT分笔订阅 │ │ • 分笔数据队列 │ │ • 历史数据存储 │
│ • 分钟线合成 │ │ • 当日分钟线缓存 │ │ • ClickHouse管理 │
│ • 交易时间验证 │ │ • 数据路由 │ │ • 数据清理 │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│
▼
┌─────────────────┐
│ 多Client端 │
│ 数据查询者 │
│ │
│ • Web查询界面 │
│ • 智能数据路由 │
│ • 24小时制时间 │
└─────────────────┘
|
数据流设计
"数据流的设计是整个系统的核心。"我对 007 强调道。
数据流向:
1. 分笔数据流:QMT → Windows端 → Redis队列
2. 当日分钟线流:Windows端合成 → Redis缓存 → Client端查询
3. 历史分钟线流:Mac端处理 → ClickHouse存储 → Client端查询
4. 混合查询流:Client端 → Redis+ClickHouse → 数据合并 → 返回结果
🔧 Windows 端的实现
"Windows 端是整个系统的心脏,负责数据的实时合成。"007 开始了 Windows 端的设计。
分笔数据如何合成分钟线数据?
007 设计了一个精巧的数据合成引擎:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | class BarDataSynthesizer:
"""分钟线数据合成器"""
def __init__(self):
# 存储各个股票的分笔数据缓存
self.tick_cache: Dict[str, List[TickData]] = defaultdict(list)
# 存储各个周期的分钟线缓存
self.bar_cache: Dict[int, Dict[str, List[BarData]]] = {
1: defaultdict(list),
5: defaultdict(list),
15: defaultdict(list),
30: defaultdict(list)
}
# 交易时间验证器
self.trading_validator = TradingTimeValidator()
def add_tick_data(self, tick_data: TickData):
"""添加分笔数据并触发合成"""
# 验证交易时间
if not self.trading_validator.validate_tick_data(tick_dict):
return
# 缓存分笔数据
self.tick_cache[tick_data.symbol].append(tick_data)
# 合成1分钟线
bar_1min = self._synthesize_1min_bar(tick_data.symbol)
if bar_1min:
self.bar_cache[1][tick_data.symbol].append(bar_1min)
# 基于1分钟线合成其他周期
for period in [5, 15, 30]:
bar = self._synthesize_multi_min_bar(tick_data.symbol, period)
if bar:
self.bar_cache[period][tick_data.symbol].append(bar)
|
1分钟线合成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | def _synthesize_1min_bar(self, symbol: str) -> BarData:
"""合成1分钟线"""
ticks = self.tick_cache[symbol]
if not ticks:
return None
# 获取当前分钟的开始时间
current_time = ticks[-1].time
minute_start = current_time.replace(second=0, microsecond=0)
minute_end = minute_start + timedelta(minutes=1)
# 筛选当前分钟的分笔数据
minute_ticks = [
tick for tick in ticks
if minute_start <= tick.time < minute_end
]
if not minute_ticks:
return None
# 计算OHLCV
prices = [tick.price for tick in minute_ticks]
volumes = [tick.volume for tick in minute_ticks]
amounts = [tick.amount for tick in minute_ticks]
return BarData(
symbol=symbol,
frame=minute_start,
open=prices[0],
high=max(prices),
low=min(prices),
close=prices[-1],
vol=sum(volumes),
amount=sum(amounts)
)
|
多周期合成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31 | def _synthesize_multi_min_bar(self, symbol: str, period: int) -> BarData:
"""合成多分钟线(5分钟、15分钟、30分钟)"""
bars_1min = self.bar_cache[1][symbol]
if not bars_1min:
return None
# 获取当前周期的开始时间
current_time = bars_1min[-1].frame
period_start = self._get_period_start(current_time, period)
period_end = period_start + timedelta(minutes=period)
# 筛选当前周期的1分钟线数据
period_bars = [
bar for bar in bars_1min
if period_start <= bar.frame < period_end
]
if len(period_bars) == 0:
return None
# 合成多分钟线
return BarData(
symbol=symbol,
frame=period_start,
open=period_bars[0].open,
high=max(bar.high for bar in period_bars),
low=min(bar.low for bar in period_bars),
close=period_bars[-1].close,
vol=sum(bar.vol for bar in period_bars),
amount=sum(bar.amount for bar in period_bars)
)
|
我们的合成方法是:先合成1分钟线,再基于1分钟线合成其他周期,确保了数据的一致性。
Windows 端监控页面
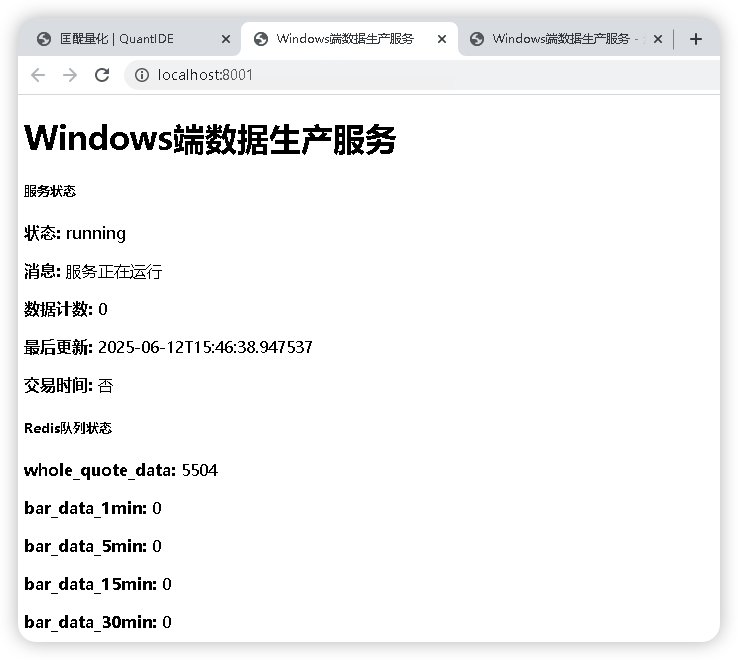

但是我觉得这个监控页面的排版布局太简陋了,于是,我便让 007 帮我设计一个新的前端页面以更好地呈现监控情况。
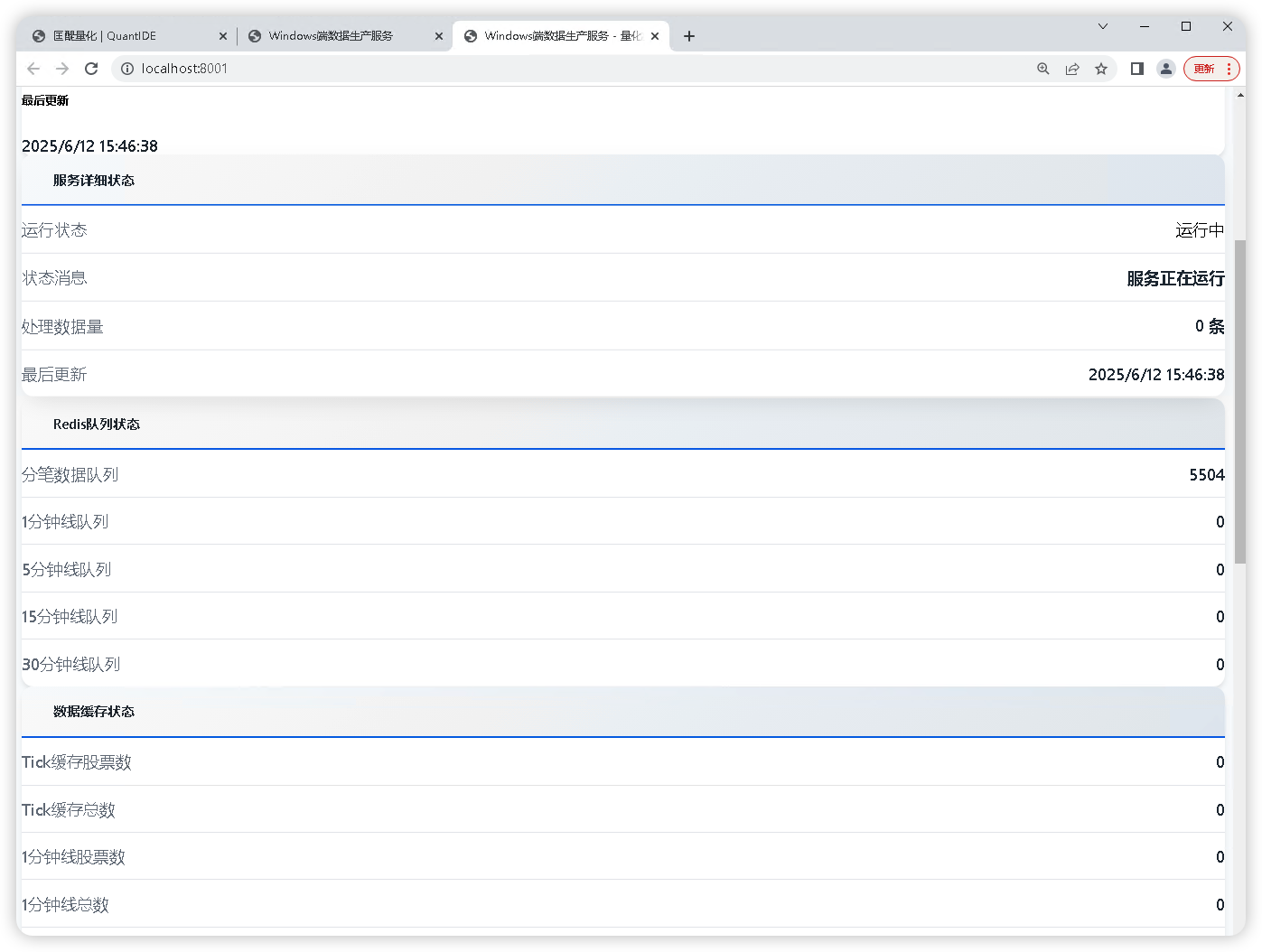
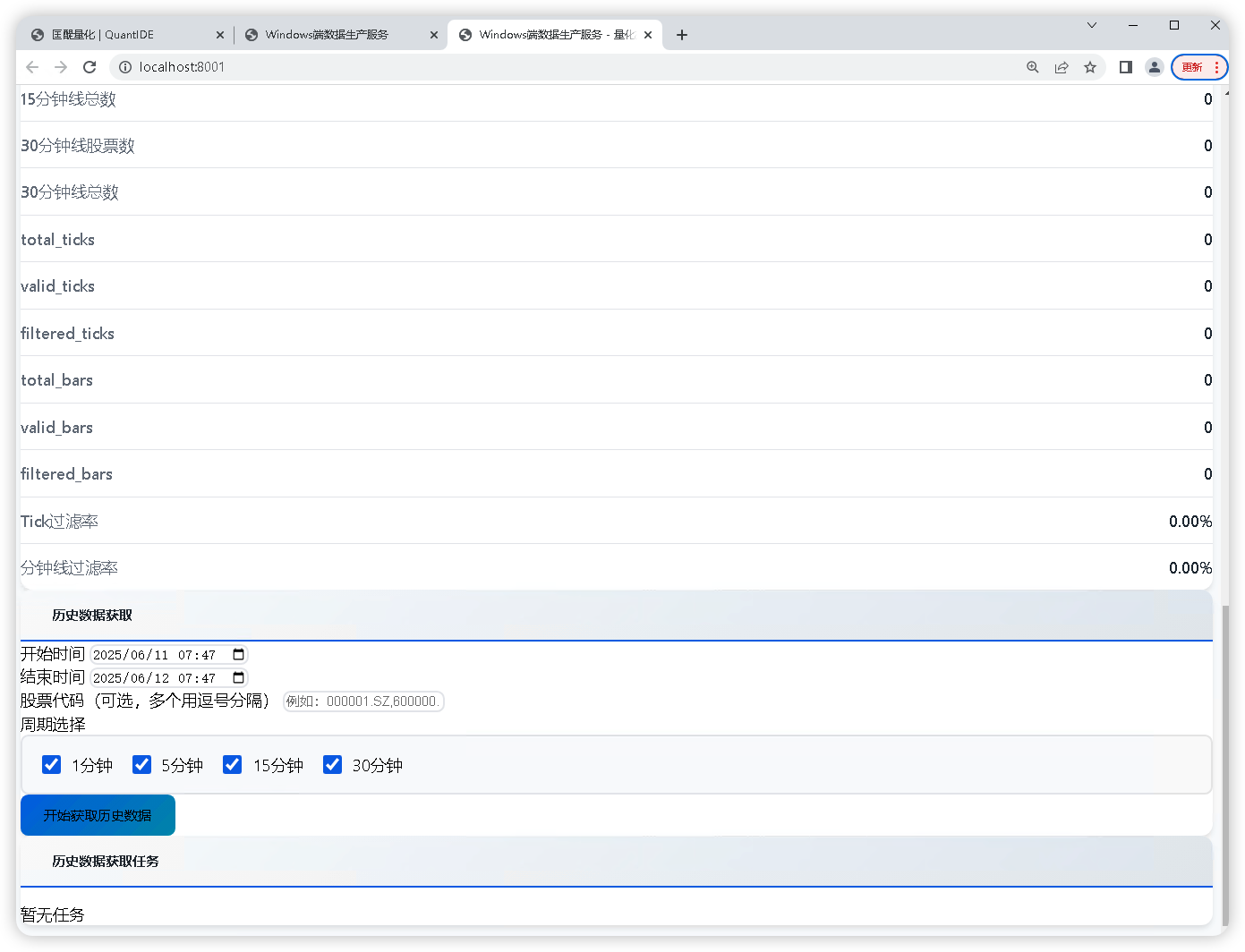
🍎 Mac 端的实现
数据消费与存储
Mac 端的核心职责是将 Redis 中的历史数据转移到 ClickHouse:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30 | class MacDataService:
"""Mac端数据服务"""
def __init__(self):
self.redis_manager = RedisManager()
self.clickhouse_manager = ClickHouseManager()
def consume_historical_data(self):
"""消费历史数据"""
while self.is_running:
try:
# 从Redis获取历史分钟线数据
for period in [1, 5, 15, 30]:
queue_name = f"historical_bar_data_{period}min"
data = self.redis_manager.client.brpop(queue_name, timeout=1)
if data:
bar_data = BarData(**json.loads(data[1]))
# 检查是否已存在
if not self.clickhouse_manager.data_exists(bar_data, period):
# 插入ClickHouse
self.clickhouse_manager.insert_bar_data(bar_data, period)
else:
# 数据已存在,直接删除Redis中的数据
self.logger.info(f"数据已存在,跳过: {bar_data.symbol} {bar_data.frame}")
except Exception as e:
self.logger.error(f"数据消费错误: {e}")
time.sleep(5)
|
凌晨2点的特殊处理
"系统需要在凌晨2点进行特殊的数据清理。"我对 007 说明了需求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | def handle_cleanup_time(self):
"""处理凌晨2点的数据清理"""
try:
# 1. 处理前一天的历史数据
self.process_previous_day_data()
# 2. 清理Redis的订阅消息队列
self.cleanup_redis_queues()
# 3. 数据完整性检查
self.verify_data_integrity()
self.logger.info("凌晨2点数据清理完成")
except Exception as e:
self.logger.error(f"数据清理错误: {e}")
|
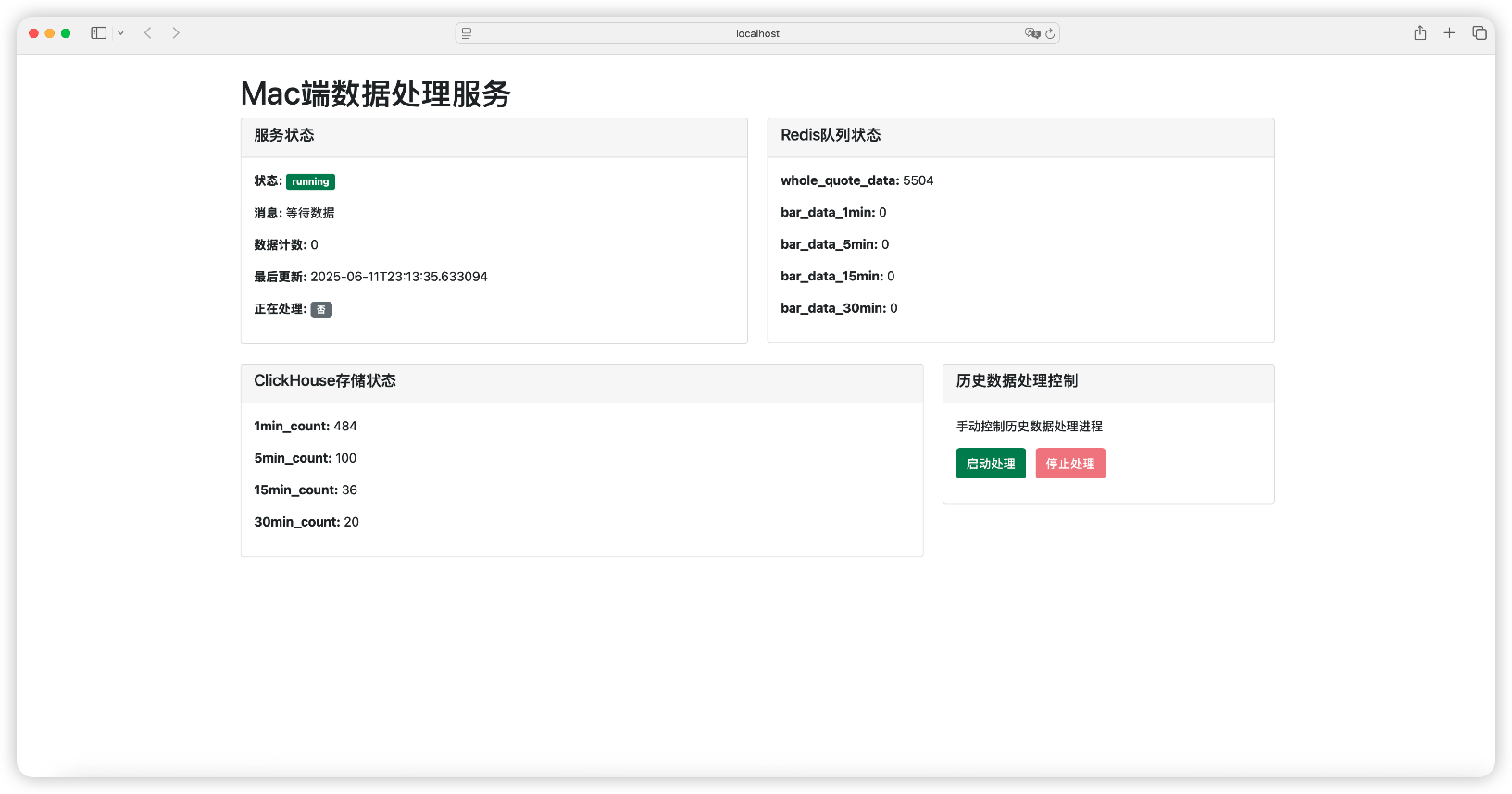
Mac 端的监控页面
为了检查Redis和Clickhouse之间的数据传送是正常的,并且能实时监控数据传输的速度和进度,我要求 007 设计一个 Mac 端端监控页面:
💻 Client 端的实现
"Client 端是用户直接接触的界面,必须做到完美。"我对 007 强调道。
但是,在 Client 端的开发过程中,我们遇到了一系列挑战...
第一次尝试:复杂的调试系统
最初,007 为 Client 端设计了一个功能丰富的调试系统:
| # 复杂的调试逻辑
def query_bar_data(self, symbol: str, start_time: datetime, end_time: datetime, period: int):
debug_info = []
debug_info.append(f"查询参数: {symbol}, {period}分钟, {start_time} 到 {end_time}")
debug_info.append(f"今天: {today}, 查询日期范围: {start_date} 到 {end_date}")
# 大量的调试信息...
if len(all_redis_data) > 0 and len(redis_data) == 0:
debug_info.append(f"⚠️ 时间过滤导致数据为空")
debug_info.append(f"数据样本时间: {sample_bar.frame}")
# 更多调试信息...
|
"这个调试系统太复杂了!"我看着满屏的调试代码,有些头疼。
第二次尝试:时间格式的噩梦
接着,我们遇到了时间格式的问题。用户抱怨 Web 界面显示的是 AM/PM 格式:
"我要24小时时间制查询,怎么前端还有AM和PM,我不要AM和PM,气死了!"
007 立刻进行了修复,将 datetime-local 输入框替换为分离的时间输入:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | <!-- 24小时制时间输入 -->
<div class="col-md-3">
<label for="start_time" class="form-label">开始时间 (24小时制)</label>
<div class="row g-1">
<div class="col-6">
<input type="date" class="form-control" id="start_date" required>
</div>
<div class="col-3">
<input type="number" class="form-control" id="start_hour" min="0" max="23" placeholder="时" required>
</div>
<div class="col-3">
<input type="number" class="form-control" id="start_minute" min="0" max="59" placeholder="分" required>
</div>
</div>
</div>
|
第三次尝试:JSON序列化的陷阱
然后,我们遇到了 JSON 序列化错误:
| 查询失败: 请求处理错误: Object of type datetime is not JSON serializable
|
"这个错误很常见,datetime 对象无法直接序列化。"007 解释道。
我们尝试了多种解决方案,最终采用了手动序列化:
1
2
3
4
5
6
7
8
9
10
11
12
13 | # 手动序列化,确保datetime正确转换
data_list = []
for bar in result.data:
data_list.append({
"symbol": bar.symbol,
"frame": bar.frame.isoformat(), # 手动转换datetime为字符串
"open": float(bar.open),
"high": float(bar.high),
"low": float(bar.low),
"close": float(bar.close),
"vol": float(bar.vol),
"amount": float(bar.amount)
})
|
最终重构:简洁而强大
"007!我觉得你把Client的查询代码改的乱七八糟的,你应该全部推翻,按照Windows和Mac的逻辑重新写查询。"我终于忍不住了。
007 立刻进行了彻底重构,按照系统架构的原始设计重新编写:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49 | def query_bar_data(self, symbol: str, start_time: datetime, end_time: datetime, period: int) -> QueryResponse:
"""
查询分钟线数据
按照系统架构:
1. 如果查询的分钟线数据是当日的,则直接从Redis中读取合成的分钟线数据
2. 如果查询的分钟线数据是历史的,则直接从ClickHouse中读取
3. 如果查询的分钟线数据是既有当日的又有历史的,则合并数据返回给Client
"""
try:
today = date.today()
start_date = start_time.date()
end_date = end_time.date()
redis_data = []
clickhouse_data = []
# 1. 查询当日数据(从Redis读取)
if end_date >= today:
redis_data = self.redis_manager.get_current_bar_data(period, symbol)
# 过滤时间范围
redis_data = [bar for bar in redis_data if start_time <= bar.frame <= end_time]
# 2. 查询历史数据(从ClickHouse读取)
if start_date < today:
# 避免与当日数据重复,历史数据查询到今天之前
hist_end_time = min(end_time, datetime.combine(today, datetime.min.time()))
if start_time < hist_end_time:
clickhouse_data = self.clickhouse_manager.query_bar_data(
symbol, start_time, hist_end_time, period
)
# 3. 合并数据
merged_data = self.data_merger.merge_bar_data(redis_data, clickhouse_data)
return QueryResponse(
success=True,
message=f"当日数据: {len(redis_data)} 条,历史数据: {len(clickhouse_data)} 条,合并后: {len(merged_data)} 条",
data=merged_data,
total_count=len(merged_data)
)
except Exception as e:
return QueryResponse(
success=False,
message=f"查询失败: {str(e)}",
data=[],
total_count=0
)
|
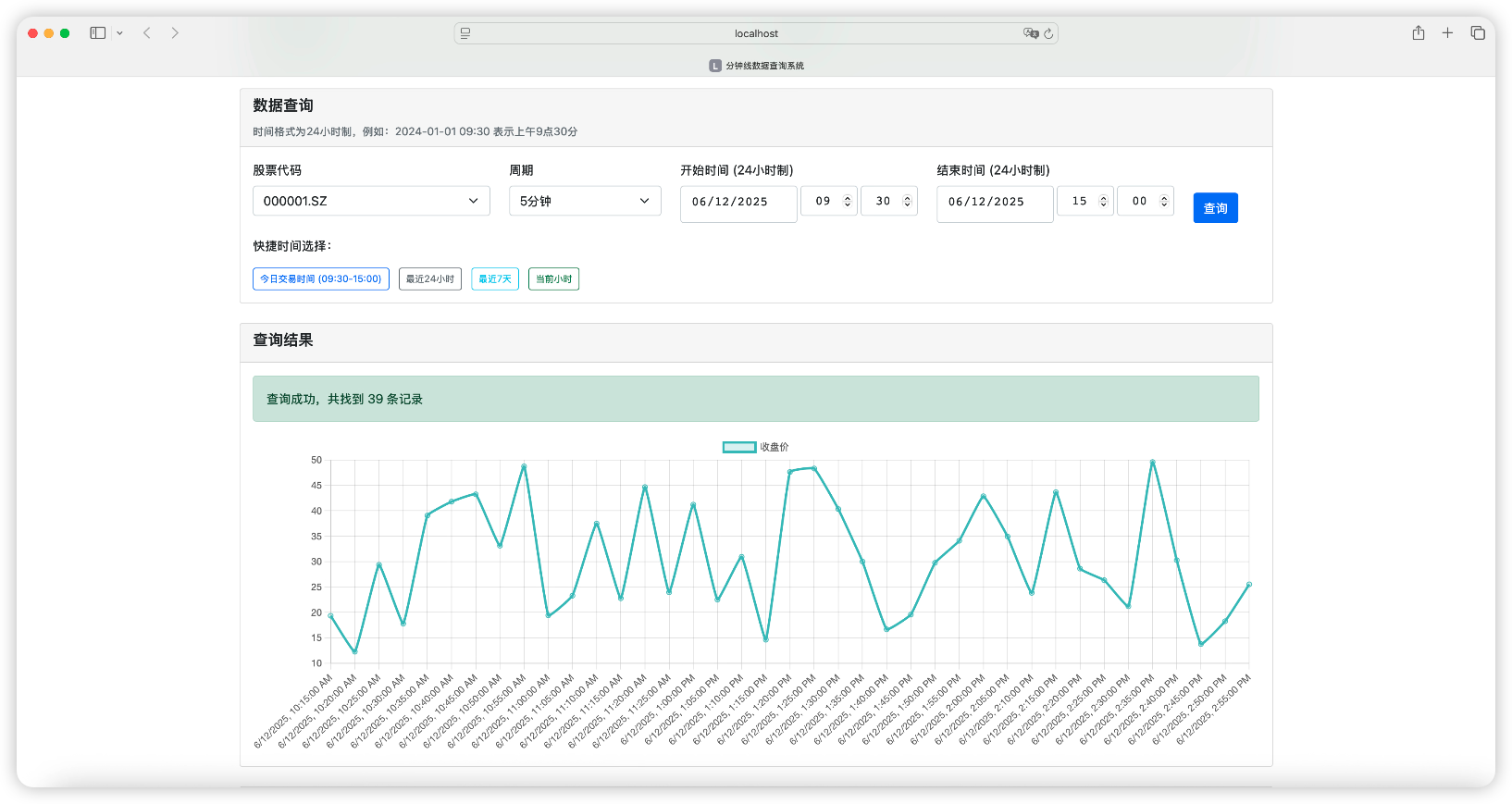
Client 端的查询页面
为了易于查询,且可视化查询结果,我让 007 给 Client 端设计了一个查询页面:
⚠️ 请注意:数据合并和交易时间验证
数据合并:确保查询结果的准确性
如果用户需要查询的日期既有历史分钟线数据又有当日分钟线数据,那么我们要对 Redis 和 Clickhouse 的数据进行合并。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | class DataMerger:
"""数据合并器 - 合并Redis当日数据和ClickHouse历史数据"""
@staticmethod
def merge_bar_data(redis_data: List[BarData], clickhouse_data: List[BarData]) -> List[BarData]:
"""合并分钟线数据"""
# 合并数据并按时间排序
all_data = redis_data + clickhouse_data
# 去重(以frame和symbol为键)
unique_data = {}
for bar in all_data:
key = (bar.symbol, bar.frame)
unique_data[key] = bar
# 按时间排序
merged_data = list(unique_data.values())
merged_data.sort(key=lambda x: x.frame)
return merged_data
|
交易时间验证:确保数据质量
"所有的分钟线数据都必须是交易时间内的数据,不然没有意义。"我对 007 强调了数据质量的重要性。
007 设计了一个专门的交易时间验证器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 | class TradingTimeValidator:
"""交易时间验证器"""
def __init__(self):
self.trading_hours = {
'morning_start': '09:30:00',
'morning_end': '11:30:00',
'afternoon_start': '13:00:00',
'afternoon_end': '15:00:00'
}
def is_trading_time(self, dt: datetime) -> bool:
"""检查是否为交易时间"""
time_obj = dt.time()
morning_start = dt_time.fromisoformat(self.trading_hours['morning_start'])
morning_end = dt_time.fromisoformat(self.trading_hours['morning_end'])
afternoon_start = dt_time.fromisoformat(self.trading_hours['afternoon_start'])
afternoon_end = dt_time.fromisoformat(self.trading_hours['afternoon_end'])
return (
(morning_start <= time_obj <= morning_end) or
(afternoon_start <= time_obj <= afternoon_end)
)
def validate_tick_data(self, tick_dict: dict) -> bool:
"""验证分笔数据"""
return self.is_trading_time(tick_dict['time'])
def validate_bar_data(self, bar_dict: dict) -> bool:
"""验证分钟线数据"""
return self.is_trading_time(bar_dict['frame'])
|
🎯 系统测试
"系统搭建完成,我们来测试一下效果。"我满怀期待地说道。
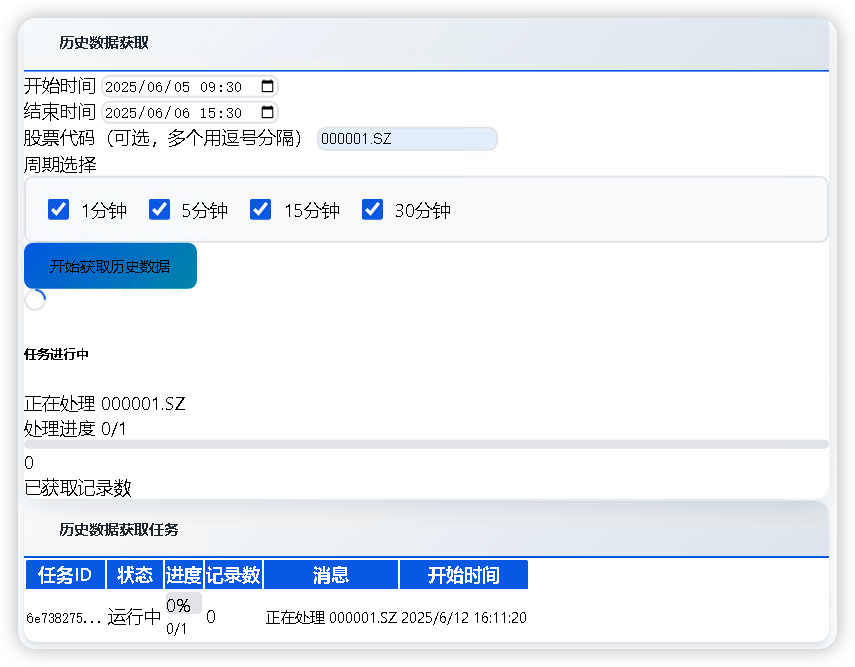
历史分钟线数据的获取
Windows 端运行效果:
Mac 端运行效果:
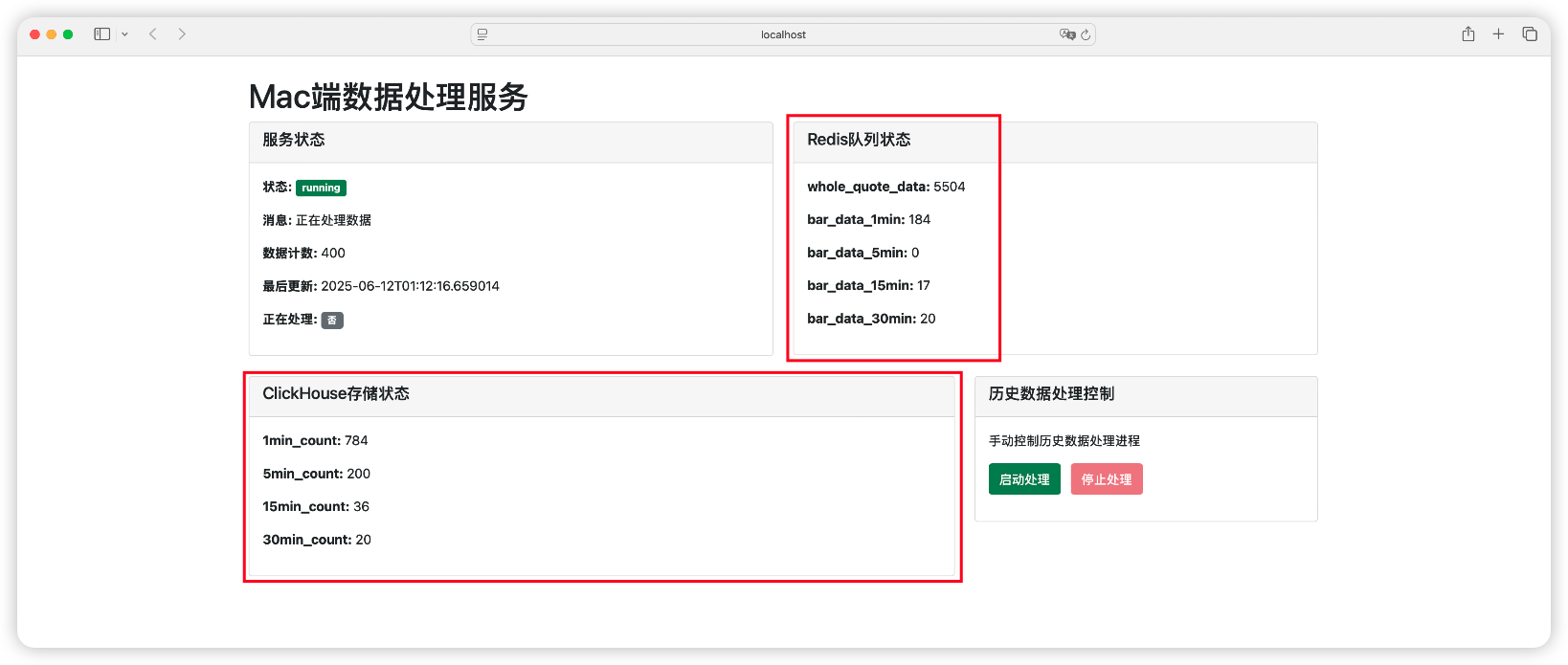
可以注意到 Mac 端的 Redis 队列中的元素正在减少,ClickhouseHouse 存储的数据正在增加。
我们再来看一下Clickhouse:
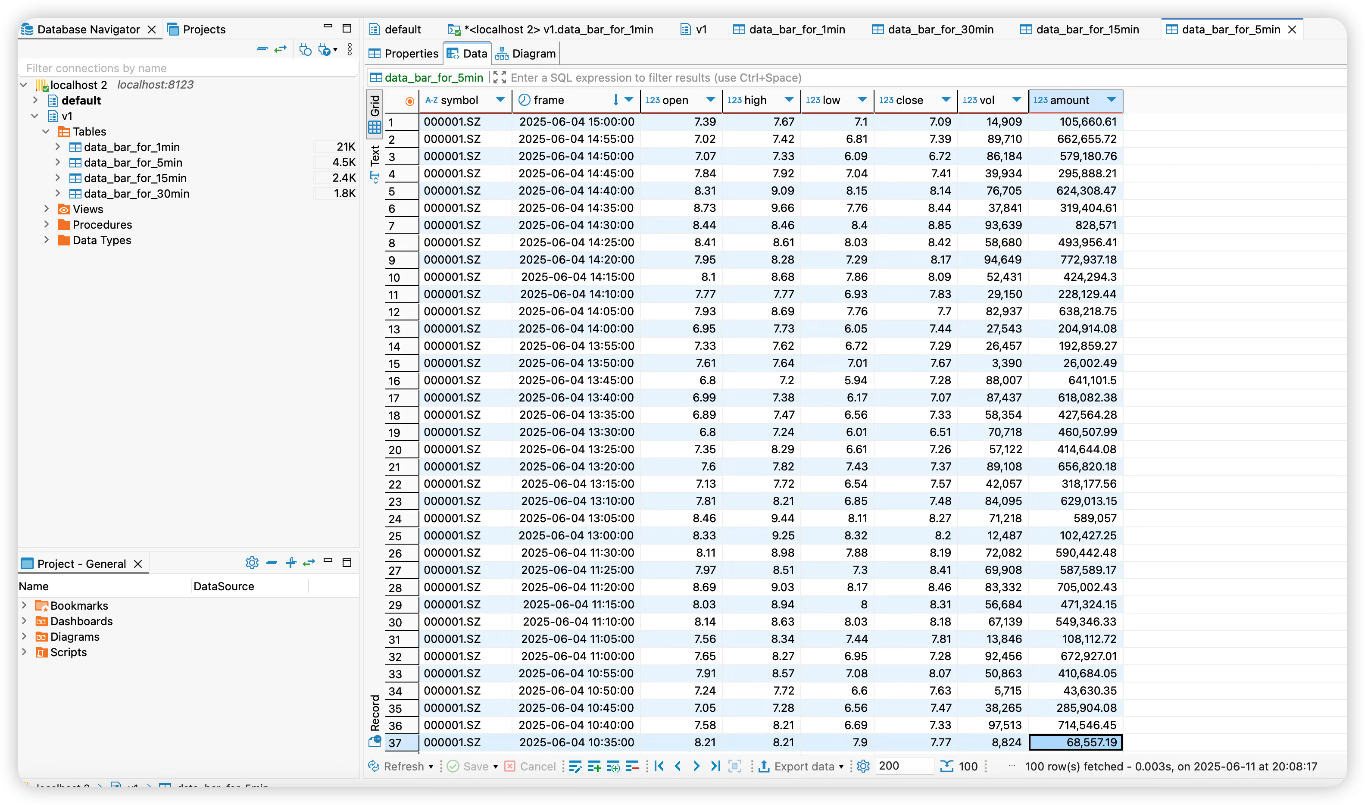
可以发现历史数据已经存入Clickhouse中(而且都是符合在交易时间内这一要求)。
当日分钟线数据的获取
在交易时间启动 Windows 和 Mac 端,可以看到 Redis 中保存着分笔数据和合成的当日分钟线数据。(这些数据到凌晨2点会统一清除)
Redis:
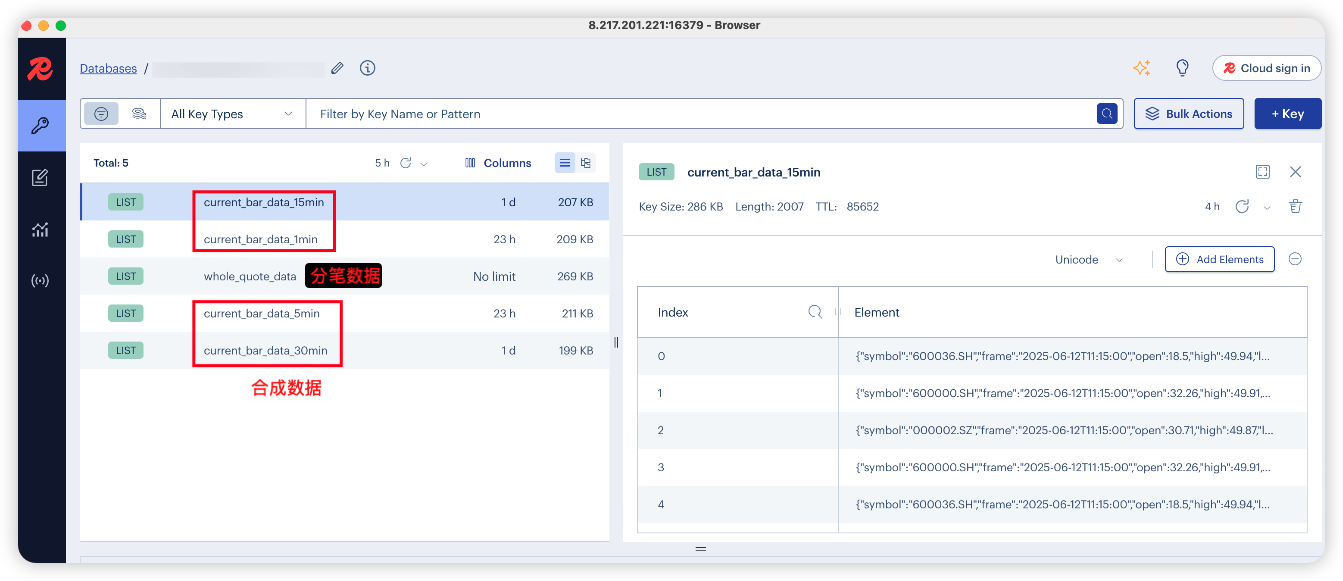
我们可以通过 Client 去查询当日的分钟线数据(以 15min 为例):

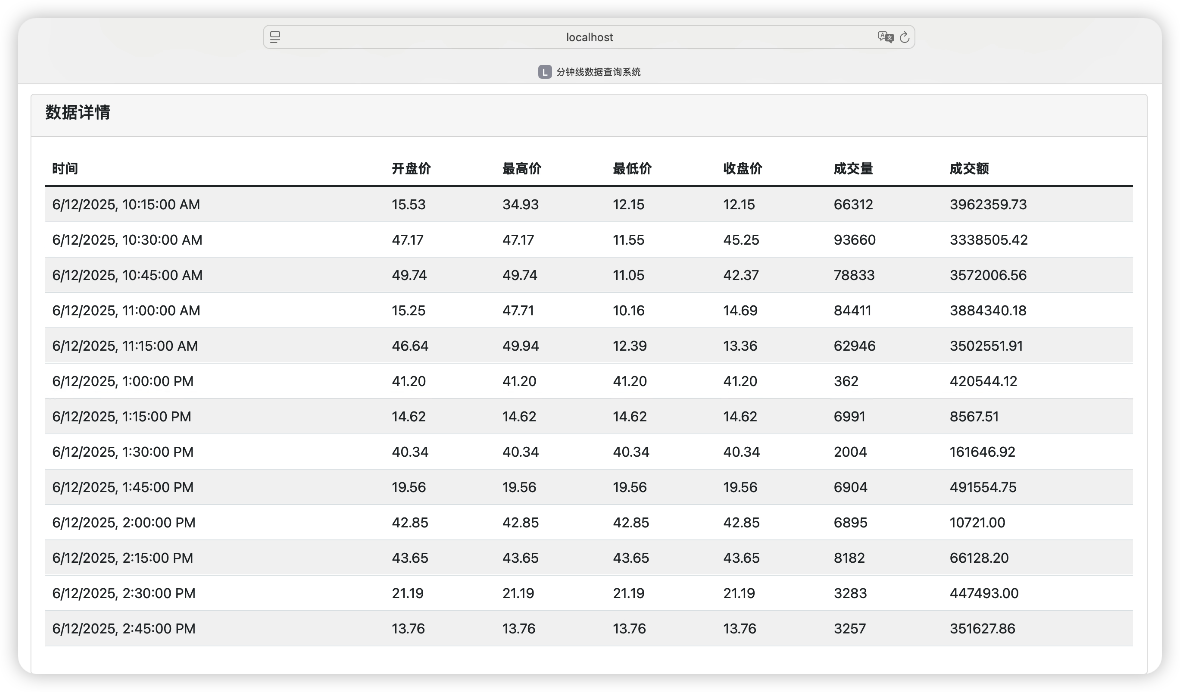
📝 总结
通过这次系统逻辑优化与分钟线数据合成的开发,我和 007 成功构建了一个智能、高效、稳定的量化交易数据处理系统。从最初的复杂设计到最终的简洁实现,我们不仅解决了技术难题,更重要的是建立了一套可扩展、可维护的系统架构。
21 天的挑战已经过去了 9 天,我们的量化交易系统正在变得越来越强大。从最初的简单数据获取,到现在的智能数据合成,每一步都充满了挑战和收获。
007 的表现再次让我刮目相看,从架构设计到代码实现,从问题诊断到系统优化,它都展现出了专业的技术能力。更重要的是,它能够在我的指导下快速调整方向,最终实现了一个简洁而强大的系统。
特别是在 Client 端的重构过程中,007 展现了很强的学习能力。当我指出代码过于复杂时,它能够立刻理解问题所在,并按照系统架构的原始设计进行彻底重构。这种快速响应和自我纠正的能力,正是一个优秀的 AI 助手应该具备的品质。
但是,我们的分钟合成真的合理吗?我们在下一章节,将采用 Tushare 和 Akshare 对我们合成的当日实时分钟线的准确性进行验证。对于多Client问题,我们也将采用多个Client机器对系统进行测试。敬请期待!
