样本外测试之外,我们还有哪些过拟合检测方法?
Table of Content
在知乎上看到一个搞笑的贴子,说是有人为了卖策略,让回测结果好看,会在代码中植入大量的if 语句,判断当前时间是特定的日期,就不进行交易。但奥妙全在这些日期里,因为在这些日期时,交易全是亏损的。
内容的真实性值得怀疑。不过,这却是一个典型的过拟合例子。
过拟合和检测方法¶
过拟合是指模型与数据拟合得很好,以至于该模型不可泛化,从而不能在另一个数据集上工作。从交易角度来说,过拟合“设计”了一种策略,可以很好地交易历史数据,但在新数据上肯定会失败。
过拟合是我们在回测中的头号敌人。如何检测过拟合呢?
一个显而易见的检测方法是样本外测试。它是把整个数据集划分为互不重叠的训练集和测试集,在训练集上训练模型,在测试集上进行验证。如果模型在测试集上也表现良好,就认为该模型没有拟合。
在样本本身就不足的情况下,样本外测试就变得困难。于是,人们发明了一些拓展版本。
其中一种拓展版本是 k-fold cross-validation,这是在机器学习中常见的概念。
它是将数据集随机分成 K 个大小大致相等的子集,对于每一轮验证,选择一个子集作为验证集,其余 K-1 个子集作为训练集。模型在训练集上训练,在验证集上进行评估。这个过程重复 K 次,最终评估指标通常为 K 次验证结果的平均值。
这个过程可以简单地用下图表示:
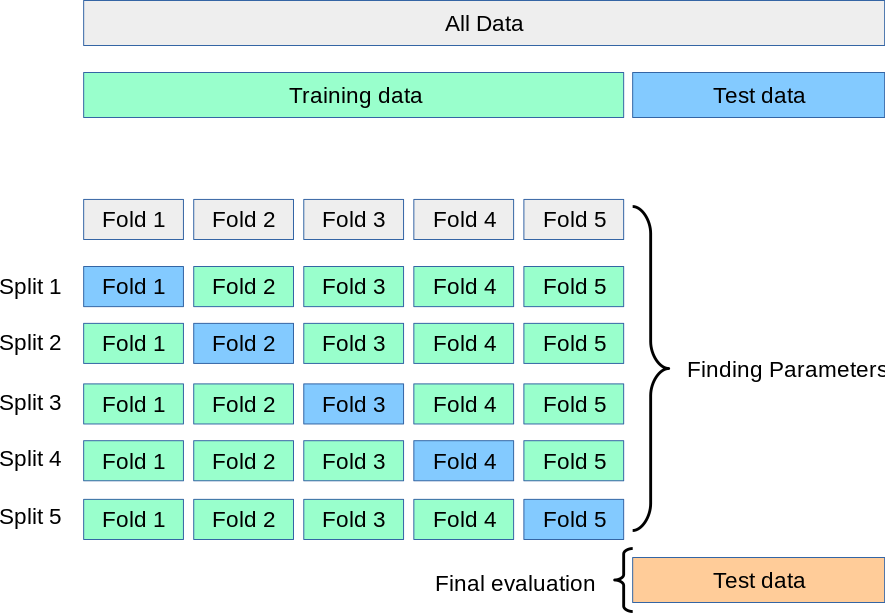
但在时间序列分析(证券分析是其中典型的一种)中,k-fold方法是不适合的,因为时间序列分析有严格的顺序性。因此,从k-fold cross-validation特化出来一个版本,称为 rolling forecasting。你可以把它看成顺序版本的k-fold cross-validation。
它可以简单地用下图表示:

从k-fold cross-validation到rolling forecasting的两张图可以看出,它们的区别在于一个是无序的,另一个则强调时间顺序,训练集和验证集之间必须是连续的。
有时候,你也会看到 Walk-Forward Optimization这种说法。它与rolling forecasting没有本质区别。
不过,我最近从buildalpha网站上,了解到了一种新颖的方法,这就是噪声测试。
新尝试:噪声测试¶
buildalpha的噪声测试,是将一定比率的随机噪声叠加到回测数据上,然后再进行回测,并将基于噪声的回测与基于真实数据的回测进行比较。
它的原理是,在我们进行回测时,历史数据只是可能发生的一种可能路径。如果时间重演,历史可能不会改变总的方向,但是偶然性会改变历史的步伐。而一个好的策略,应该是能对抗偶然性、把握历史总的方向的策略。因此,在一个时间序列加上一些巧妙的噪声,就可能会让过拟合的策略失效,而真正有效的策略仍然闪耀。
buildalpha是一个类似tradingview的平台。要进行噪声测试,可以通过图形界面进行配置。
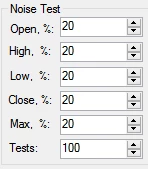
通过这个对话框,buildalpha修改了20%左右的数据,并且对OHLC的修改幅度都控制在用ATR的20%以内。最下面的100表明我们将随机生成100组带噪声的数据。
我们对比下真实数据与叠加噪声的数据。
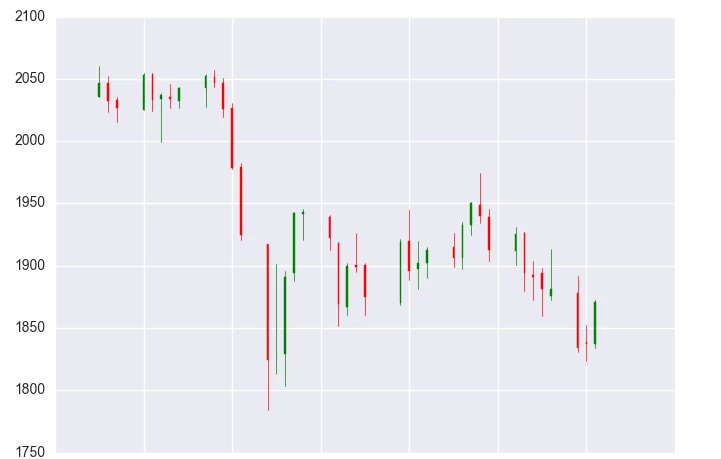
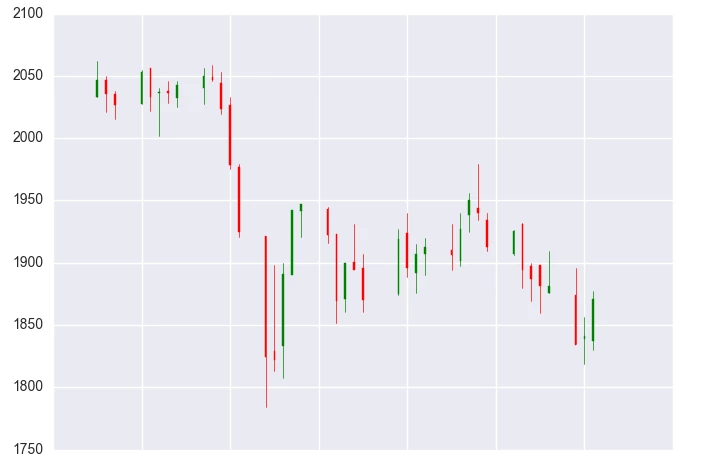
左图为真实数据,右图为叠加部分噪声的数据。叠加噪声后,在一些细节上,引入了随机性,但并没有改变股价走势(叠加是独立的)。如果股价走势被改变,那么这种方法就是无效的甚至有害的。
最后,在同一个策略上,对照回测的结果是:
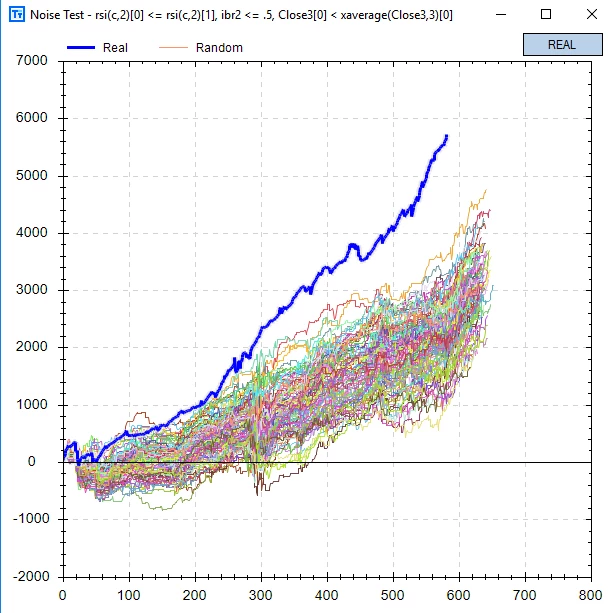
从结果上看,在历史的多条可能路径中,没有任何一条的回测结果能比真实数据好。换句话说,真实回测的结果之所以这么好,纯粹是因为制定策略的人,是带着上帝视角,从未来穿越回去的。
参数平原与噪声测试¶
噪声测试是稍稍修改历史数据再进行圆滑。而参数平原则是另一种检测过拟合的方法,它是指稍微修改策略参数,看回测表现是否会发生剧烈的改变。如果没有发生剧烈的改变,那么策略参数就是鲁棒的。
Build Alpha以可视化的方式,提供了参数平原检测。
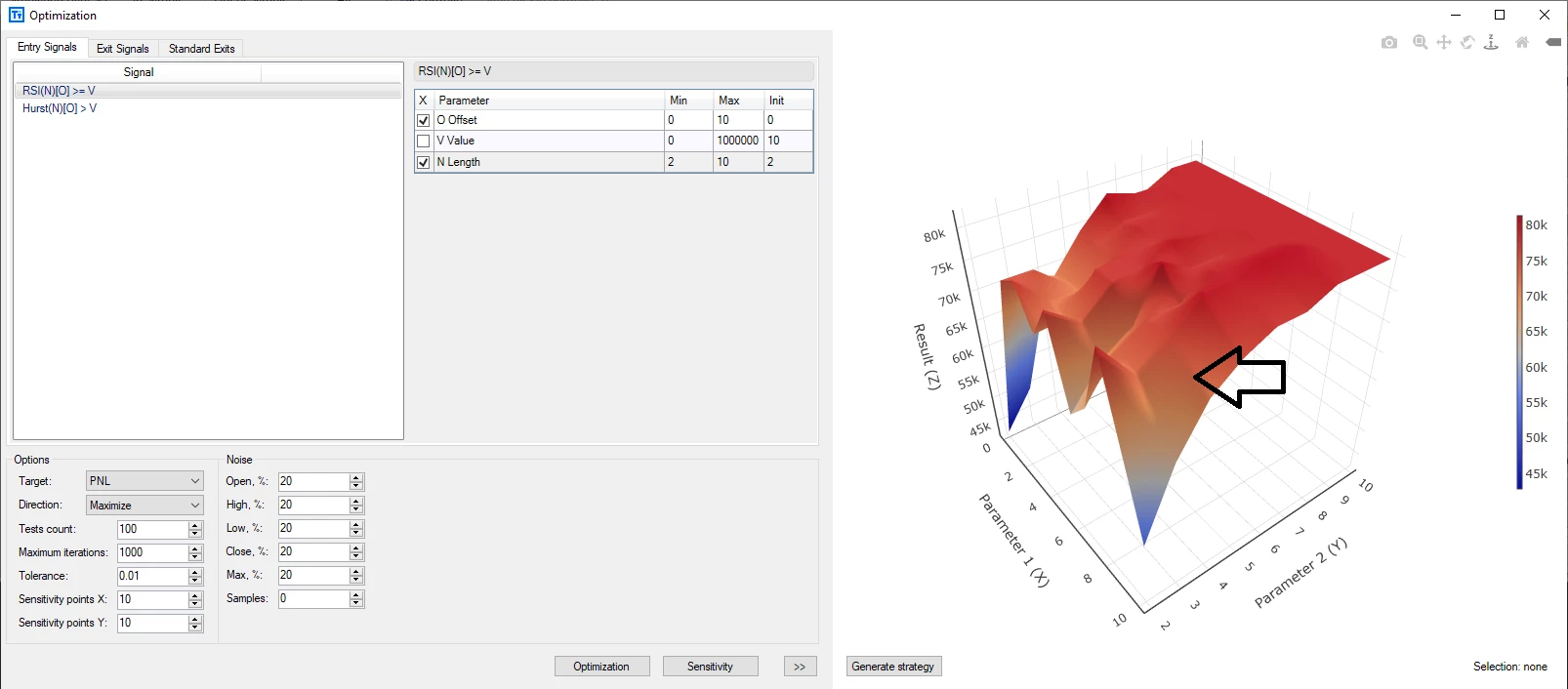
在这个3D图中,参数选择为 X= 9和Y=4,如黑色简单所示。显然,这一区域靠近敏感区域,在其周围,策略的性能下降非常厉害。按照传统的推荐,我们应该选择参数 X=8和Y=8,这一区域图形更为平坦。
在很多时候,参数平原的提示是对的 -- 因为我们选择的参数,其实价格变化的函数;但它毕竟不是价格变化。最直接的方法是,当价格发生轻微变化时,策略的性能如果仍然处在一个平坦的表面,就更能说明策略是鲁棒的。
不过,这种图很难绘制,所以,Build Alpha绘制的仍然是以参数为n维空间的坐标、策略性能为其取值的三维图,但它不再是基于单个历史数据,而是基于一组历史数据:真实历史数据和增加了噪声的数据。在这种情况下,我们基于参数平原选择的最优参数将更为可靠。
本文参考了Build Alpha网站上的两篇文章,噪声测试参数优化和噪声测试,并得到了 Nelson 网友的帮助,特此鸣谢!