12 - Pandas核心语法[2]
Table of Content
1. Series 的基本功能¶
本节,我们将介绍Series的一些数据的基本操作方法。后续将会深入地挖掘pandas在数据分析和处理方面的功能。
1.1. 重建索引¶
重建索引是通过 reindex() 方法实现的,它允许用户根据新的索引标签对 Series 进行重排或填充。如果新索引标签在原 Series 中不存在,默认会用 NaN 填充。
| 参数 | 描述 | 默认值 |
|---|---|---|
| index | 新的索引标签列表,可以是 Index 实例或其他序列型数据结构。 | None |
| method | 填充缺失值的方法,可选值包括:'backfill'/'bfill'(后向填充)、'pad'/'ffill'(前向填充)、'nearest'(最近填充)。 | None |
| fill_value | 用于填充缺失值的默认值。 | NaN |
| limit | 使用填充方法时的最大填充距离。 | None |
| tolerance | 最大容差,超出此范围则不填充。 | None |
| level | 如果索引是 MultiIndex,则指定使用哪一级别进行重新索引。 | None |
| copy | 如果为 True,即使新旧索引相同也会返回一个新的副本。 | True |
示例 1:基本重建索引
1 2 3 4 5 6 7 8 | |

示例 2:使用填充方法 对于时间序列这样的有序数据,重建索引时可能需要做一些插值或填值处理。method选项可以达到此目的,例如使用ffill可以实现前向填充。
1 2 3 | |

示例 3:指定填充值
1 2 3 | |
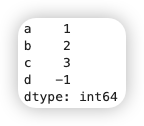
1.2. 删除指定轴上的项¶
在 Pandas 中,Series 删除指定轴上的项可以通过 drop() 方法实现。Series 是一维数据结构,因此删除操作通常是针对索引(行)进行的。
drop() 方法用于删除指定的索引标签,并返回一个新的 Series,不会修改原对象。其语法如下:
1 | |
- labels: 要删除的索引标签,可以是单个标签或标签列表。
- axis: 指定操作的轴,对于 Series 只能是 0(默认值),表示删除行。
- inplace: 如果为 True,则直接在原对象上修改,不返回新对象。
- errors: 如果指定标签不存在,
raise会抛出错误,ignore会忽略错误。
1 2 3 4 5 6 7 | |
1.3. 索引、选取和过滤¶
[索引选取] Series索引的工作方式类似于Numpy数组的索引,只不过Series的索引值可以不仅仅是整数:
1 2 3 | |
Series 的选取可以通过以下方式实现: - 基本选取:使用 [] 运算符。 - 属性选取:使用 . 运算符(仅适用于标签为合法变量名的情况)。 - iloc 和 loc:分别用于位置索引和标签索引。
1 2 3 4 5 | |
[索引过滤] Series 的过滤可以通过以下方式实现:
- 布尔索引:使用布尔条件筛选数据。
- 条件表达式:结合条件表达式进行过滤。
- isin() 方法:筛选值是否在指定列表中。
- where() 和 mask() 方法:根据条件替换或保留数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
1.4. 算数运算和数据对齐¶
1 2 3 4 5 6 7 | |
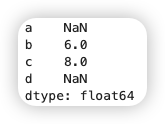
如果你使用过数据库,可以认为这类似于join操作。
如果不想得到 NaN,可以使用 fill_value 参数指定一个默认值来填充缺失的索引:
1 2 | |
Notes
pandas 的isnull和notnull函数可以用于检测缺失数据,不妨来试一试!
1.5. 排序和排名¶
Series 的排序可以通过以下两种方式实现:(1) 按索引排序:使用 sort_index() 方法。(2) 按值排序:使用 sort_values() 方法。
[按索引排序]
sort_index() 方法用于对 Series 的索引进行排序。默认情况下,索引按升序排列。
1 2 3 4 5 6 7 | |
参数: - ascending:是否升序排序,默认为 True。 - inplace:是否在原对象上修改,默认为 False。
[按值排序]
sort_values() 方法用于对 Series 的值进行排序。默认情况下,值按升序排列。
1 2 3 4 | |
参数: - ascending:是否升序排序,默认为 True。 - inplace:是否在原对象上修改,默认为 False。 - na_position:缺失值的位置,默认为 last(排在最后)。
[排名]
Series 的排名通过 rank() 方法实现,它为每个值分配一个排名,支持多种排名方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
参数: - method:排名方法,可选值包括: - 'average'(默认):相同值分配平均排名。 - 'min':相同值分配最小排名。 - 'max':相同值分配最大排名。 - 'first':相同值按出现顺序分配排名。 - 'dense':相同值分配相同排名,且排名不跳跃。 - ascending:是否升序排名,默认为 True。 - na_option:缺失值的处理方式,可选 'keep'(保留)、'top'(排在最前)、'bottom'(排在最后)。
1.6. 带有重复标签的轴索引¶
直到目前为止,几乎所有示例的轴标签(索引值)都是唯一的。虽然许多pandas函数(如reindex)都要求标签唯一,但这并不是强制性的。观察下面这个带有重复索引值的Series:
1 2 | |

索引的is_unique属性可以告诉我们索引值是否唯一:
1 | |
对于带有重复值的索引,数据选取操作将会有些不同。如果某个标签对应多个项,则返回Series;如果对应于单个项,则返回标量值:
1 2 | |
