01 - 这是你的量化母语
Table of Content
正如死亡和税收不可避免,Numpy 和 Pandas 对量化人而言,也具有同样的地位 -- 每个量化人都不可避免地要与这两个库打交道。
如果你去研究一些非常重要的量化库,比如 alphalens, empyrical, backtrader, tushare, akshare, jqdatasdk 等,或者一些非常优秀的量化框架比如 quantaxis, zillionare, vnpy 等等,你就会发现它们都依赖于 numpy 和 pandas。实际上,一个库只要依赖于 pandas,它也必将传递依赖到 numpy。
如果说量化人有一种共同的语言的话,它就是 Numpy 和 Pandas。Numpy 和 Pandas 是量化人的母语。
具体地说,Numpy 和 Pandas 不仅为量化人提供了类似于表格的数据结构 -- Numpy structured array 和 Pandas DataFrame -- 这对于包括行情数据在内的诸多数据的中间存储是必不可少的;它还提供了许多基础算法。
比如:
- 在配对交易 (pair trade) 中,相关性计算是非常重要的一环。无论是 Numpy 还是 Pandas 都提供了相关性计算函数。
- 在 Alpha 101 因子计算中,排序操作是一个基础函数 -- 这是分层回测的基础 -- Pandas 通过 rank 方法来提供这一功能。
- Maxdrawdown(最大回测)是衡量策略的重要指标。Numpy 通过 numpy.maximum.accumulate 提供了支持。
类似常用的算法非常多,我们将在本课程中一一介绍它们。
课程编排说明¶
紧扣量化场景来介绍 Numpy 和 Pandas 是本课的一大特点。我们通过分析重要的、流行度较高的量化库源码,找出其中使用 numpy 和 pandas 的地方,再进行归类的提炼,并结合一些量化社区中常问的相关问题 -- 这些往往是量化人在使用 numpy/pandas 时遇到的困难所在 -- 来进行课程编排,确保既系统讲解这两个重要的库,又保证学员在学习后,能立即将学习到的方法与技巧运用到工作中,迅速提高自己的生产力。
任何高效地学习都离不开高强度的练习。本课程安排了大量的练习。无论是演示代码、还是练习,我们都尽可能安排在量化场景下完成,这样会增强您的代入感。但是,这往往也要求您能理解这些场景和数据。
在编写本课程时,作者阅读了大量书籍、博文、论文和开源项目代码。其中一部分与教材关联度较高的,我们以延伸阅读、脚注的方式提供参考链接。如果学员有时间,也可以阅读这部分内容,以获得跟作者同样的视野景深。但如果你时间紧张,也完全可以跳过这些内容,只关注我们课程内容的主线就好。
本课程是专门为量化交易从业者,比如 quant developer, quant researcher 和 quant pm 等人设计。如果您有基础的金融知识,这门课也适用于其它需要学习 Numpy 和 Pandas 的人。课程内容在丰度和深度上都是市面上少见的。
什么是 Numpy¶

图片来源:numpy.org
Numpy 是 Python 科学计算中的基础包,它是一款开源软件,允许在保留原有版权声明的前提下,自由使用。它的名字来源于 Numeric Programming(数值编程),其前身是 Numeric 库和 Numarray 库。
Numpy 提供了多维数组对象、各种派生对象(比如掩码数组 -- masked array)以及各种用于数组操作的高性能例程,包括数学、逻辑、形状操作、排序、选择、I/O 、离散傅里叶变换、基本线性代数、基本统计运算、随机模拟等等。下图提供了一个更详细的说明:
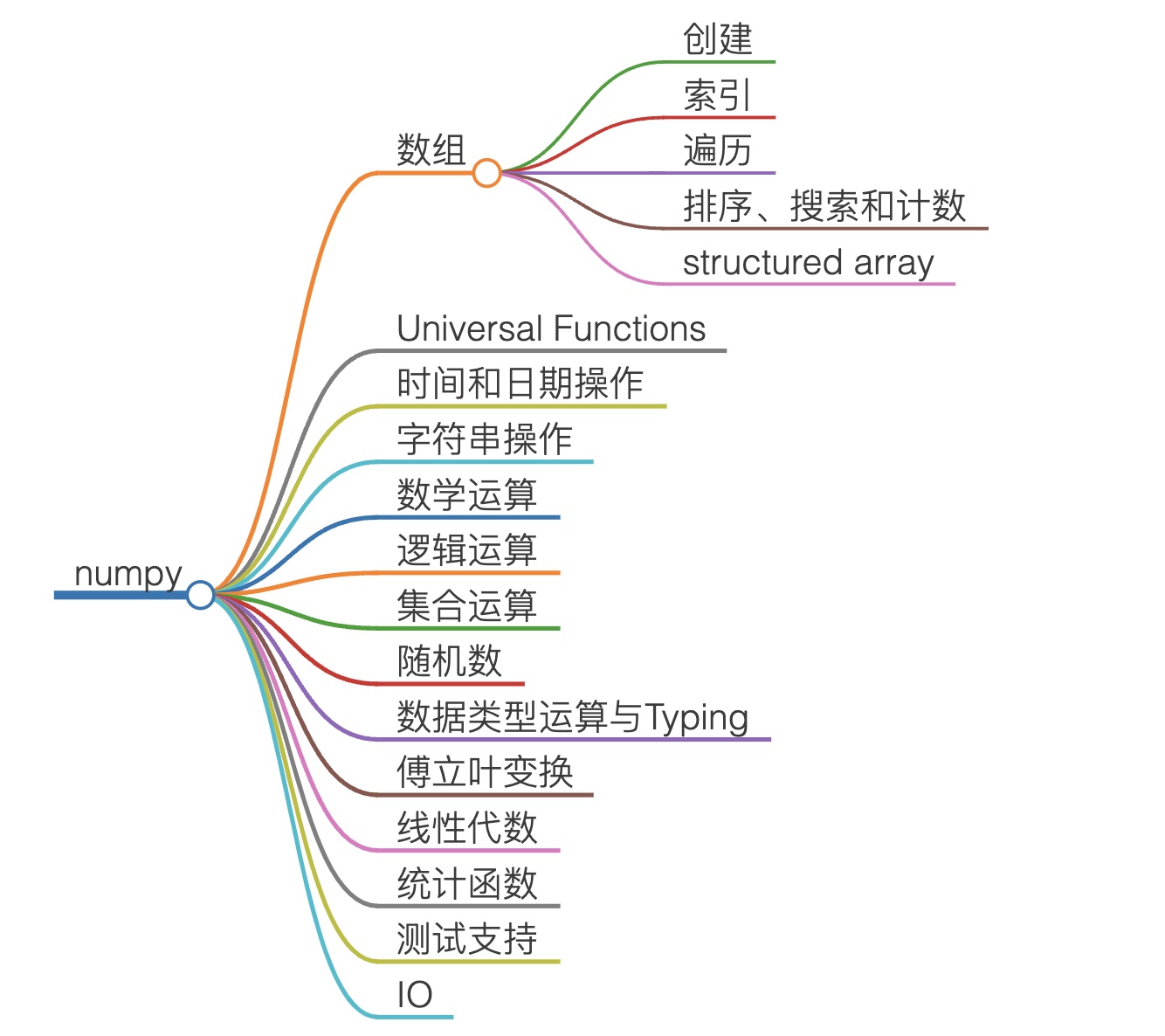
Numpy 的底层开发语言是 C 语言,并且进行了相当多的优化,这包括并行化支持、使用 OpenBLAS 和高级 SIMD 指令来优化矩阵操作等等。由于 Python 这种胶水语言的灵活性,使得 Numpy 最终得以作为一个 Python 库发布出来。
Tip
很多人认为要提高量化策略的性能,就必须放弃 Python,改用 C/Rust。这种说法又对又不对。
如果一个 Quanter 不懂得利用 OpenBLAS 和 LAPACK,那么即使用 C 开发出来的算法,也很难比通过 Python 调用 Numpy 来得更快。在 Numpy 中,一个最常见的矩阵乘法,就可能利用到多核机器的并行运算能力(即多线程)和高级 CPU 指令以实现快速的 BLAS/LAPACK 运算。这些知识和技巧,是一般人难以掌握的。
你可以通过下面的方法来查看你的 Numpy 是否利用了 OpenBLAS/LAPACK 及高级 SIMD 指令:
1 2 | |
Numpy 广泛运用于学术界、金融界和工业界,具有成熟、快速、稳定和活跃的特点。当前的稳定版本是 2.2.0 版(2025 年 3 月),发布于仅仅 1 个季度之前,这足以说明 Numpy 社区开发的活跃度。
Numpy 还是 Pandas, scipy, statsmodels 和 scikit-learn 等众多知名 Python 库的底层依赖库。
什么是 Pandas¶
Pandas 是用于数据操作和分析的 Python 软件库。它构造在 Numpy 之上,增加了索引、异构数组等功能(相当于 Numpy 的 Structure Array -- 这个概念我们会在本课程后面详细解释),这使它成为处理表格类数据的有力武器。
Pandas 的名字来源于术语 Panel Data(面板数据)和 Python Data Analysis,前者是计量经济学的一个术语,用以表示对同一个体在多个时期观测的数据集。
自 2010 年成为开源项目以来,pandas 已经发展成为相当大的一个库,开发者社区已发展到超过 2500 名不同的贡献者。
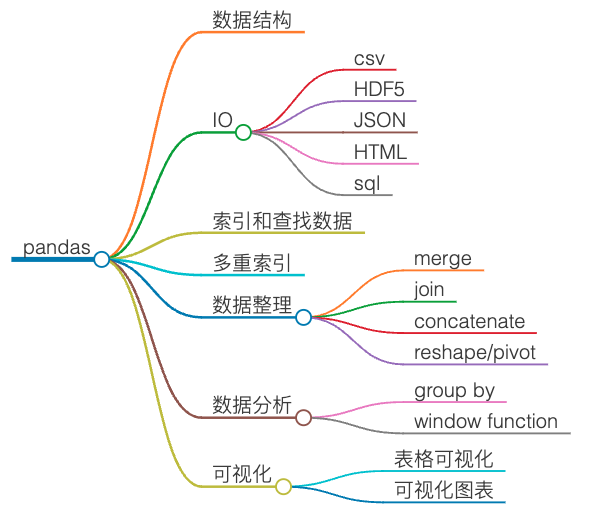
Pandas 提供了 Series, DataFrame 两种数据结构。它曾经还提供了 Panel 这种三维数据结构,但最终放弃了。与 Excel 相比,它能更快速地分析更大的数据(一般小于 1 千万行,主要取决于机器的物理内存)。
延伸阅读¶
 来源:Github readme 项目
来源:Github readme 项目
如果要推荐一本讲解 Pandas 的书,毫无疑问,没人任何书籍能比 《Python for Data Analysis》 更权威了。因为它是由 Pandas 的创建者 Wes McKinney 撰写的!这本书现在提供有网页版供开放访问。读者也可点击 此链接 阅读。在 2023 年 4 月进行更新后,它现在支持到了 pandas 2.0 版本。
Wes Mckinney 是 Pandas 的创建者和终生仁慈独裁者。他现在居住在田纳西的纳什维尔,是 DataPad 的 CEO 和联合创始人。
Wes Mckinney 本科毕业于 MIT,是数学和统计学博士(杜克大学)。在 AQR 资本管理公司工作期间,学习了 Python 并开始构建 pandas。他同时还是 Apache Arrow 的联合创建者。
从 Pandas 的诞生史来看,毫无疑问,Pandas 就是为金融/量化而生的。Wes Mckinney 创建 Pandas 的初衷,就是要解决用 Microsoft Excel 来进行金融数据分析和统计运算时效率低、并且十分繁琐的问题。在今天,量化巨头 Two Sigma[^two-sigma] 是这个项目的重要赞助商。Pandas 的成功,也促进了 Python 的广泛流行。甚至可以说,Mckinney 以一己之力,开拓了 Python 的生存空间。
创建 Pandas 并没有任何收益,Wes Mckinney 最初主要依靠第一份工作的存款和兼职来生活。这是一个类似于《月亮和六便士》的故事,就连主人公的背景都极其相似,都是金融工作者。幸运地是,Wes Mckinney 获得了成功。如果你对这段故事感兴趣,可以阅读 《可持续发展的开源项目将赢得未来》 这篇文章。