tools »
18 - Pandas应用案例[1]
“Alphalens 要求因子数据是双重索引的 Series,价格数据是日期为索引、资产代码为列的 DataFrame。通过 Pandas 的 pivot_table 和 set_index,可以轻松完成格式转换,为因子分析奠定基础。”
1. 通过rolling方法实现通达信例程
通达信 是一款由中国深圳市财富趋势科技股份有限公司开发的金融投资软件,主要用于股票、期货等金融市场的行情分析、技术研究和交易执行。通达信在国内券商中的覆盖率超过80%,服务包括招商证券、广发证券等头部机构。支持超5000万投资者,峰值并发用户达800万,以界面简洁、行情更新快著称。适用于个人投资者、专业交易员及量化分析,尤其适合需要快速响应行情和技术分析的场景。
rolling 是 pandas 库中用于执行滚动窗口计算的核心方法,适用于时间序列或数据框的滑动统计分析。以下是其核心要点:
- 功能:对数据按固定窗口大小(如时间周期或观测值数量)滑动,并在每个窗口内执行聚合或自定义计算(如均值、极值等)
- 典型应用:移动平均、波动率计算(标准差)、技术指标(如MACD)等。
核心参数:
| 参数 | 说明 |
| ----------- | ------------------------------------------------------- |
| window | 窗口大小(整数或时间偏移,如 '5D') |
| min_periods | 窗口内最少有效数据量,否则结果为 NaN(默认等于 window) |
| center | 窗口对齐方式(False为右对齐,True为居中) |
| win_type | 窗口权重类型(如 'gaussian') |
1.1. HHV(N周期内最高值)
通达信定义:HHV(X, N) 表示在最近 N 个周期内序列 X 的最高值。可以通过 pandas 实现:
| def HHV(s: pd.Series, n: int) -> pd.Series:
return s.rolling(n).max()
|
1.2. LLV(N周期内最低值)
通达信定义:LLV(X, N) 表示在最近 N 个周期内序列 X 的最低值。
| def LLV(s: pd.Series, n: int) -> pd.Series:
return s.rolling(n).min()
|
1.3. HHVBARS(最高值到当前周期的距离)
通达信定义:HHVBARS(X, N) 表示最近 N 个周期内,最高值所在位置到当前周期的距离(周期数)。
| def HHVBARS(s: pd.Series, n: int) -> pd.Series:
def _find_idx(x):
return len(x) - np.argmax(x[::-1]) - 1 if not np.isnan(x).all() else np.nan
return s.rolling(n).apply(_find_idx, raw=True)
|
1.4. LAST(条件连续满足的周期数)
通达信定义:LAST(X, A, B) 表示过去 B 个周期中,有至少 A 个周期满足条件 X。
| def LAST(condition: pd.Series, a: int, b: int) -> pd.Series:
return condition.rolling(b).sum() >= a
|
1.5. 示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | import pandas as pd
import numpy as np
# 导入数据
start = datetime.date(2023, 1, 1)
end = datetime.date(2023, 12, 31)
df = load_bars(start, end)
df.tail()
# 应用函数
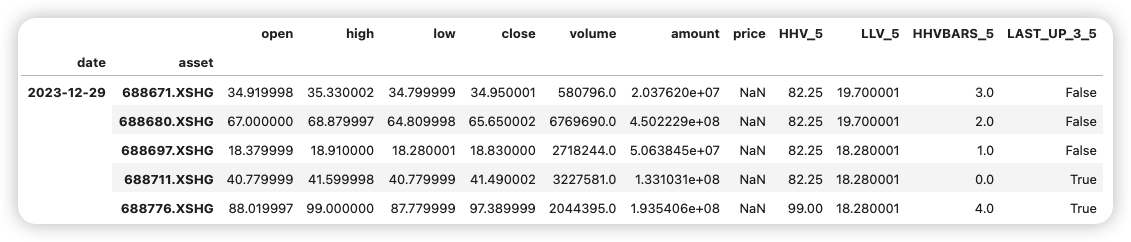
df['HHV_5'] = HHV(df['high'], 5) # 5日最高价
df['LLV_5'] = LLV(df['low'], 5) # 5日最低价
df['HHVBARS_5'] = HHVBARS(df['high'], 5) # 最高价距离当前的天数
df['LAST_UP_3_5'] = LAST(df['close'] > df['close'].shift(1), 3, 5) # 5日内至少3日上涨
print(df)
|
2. 补齐分钟线缺失的复权因子
量化分析中,可能在处理股票分钟线数据时,复权因子数据存在缺失,需要根据时间进行临近匹配,确保每个分钟数据点都有正确的复权因子。复权因子通常是在股票发生拆分或分红时调整的,这些事件的时间点可能不会正好匹配分钟线的每个时间戳,例如:
- 复权因子生效时间:2025-03-27 10:30:00(事件触发时刻)
- 分钟线时间戳:2025-03-27 10:30:01、10:30:02(交易数据)
Tip
传统 merge 或 join 方法无法匹配此类时间邻近但非严格相等的数据,需用 as-of join 功能解决。使用 merge_asof 可以找到每个分钟线时间点之前最近的复权因子,确保正确应用调整。
merge_asof 是 Pandas >=0.19.0 引入的时间导向非精确匹配函数,专为此类场景设计。
2.1. 基础语法和示例
2.1.1. 基础语法
| pd.merge_asof(
left, # 左表(分钟线数据)
right, # 右表(复权因子数据)
on='time', # 时间列名(必须排序)
direction='backward', # 匹配方向:向前/向后/最近
tolerance=pd.Timedelta('1min'), # 最大时间差
allow_exact_matches=True # 是否允许精确匹配
)
|
2.1.2. 基础示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | import pandas as pd
import numpy as np
# 生成示例数据(假设复权因子在非整分钟时间点更新)
minute_data = {
'time': [
'2025-03-27 10:29:58', # 完整日期+时间
'2025-03-27 10:30:01',
'2025-03-27 10:30:03',
'2025-03-27 10:30:05',
'2025-03-27 10:30:08' # 确保所有时间包含日期
],
'price': [100.2, 101.5, 102.0, 101.8, 103.2]
}
df_trade = pd.DataFrame(minute_data).sort_values('time')
adjust_data = {
'time': [
'2025-03-27 10:29:55',
'2025-03-27 10:30:00',
'2025-03-27 10:30:06'
],
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25 | 'adjust_factor': [1.0, 0.95, 1.02]
}
df_adjust = pd.DataFrame(adjust_data).sort_values('time')
# 强制转换为 datetime 类型(处理混合格式)
df_trade['time'] = pd.to_datetime(
df_trade['time'],
format='%Y-%m-%d %H:%M:%S',
errors='coerce'
)
df_adjust['time'] = pd.to_datetime(
df_adjust['time'],
format='%Y-%m-%d %H:%M:%S',
errors='coerce'
)
assert df_trade['time'].dtype == 'datetime64[ns]', "交易数据时间列转换失败"
assert df_adjust['time'].dtype == 'datetime64[ns]', "复权因子时间列转换失败"
# 关键步骤:按时间向前匹配最近的复权因子
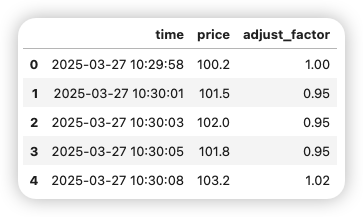
merged = pd.merge_asof(
df_trade,
df_adjust,
on='time',
direction='backward', # 取<=当前时间的最近值
tolerance=pd.Timedelta(minutes=1) # 最多允许1分钟间隔
)
merged
|
2.2. 进阶技巧
2.2.1. 多标的匹配(股票代码分组)
| # 假设数据包含多只股票
merged = pd.merge_asof(
df_trade.sort_values('time'),
df_adjust.sort_values('time'),
on='time',
by='symbol', # 按股票代码分组匹配
direction='backward'
)
|
2.2.2. 动态调整因子生效时间
若复权因子生效时间需要提前或延后,可预处理右表时间:
| df_adjust['time'] = df_adjust['time'] + pd.Timedelta(seconds=30) # 延后30秒生效
df_adjust
|
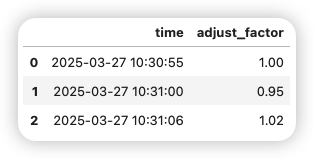
2.2.3. 处理缺失值
| merged['adjust_factor'] = merged['adjust_factor'].ffill() # 前向填充缺失值
|
2.3. 与其他方法对比
| 方法 |
适用场景 |
优点 |
缺点 |
| merge_asof |
时间邻近匹配 |
处理非对齐时间戳效率高 |
需预先排序数据 |
| merge |
精确时间匹配 |
结果精确 |
无法处理时间偏差 |
| concat |
简单堆叠 |
快速合并 |
不处理时间关联 |
3. 为Alphalens准备数据
在使用Alphalens进行因子分析时,我们往往需要将因子数据和价格数据整理成特定的格式。Alphalens要求因子数据是一个具有双重索引(日期和资产)的Series,而价格数据是DataFrame,行是日期,列是资产,值是价格。这一点非常重要,如果格式不对,Alphalens会报错。
因此,我们需要知道如何从原始数据转换到这种格式。这里我们考虑使用pivot_table来转换价格数据,以及使用set_index来创建因子数据的双重索引。
3.1. 数据格式规范(Alphalens 强制要求)
3.1.1. 因子数据格式
需构建双重索引的 Series,索引顺序为:日期 -> 资产代码,值为因子数值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
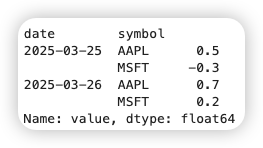
15 | # 原始数据示例(含日期、股票代码、因子值)
raw_factor = pd.DataFrame({
'date': ['2025-03-25', '2025-03-25', '2025-03-26', '2025-03-26'],
'symbol': ['AAPL', 'MSFT', 'AAPL', 'MSFT'],
'value': [0.5, -0.3, 0.7, 0.2]
})
# 转换为Alphalens格式
factor = raw_factor.set_index(['date', 'symbol'])['value']
factor.index = pd.MultiIndex.from_arrays(
# 确保日期为datetime类型
[pd.to_datetime(factor.index.get_level_values('date')),
factor.index.get_level_values('symbol')]
)
factor
|
3.1.2. 价格数据格式
需构建 日期为索引、资产代码为列名 的 DataFrame:
| # 原始数据示例(含日期、股票代码、收盘价)
raw_price = pd.DataFrame({
'date': ['2025-03-25', '2025-03-25', '2025-03-26', '2025-03-26'],
'symbol': ['AAPL', 'MSFT', 'AAPL', 'MSFT'],
'close': [150, 280, 152, 285]
})
# 转换为Alphalens格式
prices = raw_price.pivot(index='date', columns='symbol', values='close')
prices.index = pd.to_datetime(prices.index) # 日期转换为datetime类型
|
3.2. 关键预处理操作
3.2.1. 时间索引对齐
| # 检查时间范围是否重叠
print("因子时间范围:",factor.index.get_level_values('date').min()
, "~", factor.index.get_level_values('date').max())
print("价格时间范围:",prices.index.min(), "~", prices.index.max())
|
| # 若存在时间缺口,用前向填充(避免未来数据)
prices = prices.ffill()
|
3.2.2. 异常值处理
| # Winsorize去极值(保留98%数据)
factor_clipped = factor.clip(
lower=factor.quantile(0.01),
upper=factor.quantile(0.99)
)
# 标准化处理(Z-score)
factor_normalized = (factor - factor.mean()) / factor.std()
|
3.2.3. 缺失值处理
| # 删除缺失值超过50%的资产
valid_symbols = factor.unstack().isnull().mean() < 0.5
factor = factor.loc[:, valid_symbols[valid_symbols].index.tolist()]
# 前向填充剩余缺失值
factor = factor.groupby(level='symbol').ffill()
|
3.3. 高级操作技巧
3.3.1. 多因子
1
2
3
4
5
6
7
8
9
10
11
12 | # 假设存在动量因子和市值因子
factor_mom = ... # 动量因子数据
factor_size = ... # 市值因子数据
# 横向拼接为MultiIndex列
combined = pd.concat(
[factor_mom.rename('momentum'), factor_size.rename('size')],
axis=1
)
# 转换为双层索引
combined = combined.stack().swaplevel(0, 1).sort_index()
|
3.3.2. 行业中性化处理
| # 假设有行业分类数据
industries = pd.Series({
'AAPL': 'Technology',
'MSFT': 'Technology',
'XOM': 'Energy'
}, name='industry')
# 按行业分组标准化
factor_neutral = factor.groupby(
industries, group_keys=False
).apply(lambda x: (x - x.mean()) / x.std())
|
3.4. 数据验证与接口对接
3.4.1. 格式验证
| # 检查因子索引层级
assert factor.index.names == ['date', 'symbol'], "因子索引命名错误"
# 检查价格数据类型
assert prices.columns.dtype == 'object', "价格数据列名应为资产代码"
|
3.4.2. Alphalens 接口调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14 | from alphalens.utils import get_clean_factor_and_forward_returns
# 生成分析数据集
factor_data = get_clean_factor_and_forward_returns(
factor=factor,
prices=prices,
periods=(1, 5, 10), # 1/5/10日收益率
quantiles=5, # 分为5组
filter_zscore=3 # 剔除3倍标准差外的异常值
)
# 生成完整分析报告
import alphalens
alphalens.tears.create_full_tear_sheet(factor_data)
|
3.5. 常见问题解决方案
| 问题现象 |
解决方法 |
| ValueError: 价格数据包含未来信息 |
检查价格数据时间戳是否晚于因子时间戳,用prices = prices.shift(1) 滞后一期 |
| KeyError: 资产代码不匹配 |
使用prices.columns.intersection(factor.index.get_level_values('symbol')) 取交集 |
| 图表显示空白 |
在Jupyter Notebook中运行,并添加%matplotlib inline 魔术命令 |
通过上述操作,可高效完成从原始数据到Alphalens兼容格式的转换,确保因子分析的准确性。实际应用中建议先在小样本数据上测试,再扩展至全量数据。