研报复现之如何正确筛选『连续两年分红』股票(附代码)
Table of Content
这个系列的跨度有点久了,在开始之前,先做一个前情提要。这个系列我们选择的是中金2023年12月的一份研报,名为《在手之鸟,红利优选策略》。它是一个基本面策略,通过这份研报的实现,我们可以了解到:
Abstract
- 如何获取各种基本面数据,并且对部分数据的含义及编纂方法进行讲解
- 月度调仓换股回测策略应该如何实现
- 获得一个红利优选基础策略。通过适当改变参数,即可用以实战。
该策略要用到以下数据:
- 行情数据。任何策略都默认需要它,至少会在计算远期收益时使用。
- 股息率,用来按股息率筛选个股,以及计算两年股息率均值因子。
- 分红数据。只有过去两年连续分红的公司才能入选。
- 审计意见。只有过去十年没有审计保留意见的公司才能入选。
- 市值数据。只有市值大于50亿的公司才能入选。
- 净利润、营业收入和营业利润数据,用来计算净利润稳定性因子。
- 股东数量变化
- 换手率。用来计算换手波动率。
- pe_ttm,用来计算 ep 因子。
- 经营现金流数据,用来计算经营现金流资产比因子。
- 资产总计数据,与10一起,用来计算经营现金流资产比因子。
- 盈余公积金数据。与11一起,用来计算留存收益资产比因子。
1 2 3 4 5 6 7 | |
在前面的分期文章中,我们已经获得了第1~2步的数据,并实现了按股息率进行票池筛选。回测表明,仅仅是通过股息率因子,我们就可以获得一定的年化超额,和更好的夏普比。
在这一期,我们将探讨如何把分红数据也纳入进来。研报要求,只有过去两年连续分红的公司才能入选票池。这是一个看似简单,但实现上有一点点复杂度的需求。这里实际上有一些魔术师的戏法,荟聚了多个 pandas的技巧,才为一个简单的需求,提供了简洁的实现,而这也正是作者一直追求的目标。
获取分红数据¶
在上一篇中,我们已经获取了股息率数据,但要实现『连续两年分红』这个条件,为精确起见,我们不能把『连续两年股息率大于零』来当成『连续两年分红』,而是要直接获取分红原始记录。
Info
通过 daily_basic 获得的股息率是一个按过去12个月滚动计算的股息率。根据它的计算方式,就可能存在这样的情况,比如2023年12月进行了分红,2024年全年没有分红,但是直到2024年11月,股息率都会一直大于零。如此一来,在2025年2月,当我们问道,该股是否连续两年分红时,就会得到一个错误结果。在这方面,分红记录可能略微精确一点。
在 tushare 中,我们要通过 dividend 接口来获取分红数据。回测发生在2018年到2023年之间,我们再一次遇到如何在 tushare 中,获取这么长跨度的数据的问题。根据我们之前的讨论,我们应该选择一次查询可以获得最多数据的接口(参数)。
该接口签名如下:
```{code-block} python def dividend(ts_code: str|None = None, ann_date: str|None = None, record_date: str|None = None, ex_date: str|None = None, imp_ann_date: str|None = None): pass
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
可以看到,使用 end_date 参数,可以获得的数据远远超过其它参数;但是,它的limit 并不是我们常见的6000,而是只能返回2000。这些行为上的不一致,是我们要注意的。
由于这里的 limit 只有2000,而现在 A 股有5000多支个股,所以,我们在通过 end_date获取数据时,还必须通过 offset/limit 多次调用,才能取全一天的数据。
下面的代码演示了如何取区间[start, end]之间的数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Attention
在本系列前面的章节中,我们在计算[start, end]之间的日期列表时,一般使用 bdate_range。它将获取一个排除了周六、周日的日期列表(但显然它不懂黄金周)。使用它来获取交易数据是 OK 的。但是,基本面数据可能发表在任何一天,所以,在这里,我们必须遍历全部日历,才能确保不漏掉一条数据。你有没有犯过类似的错误,从而不得不为排错浪费掉一个周末呢?
在最后,我们对数据进行了一些处理,使得返回的数据包含 asset, date 这两列,以便我们能像其它数据一样,自动化地利用缓存。
现在,我们就用之前开发的缓存来保存这些数据:
```{code-block} python
本段代码已在课程环境中运行,数据已缓存,请勿重复运行¶
path = data_home / "rw/dividend.parquet" store = ParquetUnifiedStorage(store_path = path)
for yr in (2018, 2019, 2020, 2021, 2022, 2023): start = datetime.date(yr, 1, 1) end = datetime.date(yr, 12, 31)
1 2 | |
print(store.start, store.end) store
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
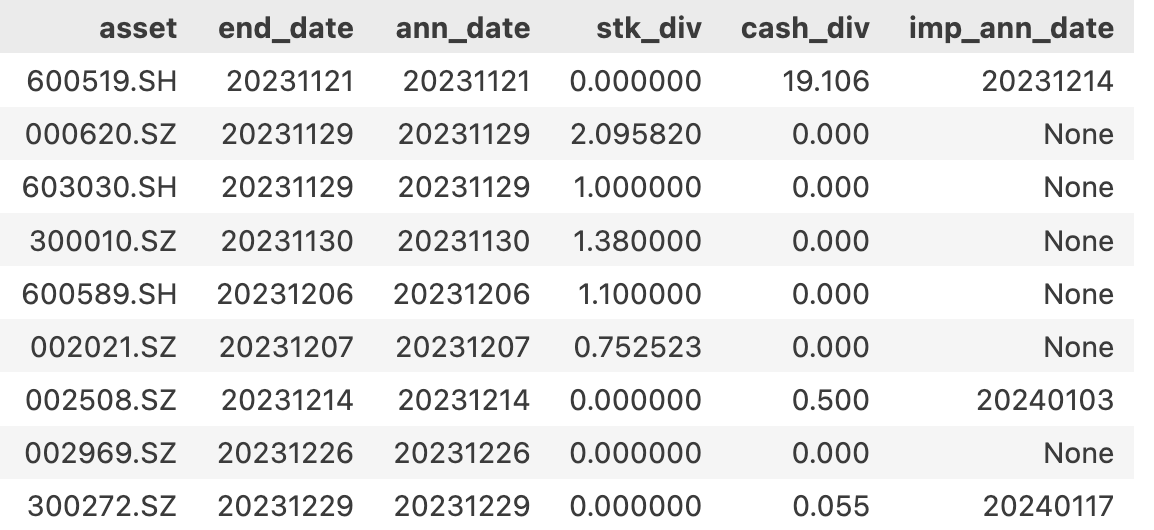 原始分红记录
原始分红记录
分段获取的原因是为了保证万一出错,我们也不会损失太多数据。
文档没有说明这些记录是如何编纂的。根据我们的分析,公司可能在一年内有多次分红(可惜这样的公司太少了,所以你才不得不放弃价值投资,转学量化!);对每一次分红,它可能有多条记录,分别对应于预案、股东大会通过和实施三个阶段。
对我们本次需求来说,只要关注『预案』阶段的记录就好。因为预案一旦发布,相关炒作资金就会闻风而动,不会等到实施阶段。在预案中,我们又只需要关注 end_date, ann_date,这是计算是否有连续两年分红的关键。
但是,请注意在示例代码,我们保存的是 div_proc 取值等于『实施』的记录。因为这条记录已经包含了预案阶段的全部信息,同时又提供了实施阶段的一些额外信息,还可以为今后其它用途使用。不过,我们要注意,在回测中,当我们把 ann_date 当成最新的时刻时,是不能去读 cash_div,record_date, ex_date 等信息的,此时它们还是『未来数据』
Tip
tushare 的记录中给出了税后分红(cash_div),但文档中并没有明确指出它的计算方法,欢迎讨论!按相关法规,企业与个人股东的分红税率不一样,个人股东持有时间长短不一样,分红税率也不一样。因此,理论上讲,每一个 cash_div_tax,都应该对应多个 cash_div -- 看谁来读它。
要如何判断某只股票是否连续两年分红呢?最好是通过一个数据实例。不过,在讨论之前,我们要对数据进行一些预处理,这样讨论起来才会更加清晰易懂。
预处理和生成索引¶
判断『是否连续两年分红』的关键是,在每个月末,判断前两个年度(或者今年、去年)的分红方案是否已宣布。如果是,则我们可以标记该月为『满足连续分红条件』,记为True;否则,记为 False。
因此,我们实际上只需要关心数据中的 asset, end_date 和 ann_date 三列,并且,为了比较和查找方便,我们应该将后二者分别转换为 fiscal_year(整数,对应的财年)和 announc_ym (宣布分红的年月)。
因此,我们要先进行以下转换:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
预处理的核心思想是把细粒度的时间数据转换成粗粒度的时间数据。这是月度回测中的核心技巧之一。在经过这样的转换之后,数据的查找、对齐和偏移计算就会易如反掌了。
其它值得注意的地方是,有一些个股会在一个财年,多次分红。这种情况下,我们需要进行去重,只保留最早的分红信息,因为最早的这条分红信息就足以说明财年有分红了。
这段示例的最后,我们截取了PAYH 的一小段记录。从这段记录,我们可以推断,在2022年3月之后直到当年底,我们都可以认为PAYH在2020年的2021年是满足连续两年都分红的条件的。但是,在2022年1月到2月,过去两年的财政年度是2020和2021年,但21年可能仍然会分红,只是财报暂时还没批露。这种情况下,我们应该认为 PAYH 是满足连续两年都分红的条件,还是不满足? To be or not to be,这还真是一个问题。而研报并没有给出答案。
在这里,我们只考虑大多数情况,那就是,如果是在当年的4月份前,未有分红记录的,只要前两年都有分红的,仍然按连续两年分红算。不过,凡事都有例外。好的公司年报预告会发得早;如果到了4月才发年报的,那么多数并不会有分红 -- 这相当于,如果倒数第三年、第二年经营业绩好,但倒数第一年经营业绩变差,我们必须延迟到4月底才能确认这一点。这会使得我们的策略引入一些不利的因素。
连续两年分红的逻辑的代码实现¶
刚刚我们对数据进行了一些预处理,在此基础上,讨论清楚了站在具体的时间节点上,『什么叫连续两年分红』。
现在,我们如何将这个逻辑代码化?
首先,明确我们的目标,是要得到这样一个输出:对每一个 asset的每一个month,存在一个标记(flag),能指出该 asset 在该month 时,是否满足连续两年分红的条件。
我们来看看这个结果表格应该长什么样:
1 2 3 4 5 6 7 8 9 10 | |
接下来,我们把前面得到的关于 fiscal_year 和 announce_ym 的表格展开到与上述 result_df 对齐。对齐之后,剩下的计算就会变成是从一个表格映射到另一个表格那样简单。
1 2 3 4 5 6 7 8 9 10 | |
现在,我们只需要对上述展开后的 dataframe,按 asset 进行 groupby,然后在每个分组中,启用一个大小为24的滑动窗口,再判断索引 month 是否在滑动窗口的 fiscal_year 集合内即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
这段代码中,值得注意的地方有两处。首先,当提到『滚动』求值时,我们很容易想到使用滑动窗口。但在第7行处,我们使用循环,而不是rolling.apply 来找出对应行的前两年数值。因为 rolling.apply 一般应用于聚合操作,函数的返回值必须是数值型。
第2点就是第29行,它实际上仍然是一个循环。考虑到 calc_row_flag 只是在行内进行比较操作,这里可以进一步优化,以启用并行机制。在我的电脑上,这段代码运行了13秒,速度还是有点慢的。
如何验证这里的逻辑正确呢?对 PAYH,我们看到,从2020年3月起,每个月的 flag 都是1;这是正确的,因为它每一年都有分红。我们还找了一个反面的例子, 920819,这是它的分红记录:
1 2 | |
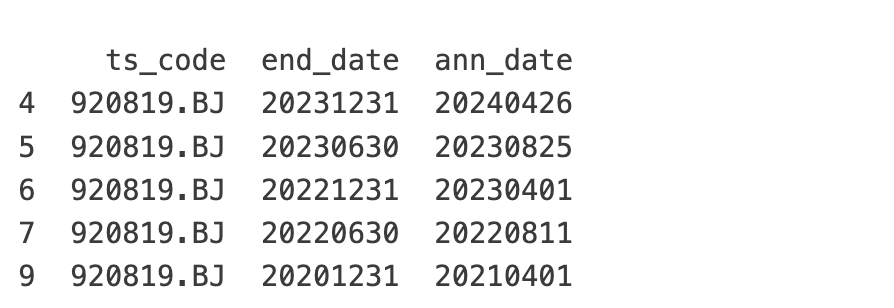
它在2020, 2022, 2024年都有分红,但在2021年没有分红(有预案,但没有通过)。所以,只有从2024年1月起,『连续两年分红』查询才显示它满足条件。
这证明了我们的实现是正确的。
应用分红筛选¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
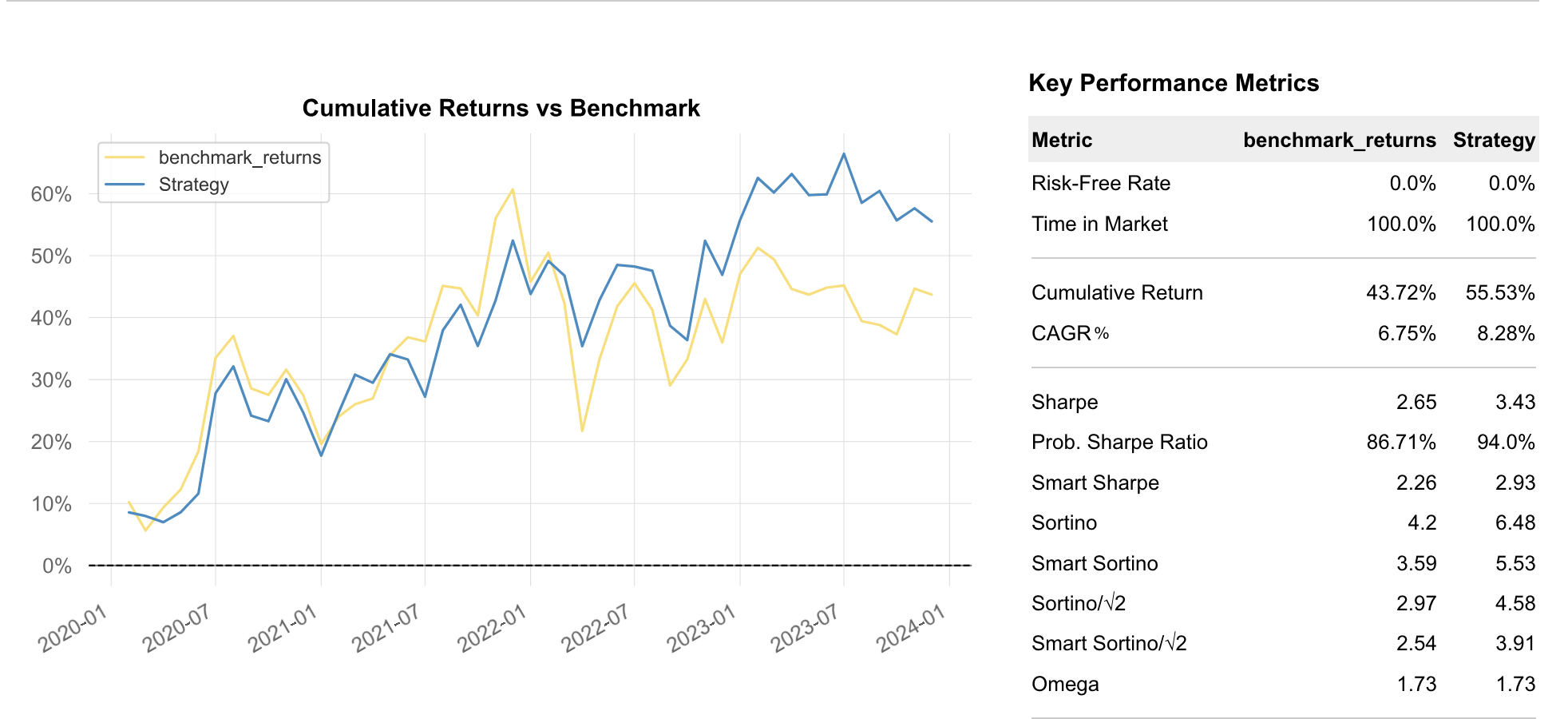
最终,我们得到以下报告:
Info
研究平台用户请双击 strategy_report.html 来查看更详细的报告。此文件可以 jupyter lab 的侧边栏中找到。
你也许已经发现,在加入新的筛选条件之后,策略的超额收益、相对夏普超额(如果可以这么说的话)都超过了前一期。尽管报告是这么说的,也确实应该如此,不过任何时候,在面对回测时的好消息时,你都应该再核对一遍:
这两次回测的时间区间不一样,所以,它们无法直接比较。尽管我们获取数据时,都使用了一样的起止区间,但是,『连续两年分红』筛选存在一个两年的『冷启动』期。它导致了策略必须在指定的起始时间之后两年才能开始回测。
尽管这里存在需要数据对齐的问题,幸运的是,Moonshot 默默承担了一切。
后记¶
如果你对本文代码感兴趣,可以加入会员,我们提供数据、代码和运行环境,立即运行和验证策略。如果对文中技术细节不太熟悉,可选修我们的课程。
