涨时重势,跌时重质,Moonshot首测股息率因子给出结论
Table of Content
Abstract
- 在 tushare 中如何获取股息率?如何利用其分页机制,加快取数据的速度?
- 如何实现按股息率筛选?特别介绍 pandas的transform 与 apply方法比较
- 股息率数据的 alpha
这是复现基本面月度调仓策略的第三篇。在第一篇里,我们介绍了月度调仓的核心思想。在第二篇里,我们介绍了研报要求的数据清单,并以 tushare 为例,介绍了如何获取日线行情数据,并且实现了数据增量更新的一个高性能、但又极简的框架。
现在,我们就进入到第二阶段,逐步增加因子,并进行回测。
我们首先要添加的是股息率,并且根据股息率来实现股票池的筛选。
获取股息率¶
在 tushare 中,我们有两种方案可以获取股息率。其一是通过 daily_basic 接口。其二是先通过 dividend 接口获取每股分红,再除以每股股价,即可得到股息率。
在这里,我们只演示第一种方法。但在后面实现按两年连续分红条件筛选公司时,我们会演示如何使用 dividend 接口。
daily_basic 接口可用来获取以日期为索引的一些常用数据,比如当日收盘价、换手率、市盈率、市值等大约15列数据。它的签名如下:
1 2 3 4 | |
其中 ts_code 与 trade_date 必选其一。与其它多数 tushare 函数一样,它有返回记录限制,目前是6000条。这样在一次存取中,可以取某支股票25年左右的数据,或者所有股票一天的数据。
Attention
一次可存取记录条数限制可能取决于你的账号。这里6000条是积分5000以上账号的限制。
下面的代码演示了如何获取股息率及 PE 等数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
大约每0.5秒能获取一天的数据。这样获取一年的数据,大约需要2分钟。
根据股息率筛选¶
现在,我们就实现按股息率筛选出每日前500名个股,然后用 moonshot 回测下,看看这样构建的股票池本身是否有价值。
1 2 3 4 5 6 7 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
这个筛选方法是 pandas 中常用的 groupby/apply 套路。类似的方法有 apply, transform ,agg和map等。它们的主要不同,在于对输入输出的类型不同。
map 只能接收 Series 对象作为输入,按单个元素进行转换映射,输出与输入长度一致;transform, agg, apply在输入上,既可以是 Series,也可以是 DataFrame; 但agg 会导致输出数据维度缩减;transform 则保持不变(一对一映射变换);而 apply 则较为灵活,输出形状较复杂。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
Moonshot 的代码很简单,但也很强大:要按股息率,在每月结尾时进行股票池筛选,筛选器函数的核心部分仅令4行代码即可完成。这得益于我们梳理出来的清晰的数据结构。
最终要应用这个筛选器也很简单。我们首先获取日线行情数据,初始化一个 Moonshot 对象,然后再获得同样频率下的 dv_ttm(即股息率)数据,通过 append_factor 方法将股息率数据添加到 Moonshot 中: 在这里,我们让 moonshot 框架自动完成了月线重采样以及数据的对齐操作。
最后,让 screen 方法开始工作,计算收益,绘制策略评估指标。由于 moonshot 在设计上使用了了链式调用,所以,这里的工作任务是一气呵成。
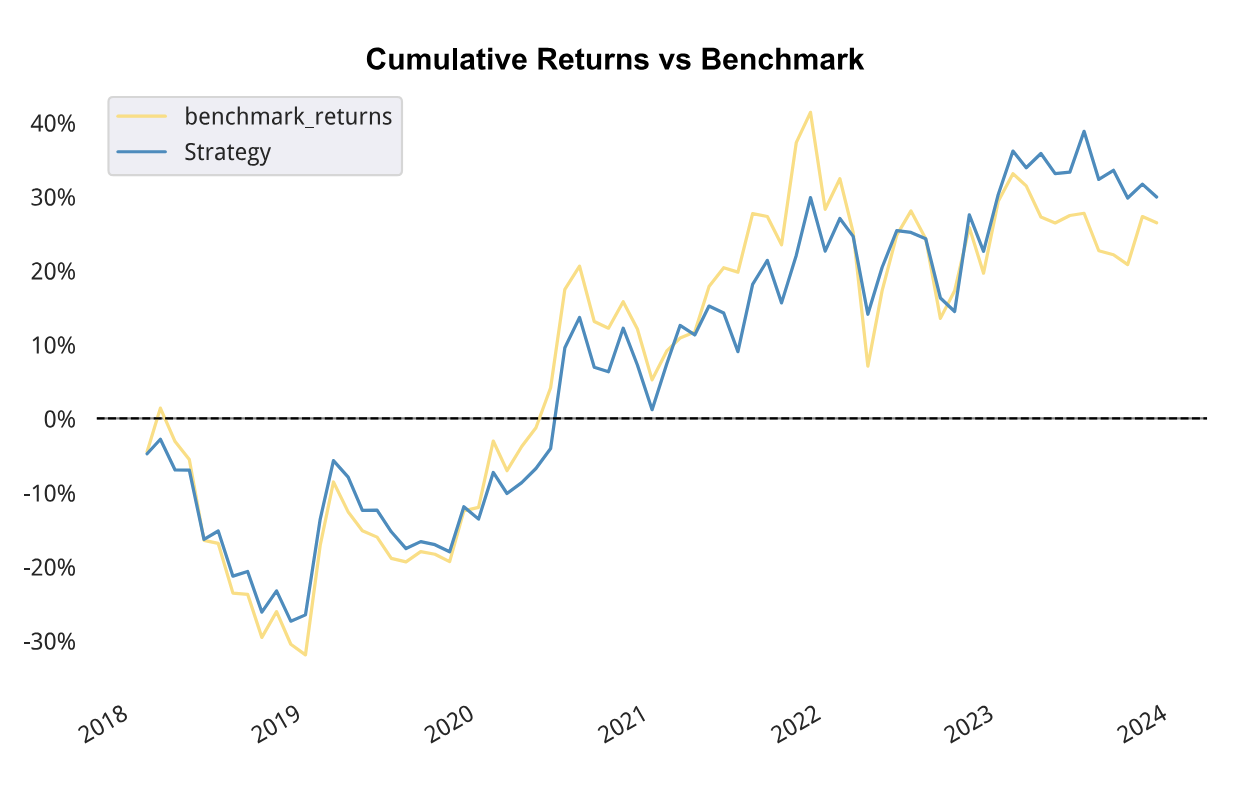
最后,策略报告显示,在2018年到2023年间,股息率筛选本身就具有一定的 alpha:
 累积收益对照
累积收益对照
从图中可以看出,在2018年、2022和2023年,下跌之中,股息率较高的个股更加抗跌;而在19年到2021年间,股市处于上涨之中,股息率高的个股,上涨就不如其它个股。
涨时重势,跌时重质。这句股谚在这张图中得到充分体现。
为什么在股市上升期,股息率较高的个股涨势不如其它个股?因为在这些个股中,存在相当比例的价值投资者,他们时刻会警惕价格有没有过度偏价值,从而股息率成为价格的锚定工具;而垃圾股的炒作全凭想像和故事,反倒不会受到任何锚定物的牵绊。
同样地,在股市下降期,股息率较高的个股不容易下跌:因为一旦价格向下过份偏离,价值投资者就会入场。
但长期来看,股息率较高的个股,累积收益会更高,存在显著的 alpha和夏普;而它们的波动更小,投资体验更好。时间的玫瑰,更值得拥有。
ParquetUnifiedStorage¶
ParquetUnifiedStorage是一个简单的本地存储方案。我们在上一篇文章中介绍过,在本节中我们进一步进行了拓展,使得它可以支持多种数据存取,并且能自动更新。
它的用法是,在定义 store 时,就传入一个回调函数,用来在本地缓存没有数据时,能够自动从数据源中获取数据。如此一来,调用者就只需要使用 store.load_data(start, end)就能自动获取在[start, end]区间的数据,同时又充分利用了缓存。这会是我们在进行小型研究,没有技术团队支持时的好帮手。
题外话: Tushare 中的分页读取¶
在 Tushare 中,数据查询一般会有6000条记录限制。但是,有一些查询允许指定 start_date 和 end_date 参数,这种情况下,返回数据集的大小并不确定,一旦时间跨度较长,数据集大小就会超过这个限制。
这种情况下,根据官方文档,我们可以通过修改查询条件,以减少查询返回数据集的大小,从而确保返回的数据集是完整的。比如,要获取 A 股所有个股一年的日线数据,我们可以按证券列表遍历,或者按日期遍历。这样每一次返回的结果集都是完整的;但是,这样一来,就不可避免地带来性能损失。比如,前者涉及到5000次左右的网络请求,后者涉及到250次左右的网络请求;按每次能返回的最大数据集行数算,实际上只需要225次左右的网络请求。所以,理论上还有至少10%的优化空间。
Tip
A 股是在最近几年才扩容到今天的5413家的。在2018年之前,上市股总数大约在1800家之间。所以,当我们遍历到那一年之前时,每次请求就只利用了不到1/3的返回容量,性能浪费就更大了。
分页查询的参数在正式文档中没有给出。但我们可以通过数据工具来查看某个 API 是否有支持分页.
在下面的截图中,左图显示了获取日线行情的 API daily的文档。在这里,我们发现它并不支持分页查询。但是,如果我们转到数据工具页面,就可以看到该 API 是支持分页查询的。
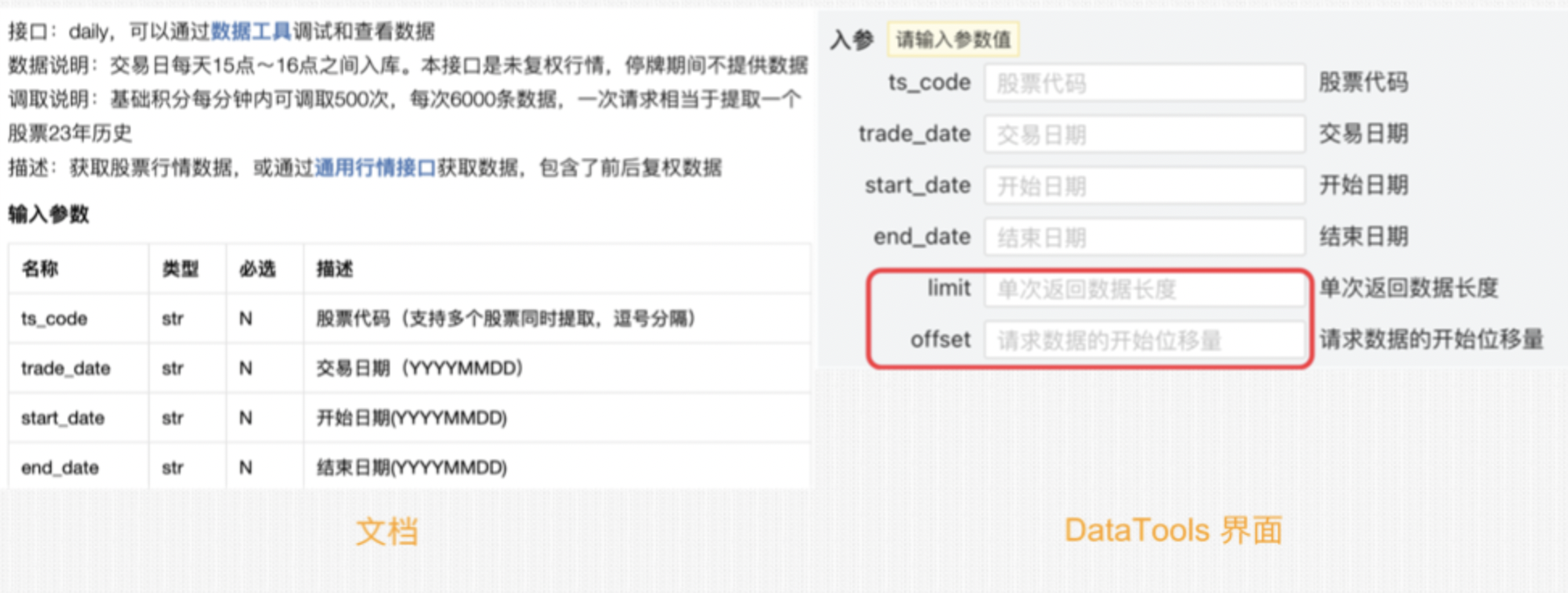
从图中可以看出,它用来实现分页的两个参数是 offset 和 limit。但是,这里还有一个隐藏的问题,就是 offset 本身也有最大限制,比如10万。这就给算法带来了额外的复杂度:我们必须考虑这样的情况,在一次[start, end]的查询中,理论上结果记录数应该是15万条,但实际上只能返回10万条,因此我们必须重新查询,但这10万条不知道会在哪一天截断,所以我们还要知道两件事:
- tushare 查询返回的时间顺序
- 截断日期怎么确定
下面的代码仅对此 API 有效。当我们运用到其它数据时,要考虑 tushare 返回结果的时间顺序,这会影响下一次查询区间的确定。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | |
在同样的起止区间(2019年10月8日到2019年12月31日)里,示例1需要45.5秒;示例2需要24秒左右。如果我们存取的时间区间更早一点,那么这个加速比还会更大一点,因为早期上市公司的数量更少。
不过,尽管如此,我们还是要谨慎对待这些参数的使用。至少需要准备好回归测试,以防在 tushare 修改接口时,能第一时间发现变化。