把研报『翻译』成代码,80%的工作都在这篇文章里讲了
Table of Content
如何读懂并复现研?这是我们学员提出来的一个问题。
读懂并复现一篇研报,在理解研报的核心思想之外,看懂高频常用术语(行话、俚语)、实现概念到代码的转换、懂得如何获得数据是占80%的常规工作。在上一篇《RSRS择时指标》中,我们的重点在于复现策略本身。这一篇文章,我们重点介绍如何『翻译』研报。
在《基于阻力支撑相对强度(RSRS)的市场择时》(以下称研报)这篇文章中,提到的术语主要有:通道线(布林带), 标准分,线性回归, ols线性回归,自由度,斜率,总收益,平均年化,夏普比率,最大回撤,净值,决定系数,均值,标准差,偏度,峰度,相关系数,右偏标准分。要读懂和复现这篇研报,就要理解这些术语和概念。
这里好些个术语是统计学的规范术语,比如线性回归,斜率,决定系数,均值,标准差等,在Python中,常常可以在numpy, scipy或者statsmodels中找到其实现。但我们要注意的是,不同的Python库,甚至Python库的不同版本,对于这些术语(概念)的代码实现,都可能存在一些差异(这也可能是我们复现不出来研报的原因之一)。
比如,在numpy的线性回归中,早期版本和后期版本中,返回的alpha和beta的顺序是不同的;在协方差的计算中,numpy版本和scipy版本在自由度取值的默认值上可能不同,等等。

其它的部分则是量化行业常用的术语,特别是一些策略度量指标,比如夏普、最大回撤等。这些在一些知名的第三方库中也有实现,我们在本文的后面部分介绍。
但在这些术语之中,有两个概念我们会在这篇文章里介绍一下,一个是delta,另一个是标准分。
从delta谈起¶
研报中第7页提到了\(\Delta\)(delta)这个概念,把\(\Delta_{high}/\Delta_{low}\)的值作为描述支撑位与阻力位的相对强度,即RSRS。这是全篇的基石,所以,我们需要着重分析一下。
在数学中,符号\(\Delta\)一般表示微小变化量或者增量,两个增量的比值的极限即为导数,从几何上看就是斜率。因此,研报在这里进一步解释道:
实际上,delta(high)/delta(low)是连接高低价格平面上的两点 (low[0],high[0])与(low[1],high[1])的斜率。
在量化场景下,我们有时候也会看到把\(\Delta_{close}\)(或者对其它量的\(\Delta\))称为导数,这是因为close在时间上的增量被当成1,所以两者在数值上相等的缘故。

如果我们已经有了这些概念,那么,就很容易理解当N为1时,RSRS的计算法则的。
然后,考虑到两点之间的斜率(即N为1的RSRS)过于不稳定,所以,研报提出,采用N个点的线性回归来计算斜率。在初等数学中,斜率是由单条直线上的两点在y轴和x轴方向上的增量来确定的,即\(\frac{\Delta_y}{ \Delta_x}\)。
如果我们用夹角的角度来看待斜率的话,把直线以及X轴和Y轴都看做向量,那么,斜率就是两个向量的夹角。并且,由于我们同时旋转这两个向量时,它们的夹角不会改变,所以,我们就可以通过旋转的方法来计算斜率。这样,我们就把斜率从单个变量(固定另一个变量为X轴)推广到两个变量上来。
在推广版本的斜率定义中,斜率反应了一个变量发生改变时,另一个变量所改变的比例。在量化金融场景中,它就表明了两个线性相关的变量中,当一个变量发生波动时,另一个变量可能波动的幅度。在这个场景下,我们就把斜率称为beta。
基于上面的讨论,现在我们就很容易理解,如果我们将变量Y基于变量X进行线性回归,那么,这样就能得到Y对于X的beta,也即是斜率。
上式即为William Sharpe提出的CAPM公式。他率先使用个股收益率相对于组合收益率的线性回归,得到了个股相对于组合的beta,后来被称为市场因子。此后,两个变量之间的线性回归就被广泛应用于量化研究。研报中RSRS指标的求法可能也正是从中得到到启发。
如果我们要用代码来表达两个变量之间的线性回归,那么可以这样写:
1 2 3 4 5 6 7 | |
当然,取决于用户的习惯和数据本身的格式,我们也以使用scipy和statsmodels中对应的方法。
标准分的代码实现¶
尽管标准分的提法也是规范化的,但如果你是从软件、人工智能等专业转行过来的,可能更熟悉它的英文 Z-Score,而不是标准分这个提法。这是需要我们多读研报,从实践中掌握的。

一旦理解了标准分即是z-score,那么我们就很容易由它的公式,转换出实现代码。在我们复现的研报中,我们不仅要将原始RSRS因子z-score化,还要高效率地实现滑动窗口下的z-score化。不过,这个实现难度比计算滑动窗口下的斜率要简单,因为可以通过 DataFrame的rolling方法及其广播机制来完成。
1 2 | |
Pandas的rolling方法返回的对象,很好地支持了多个滑动窗口对象之间的对齐,以及与标量相运算时的广播,因此,这行代码读起来就像是读数学公式本身一样。
这些是我们需要在平时多加练习和积累的。我们在《因子分析与机器学习策略》中,对Alpha101因子进行了比较详细的解读,其中一部分就是讲解如何将它使用各种『算子』代码化。在那里,我们介绍了更多在学术论文中提到的操作『算子』如何代码化的技巧,其中也包括了zscore。
对各种metrics的代码化¶
任何策略相关的研报,都不可能离开对策略的评估。
策略评估指标有很多,基本上不需要我们自己去实现,但是,我们需要了解每一种策略指标的定义和计算方法,重要参数。比如,在一些年化指标中,常常涉及到年化倍数,无风险利率参数设定等等。
几乎所有的策略指标的计算起点都来自于每期收益。这可以是一个最简单的python数组,或者是Numpy数组和Pandas Series。只要我们自己会计算策略的每期收益(比如每天、每月),剩下的就可以交给第三方库,比如empyrical和quantstats。
前者只进行数值计算,后者则还可以生成各种报表,比如:
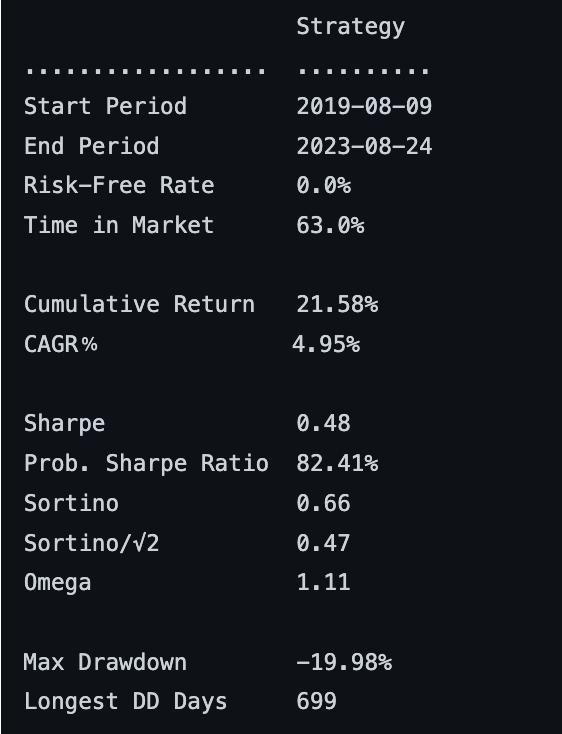
因此,在读研报之前,我们可以多看看这两个库的文档和示例,了解它们如何实现数值计算和生成报表的。熟悉了这些库之后,再来复现研报,就会快很多了。
数据从哪里来?¶
这确实是一个问题。因为它不完全是一个技术能力的问题,它还关系到成本。
为了让我们复现的研报策略以及公众号文章能够运行,我们打造了一个研究平台(基于你熟悉的Jupyterlab),在其中我们提供了2005年到2023年的日线数据(缓存),并且其它数据,可以通过tushare接口来获取(通过我们共享的tushare高级账号,价值500/年)。