strategy »
强化学习模型能否自我演化出交易智慧?
Abstract
强化学习已在摩根大通及全球顶级投资机构中使用。
与监督学习不同,强化学习不会在每一步都只接受标准答案,它会尝试、忍受短期的损失,博取长期的收益。这就使得它有了对抗金融数据噪声的能力。
奖励是强化学习的灵魂。我们可以直接把投资组合的收益率作为奖励。在监督学习中,损失函数是其核心,但我们却无法把收益率作为损失函数。
本文附有完整、精彩的强化学习代码,且不依赖于 FinRL 等框架,可在国内市场运行。
强化学习(RL)这个名字,第一次闯入大众视野,还要追溯到 AlphaGo 与李世石那场载入史册的人机大战。一战成名后,它似乎又回归了学术的象牙塔,直到最近,随着 DeepSeek 等模型的惊艳亮相,RL 以其强大的推理能力,再次被推到了聚光灯下。
其实,强化学习在量化投资中早有实际的应用。尽管一些顶尖的投资公司的当家策略不会轻易透露出来,我们还是找到了一些案例,表明华尔街的顶级玩家们早已开始使用强化学习。
比如,2017 年前后,全球顶级的投资银行摩根大通(J.P. Morgan)就推出了一个名为 LOXM1 的“觅影”交易执行平台。而驱动这个平台的『秘密武器』,正是我们今天的主角——强化学习(Reinforcement Learning, RL)。
LOXM 的目标非常明确:在执行大额股票订单时,像顶级交易员一样,智能地将大单拆分成无数小单,在复杂的市场微观结构中穿梭,以最低的冲击成本和最快的速度完成交易。
这已经不是简单地预测涨跌,而是在动态的市场博弈中,学习“如何交易”这门艺术。
究竟什么是强化学习?
那么,这个听起来如此高大上的强化学习,到底是什么?
根据《Reinforcement Learning for Quantitative Trading》2 这篇文章,我们可以构建一个统一的框架来理解它。
想像一下,你正在玩一个电子游戏,你的目标是获得尽可能高的分数。在这个游戏里:
你,就是代理(Agent)。在量化交易中,这个代理就是你的交易算法。
游戏世界,就是环境(Environment)。在交易中,这就是瞬息万变的金融市场。
你在游戏中看到的画面和状态(比如你的血量、位置、敌人的数量),就是状态(State)。在交易中,这可以是股价、成交量、技术指标、宏观数据等等。
你按下的每一个操作(前进、后退、开火),就是行动(Action) 。在交易中,这对应着买入、卖出或持有。
你每次行动后获得或失去的分数 ,就是奖励(Reward)。在交易中,这通常是你的投资组合的收益或损失。
强化学习的核心思想,就是让代理(交易算法)在这个环境(金融市场)中不断地“试错”(take actions),根据每次试错后得到的奖励(收益或亏损),来学习一套最优的策略(Policy),从而在长期内实现累计奖励的最大化(长期收益最大化)。它不是在学习“市场下一秒会怎样”,而是在学习『面对当前的市场,我该怎么做才是最优的 』。
强化学习强在哪儿?
看到这里,你可能会问,我们已经有了监督学习(比如预测股价涨跌)和无监督学习(比如聚类发现市场风格),为什么还需要强化学习?它到底强在哪?
强化学习与与监督/无监督学习的根本区别在于学习范式 。
监督学习像是在背一本标准答案书。你给它一张历史 K 线图(输入特征),告诉它第二天是涨还是跌(标签),它学习的是一种静态的"看图识字"能力。无监督学习则是在没有答案的情况下,自己在一堆数据里找规律,比如把相似的股票自动归为一类。它们都在试图回答"是什么"的问题。
而强化学习,则是在学习一套决策流程。它没有"标准答案"可背。市场不会告诉你"在此时此刻买入就是唯一正确的答案"。RL 面对的是一系列的决策,每个决策都会影响到未来的状态和可能的收益。它要回答的是"该做什么"的问题。这是一个动态的、有因果链条的、面向未来的学习过程。
有人会说,我可以用监督学习模型,然后不断地用新的数据去持续训练和预测(即在线学习,live learning),这和强化学习有什么区别?
表面上看,两者都在不断适应新数据,但内核完全不同。而强化学习的核心优势在于两个监督学习无法企及的维度:
!!! tip 探索与利用(Exploration vs. Exploitation)
这是 RL 的灵魂。想象一下,你常去的一家餐厅味道不错(利用),但你偶尔也会想试试新馆子,万一有惊喜呢(探索)?RL 代理在训练时,也会在"执行已知的最优策略"和"尝试未知的、可能有更高回报的策略"之间进行权衡。这种探索精神,使得 RL 有可能发现人类交易员或监督学习模型从未想过的、更优的交易模式。而监督学习只会告诉你,根据历史经验,去那家老餐厅是"正确答案"。
Tip
强化学习关注的是一个行动序列(比如,先买入 A,再卖出 B)与最终结果之间的因果联系。它能理解,有时候一个短期的亏损(比如为了建仓拉低成本而主动承受浮亏)是为了一个更大的长期目标。而监督学习一次只看一个"时间切片",它很难理解这种跨时间的、具有延迟效应的因果逻辑。
由于强化学习的这两个特点,所以,比起监督学习,它能更好地对抗金融噪声 -- 众所周知,深度学习在金融投资领域折戟沉沙,主要就是因为金融数据噪声太大的原因。
金融数据以低信噪比著称,充满了随机波动和"假信号"。强化学习之所以在这样的环境中更具优势,主要源于其独特的设计:
关注长期回报,容忍短期阵痛 :监督学习模型追求的是在每个时间点上预测的准确率。如果市场噪音让它做出了一个错误的预测,它就会被"惩罚"。而 RL 的目标是最大化整个交易过程的累计回报。这意味着,它可以有意识地执行一个短期看起来会亏钱的动作(比如,在一个看似要下跌的时刻买入),如果这个动作是其长期制胜策略的一部分(比如,它判断这是一个主力洗盘的假摔)。这种"延迟满足"的特性,让它对短期市场噪音有更强的免疫力。
动态适应,而非刻舟求剑 :市场风格是会切换的,昨天有效的因子,今天可能就失效了。监督学习模型一旦训练好,其模式就相对固定,像一个刻舟求剑的傻瓜。而 RL 代理的策略本身就是状态的函数,它被设计为根据环境的变化而动态调整自己的行为。当市场从牛市转向熊市,RL 代理能够通过与环境的持续交互,感知到这种变化,并相应地调整其交易策略,从激进做多转为保守甚至做空。这种与生俱来的适应性,是其对抗非平稳市场的关键。
从"追涨杀跌"的 AlphaStock 说起
顶级机构的量化策略都是秘而不宣的,即使是摩根大通的 LOXM 这种公开出圈的模型,其构建与运行机制对普通人来讲,也仍然是无法接触的。那么,作为量化交易者,我们要如何构建自己的强化学习交易模型呢?
2019 年,来自清华大学和微软亚洲研究院的团队开发了一个名为 AlphaStock1 的模型。这个模型巧妙地将强化学习与注意力机制(Attention Mechanism,没错,就是 Transformer 模型的核心)相结合,专门用来优化一个古老而有效的策略——追涨杀跌(即动量交易)。
传统的动量策略很简单:买入过去表现好的股票,卖出过去表现差的。但问题是,动量什么时候会持续?什么时候会反转?
AlphaStock 的聪明之处在于,它不依赖于固定的规则,而是让 RL 代理去学习。代理观察市场上数百只股票的价格和成交量数据(状态),然后决定在哪些股票上分配多少资金(行动)。如果这个决策在未来一段时间带来了正收益,它就获得正奖励,反之亦然。通过海量历史数据的回测训练,AlphaStock 最终就能会了如何动态地识别和利用市场中的动量效应,甚至能在一定程度上规避动量反转的风险。这就像一个武林高手,通过无数次实战,最终练就了对战局的敏锐直觉。
理论听起来很美,但如何付诸实践?我们自己能否做出来一个有用的强化学习模型?接下来,我就演示如何做出一个强化学习的交易模型。
Get Hands Dirty! 动手练一下!
对于那些可以『无限』(即不受限)访问 yfinance 及 alpaca_trade_api 的同学,我强烈推荐从 FinRL 这个开源库开始。它被誉为"金融领域的 OpenAI Gym",极大地降低了入门门槛。
安装 FinRL
首先,确保你有一个 Python 环境(推荐使用 Anaconda 或 venv 创建虚拟环境),然后通过 pip 安装 FinRL 及其依赖。
但是,FinRL依赖于yfinance和alpaca_trade_api两个库,而我们的读者可能多数无法使用这两个库。这样,你可能就不得不使用 Gymnasium 库,自己做多一点工作。
Tip
Gymnasium 是 OpenAI Gym 的继任者,是用于开发和比较强化学习算法的开源工具包。它提供了标准化的环境接口,让研究者和开发者能够更方便地测试算法性能。
安装 Gymnasium 和 SB3!
如果不用 FinRL,我们就要安装两个名字奇奇怪怪的强化学习库。
Tip
“Gymnasium” 一词源于古希腊语 “γυμνάσιον”(gymnasion),字面意思是 “裸体锻炼的地方”。现代英语中,常指健身房。但在德语中,也指初级中学。
SB3 即是 Stable-Baselines3,是强化学习领域的主流库之一,凭借其高效性、易用性和丰富的算法支持,成为学术研究和工业应用的首选工具。
这两个库中,Gym 是接口,而 SB3 提供了各种算法。在我们的示例中,将使用它提供的 PPO 算法。下面是安装这两个库的指南。
pip install gymnasium
pip install stable_baselines3
接下来,需要获取数据。这部分没有啥营养,我们就不放代码出来了,以免占用太多你的阅读时间。你可以使用任何喜欢的数据源,最终需要得到一个以 data 和 asset 为双重索引的 DataFrame,并且列名至少包含:open,high,low,close,volume。
在示例中,我们将使用缓存数据。如果你要在本地运行这个示例,你可以通过 tushare 来获取数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51 def get_stock_data_tushare ( asset_list , start_date , end_date ):
"""使用 tushare 获取股票数据(兼容方法,返回与 load_bars 相同格式)"""
all_data = []
# 转换日期格式为字符串
start_str = start_date . strftime ( "%Y%m %d " )
end_str = end_date . strftime ( "%Y%m %d " )
for asset in asset_list :
try :
# 获取日线数据
df_stock = pro . daily ( ts_code = asset , start_date = start_str , end_date = end_str )
if not df_stock . empty :
# 重命名列以匹配 load_bars 格式
df_stock = df_stock . rename (
columns = { "trade_date" : "date" , "vol" : "volume" }
)
# 转换日期格式
df_stock [ "date" ] = pd . to_datetime ( df_stock [ "date" ])
# 添加 asset 列
df_stock [ "asset" ] = asset
# 按日期排序(tushare 返回的数据是倒序的)
df_stock = df_stock . sort_values ( "date" ) . reset_index ( drop = True )
# 选择需要的列
df_stock = df_stock [
[ "date" , "asset" , "open" , "high" , "low" , "close" , "volume" ]
]
all_data . append ( df_stock )
print ( f "成功获取 { asset } 的数据,共 { len ( df_stock ) } 条记录" )
else :
print ( f "警告: { asset } 没有数据" )
except Exception as e :
print ( f "获取 { asset } 数据时出错: { e } " )
if all_data :
# 合并所有股票数据
df_combined = pd . concat ( all_data , ignore_index = True )
# 设置双重索引以匹配 load_bars 格式
df_combined = df_combined . set_index ([ "date" , "asset" ]) . sort_index ()
return df_combined
else :
return pd . DataFrame ()
!!! question 如何获得本文代码?
如果你不想写代码,可以报名我们的课程《因子挖掘与机器学习策略》,获取可运行的示例。本示例完全可以在本地运行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 import pandas as pd
import numpy as np
import talib
import datetime
import warnings
warnings . filterwarnings ( "ignore" )
# 参数设置
N_STOCKS = 50 # 股票数量,可以调整进行多次随机测试
DATA_START_DATE = datetime . date ( 2010 , 1 , 1 )
DATA_END_DATE = datetime . date ( 2021 , 10 , 31 )
# 数据划分比例 (train:test)
TRAIN_RATIO = 0.8
在量化交易中,我们从来没有见过端到端的人工智能模型能够成功的。基本上,我们总是从特征工程开始,然后才构建机器学习模型。因此,接下来,我们要创建一个 FeatureEngineer 类,用于处理特征工程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85 class FeatureEngineer :
def __init__ ( self , use_technical_indicator = True , tech_indicator_list = None ):
self . use_technical_indicator = use_technical_indicator
self . tech_indicator_list = tech_indicator_list or [
"macd" ,
"rsi" ,
"sma" ,
"bbands" ,
]
def preprocess_data ( self , df ):
df_reset = df . reset_index ()
processed_stocks = []
for asset in df_reset [ "asset" ] . unique ():
stock_data = df_reset [ df_reset [ "asset" ] == asset ] . copy () . sort_values ( "date" )
# 检查是否有足够的有效数据
if stock_data [ "close" ] . dropna () . empty :
print ( f "⚠️ 跳过股票 { asset } :没有有效的价格数据" )
continue
# 前向填充价格数据,处理停牌等情况
price_columns = [ "open" , "high" , "low" , "close" ]
for col in price_columns :
if col in stock_data . columns :
# 先前向填充,再后向填充(处理开头的NaN)
stock_data [ col ] = (
stock_data [ col ] . fillna ( method = "ffill" ) . fillna ( method = "bfill" )
)
# 成交量用 0 填充(停牌时成交量为 0 是合理的)
if "volume" in stock_data . columns :
stock_data [ "volume" ] = stock_data [ "volume" ] . fillna ( 0 )
# 最终检查:如果还有价格NaN,跳过这只股票
if stock_data [ price_columns ] . isnull () . any () . any ():
print ( f "⚠️ 跳过股票 { asset } :填充后仍有价格缺失" )
continue
close = stock_data [ "close" ] . values . astype ( float )
if "macd" in self . tech_indicator_list :
macd , macd_signal , macd_hist = talib . MACD ( close )
stock_data [ "macd" ] = macd
stock_data [ "macd_signal" ] = macd_signal
stock_data [ "macd_hist" ] = macd_hist
if "rsi" in self . tech_indicator_list :
stock_data [ "rsi_14" ] = talib . RSI ( close , timeperiod = 14 )
if "sma" in self . tech_indicator_list :
stock_data [ "close_20_sma" ] = talib . SMA ( close , timeperiod = 20 )
if "bbands" in self . tech_indicator_list :
bb_upper , bb_middle , bb_lower = talib . BBANDS ( close , timeperiod = 20 )
stock_data [ "boll_ub" ] = bb_upper
stock_data [ "boll_lb" ] = bb_lower
stock_data [ "boll_middle" ] = bb_middle
# 添加基础指标
stock_data [ "returns" ] = stock_data [ "close" ] . pct_change ()
stock_data [ "log_volume" ] = np . log ( stock_data [ "volume" ] + 1 )
processed_stocks . append ( stock_data )
df_processed = pd . concat ( processed_stocks , ignore_index = True )
# 删除包含 NaN 的行
before_count = len ( df_processed )
df_processed = df_processed . dropna () . reset_index ( drop = True )
after_count = len ( df_processed )
print ( f "✅ 技术指标计算完成: { before_count } -> { after_count } 条记录" )
print ( f "✅ 价格数据已进行前向填充处理" )
# 显示新增的列
original_cols = df . reset_index () . columns
new_columns = [ col for col in df_processed . columns if col not in original_cols ]
print ( f "新增指标: { new_columns } " )
df_processed = df_processed . set_index ([ "date" , "asset" ]) . sort_index ()
return df_processed
为了进行训练,我们需要对数据集进行 train/test 划分。在量化交易中,我们进行数据划分必须确保时间序列的连续性:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111 def split_data_by_ratio ( df , train_ratio = 0.8 , min_periods = 512 ):
"""
按比例划分数据集为训练集和测试集,并完成缺失值的填充
确保训练集和测试集包含完全相同的股票,且每个股票都有足够的有效记录
Args:
df: 输入的DataFrame,必须有date和asset的双重索引
train_ratio: 训练集比例
min_periods: 每个资产的最小有效记录数
Returns:
tuple: (train_data, test_data)
"""
print ( f "📊 开始数据划分 (train_ratio= { train_ratio } , min_periods= { min_periods } )" )
# 记录原始数据信息
original_assets = df . index . get_level_values ( "asset" ) . unique ()
original_records = len ( df )
print ( f "原始数据: { original_records } 条记录, { len ( original_assets ) } 只股票" )
# 处理缺失值的情况,快速补齐
all_dates = df . index . get_level_values ( "date" ) . unique ()
all_assets = df . index . get_level_values ( "asset" ) . unique ()
full_index = pd . MultiIndex . from_product (
[ all_dates , all_assets ], names = [ "date" , "asset" ]
)
df = df . reindex ( full_index ) . groupby ( level = "asset" ) . ffill ()
print ( f "重新索引并前向填充后: { len ( df ) } 条记录" )
# 按资产检查有效记录数,删除不满足min_periods的资产
asset_counts = df . groupby ( level = "asset" ) . apply ( lambda x : x . dropna () . shape [ 0 ])
valid_assets = asset_counts [ asset_counts >= min_periods ] . index
invalid_assets = asset_counts [ asset_counts < min_periods ] . index
print ( f " \n 📈 资产筛选结果:" )
print ( f " 满足最小记录数要求的资产: { len ( valid_assets ) } 只" )
print ( f " 不满足要求的资产: { len ( invalid_assets ) } 只" )
if len ( invalid_assets ) > 0 :
print ( f " 被删除的资产: { list ( invalid_assets ) } " )
# 只保留有效资产的数据
df = df . loc [ df . index . get_level_values ( "asset" ) . isin ( valid_assets )]
# 删除剩余的NaN记录
df = df . dropna ()
print ( f " 最终有效记录: { len ( df ) } 条" )
# 为了确保每个资产都有相同的记录数,只保留每个资产的最后min_periods条记录
df = df . groupby ( level = "asset" ) . tail ( min_periods )
final_records = len ( df )
print ( f " 统一记录数后: { final_records } 条记录" )
# 按比例划分训练集和测试集
train_size = int ( min_periods * train_ratio )
test_size = min_periods - train_size
df_reset = df . reset_index ()
df_reset [ "record_index" ] = df_reset . groupby ( "asset" ) . cumcount ()
df_reset [ "is_train" ] = df_reset [ "record_index" ] < train_size
train_data = (
df_reset [ df_reset [ "is_train" ]]
. drop ( columns = [ "record_index" , "is_train" ])
. set_index ([ "date" , "asset" ])
)
test_data = (
df_reset [ ~ df_reset [ "is_train" ]]
. drop ( columns = [ "record_index" , "is_train" ])
. set_index ([ "date" , "asset" ])
)
# 最终统计
train_assets = set ( train_data . index . get_level_values ( "asset" ) . unique ())
test_assets = set ( test_data . index . get_level_values ( "asset" ) . unique ())
print ( f " \n ✅ 数据划分完成:" )
print ( f " 训练集: { len ( train_data ) } 条记录, { len ( train_assets ) } 只股票" )
print ( f " 测试集: { len ( test_data ) } 条记录, { len ( test_assets ) } 只股票" )
print ( f " 每只股票训练记录: { train_size } 条" )
print ( f " 每只股票测试记录: { test_size } 条" )
print ( f " 实际划分比例: { train_size / min_periods : .1% } : { test_size / min_periods : .1% } " )
return train_data , test_data
# 创建特征工程器
fe = FeatureEngineer (
use_technical_indicator = True , tech_indicator_list = [ "macd" , "rsi" , "sma" , "bbands" ]
)
# 获取数据并处理特征
raw_data = load_bars ( DATA_START_DATE , DATA_END_DATE , N_STOCKS )
processed_data = fe . preprocess_data ( raw_data )
# 验证处理后的数据
if processed_data . empty :
raise ValueError ( "数据处理后为空,请检查技术指标计算" )
# 按比例划分数据集
train_data , test_data = split_data_by_ratio (
processed_data ,
train_ratio = TRAIN_RATIO ,
min_periods = 512 , # 每只股票至少需要512条记录(约2年数据)
)
# 显示处理后的数据样例
print ( " \n 处理后的数据预览:" )
print ( train_data . head ())
!!! tip 不要再用过时的经验!
在监督学习中,我们一般会将数据集划分为 train, validation 和 test 三个部分。其中, train 和 validation 用于训练模型,在训练完成之后,我们使用 test 数据集来评估模型性能。这样可以确保训练过程中,完全看不到测试数据,避免过拟合。
在强化学习中,我们也同样要划分数据集,但是,根据算法的不同,有可能只需要划分出 train 和 test 两个部分。在这里我们使用的 PPO 算法就只需要划分 train 和 test 两个部分。
定义环境
通常来说,我们要定义环境和 Agent,但是,在使用 SB3 之后,我们可以直接使用 PPO 模型,从而无须定义 Agent,因为 PPO 本身就是 Agent,所以,Agent 的定义和模型训练是一体的。
所以,我们先用 gym 来定义环境:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282 import gymnasium as gym
from gymnasium import spaces
class StockTradingEnv ( gym . Env ):
"""
基于 Gymnasium 的股票交易环境
动作空间:连续动作,每只股票的买卖比例 [-1, 1]
状态空间:[现金比例,持仓比例。.., 技术指标。..]
"""
def __init__ ( self , data , initial_amount = 100000 , transaction_cost = 0.001 ):
super () . __init__ ()
self . data = data . copy ()
self . initial_amount = initial_amount
self . transaction_cost = transaction_cost
# 获取股票列表和日期
self . stock_list = sorted ( data . index . get_level_values ( "asset" ) . unique ())
self . dates = sorted ( data . index . get_level_values ( "date" ) . unique ())
self . data_reset = data . reset_index ()
self . stock_dim = len ( self . stock_list )
# 技术指标列表
self . tech_indicators = [ "macd" , "rsi_14" , "close_20_sma" , "boll_ub" , "boll_lb" ]
# 定义动作和观察空间
# 动作:每只股票的买卖比例 [-1, 1]
self . action_space = spaces . Box (
low =- 1 , high = 1 , shape = ( self . stock_dim ,), dtype = np . float32
)
# 观察空间:[现金比例] + [持仓比例。..] + [技术指标。..]
obs_dim = 1 + self . stock_dim + len ( self . tech_indicators ) * self . stock_dim
self . observation_space = spaces . Box (
low =- np . inf , high = np . inf , shape = ( obs_dim ,), dtype = np . float32
)
# 预先创建价格缓存,避免重复查询
self . _create_price_cache ()
print ( f "🏗️ 环境初始化完成:" )
print ( f " 股票数量: { self . stock_dim } " )
print ( f " 交易日数: { len ( self . dates ) } " )
print ( f " 动作维度: { self . action_space . shape } " )
print ( f " 状态维度: { self . observation_space . shape } " )
# 初始化状态变量
self . day = 0
self . cash = self . initial_amount
self . holdings = np . zeros ( self . stock_dim )
self . portfolio_value = self . initial_amount
self . portfolio_history = [ self . initial_amount ]
def _create_price_cache ( self ):
"""创建价格缓存,使用前向填充策略"""
self . price_cache = {}
self . tech_cache = {}
# 存储每只股票的最后有效值
last_valid_prices = {}
last_valid_tech = {
stock : [ None ] * len ( self . tech_indicators ) for stock in self . stock_list
}
for date in self . dates :
date_data = self . data_reset [ self . data_reset [ "date" ] == date ]
prices = []
tech_data = []
for stock in self . stock_list :
stock_data = date_data [ date_data [ "asset" ] == stock ]
if stock_data . empty :
# 使用最后有效价格和技术指标
price = last_valid_prices . get ( stock )
if price is None :
raise ValueError (
f "股票 { stock } 在 { date } 无数据且无历史价格,数据预处理可能有问题"
)
prices . append ( price )
tech_data . extend ( last_valid_tech [ stock ])
continue
# 获取价格,使用前向填充
price = stock_data [ "close" ] . iloc [ 0 ]
if np . isnan ( price ):
price = last_valid_prices . get ( stock )
if price is None :
raise ValueError (
f "股票 { stock } 在 { date } 价格为NaN且无历史价格,数据预处理可能有问题"
)
else :
last_valid_prices [ stock ] = price
prices . append ( price )
# 获取技术指标,使用前向填充
stock_tech = []
for i , indicator in enumerate ( self . tech_indicators ):
value = (
stock_data [ indicator ] . iloc [ 0 ]
if indicator in stock_data . columns
else np . nan
)
if np . isnan ( value ):
value = last_valid_tech [ stock ][ i ] # 使用上一个有效值
if value is None :
raise ValueError (
f "股票 { stock } 指标 { indicator } 在 { date } 为NaN且无历史值,数据预处理可能有问题"
)
else :
last_valid_tech [ stock ][ i ] = value # 更新最后有效值
stock_tech . append ( value )
tech_data . extend ( stock_tech )
self . price_cache [ date ] = np . array ( prices )
self . tech_cache [ date ] = np . array ( tech_data )
def reset ( self , seed = None , options = None ):
super () . reset ( seed = seed )
self . day = 0
self . cash = self . initial_amount
self . holdings = np . zeros ( self . stock_dim )
self . portfolio_value = self . initial_amount
self . portfolio_history = [ self . initial_amount ]
observation = self . _get_observation ()
info = {}
return observation , info
def step ( self , actions ):
# 检查是否结束
if self . day >= len ( self . dates ) - 1 :
return self . _get_observation (), 0 , True , True , {}
# 获取当前价格(使用缓存)
current_date = self . dates [ self . day ]
prices = self . price_cache . get ( current_date , np . zeros ( self . stock_dim ))
# 执行交易
self . _execute_trades ( actions , prices )
# 移动到下一天
self . day += 1
# 计算新的投资组合价值
if self . day < len ( self . dates ):
next_date = self . dates [ self . day ]
next_prices = self . price_cache . get ( next_date , prices )
new_portfolio_value = self . cash + np . sum ( self . holdings * next_prices )
else :
new_portfolio_value = self . cash + np . sum ( self . holdings * prices )
# 计算奖励
reward = (
( new_portfolio_value - self . portfolio_value ) / self . portfolio_value
if self . portfolio_value > 0
else 0
)
self . portfolio_value = new_portfolio_value
self . portfolio_history . append ( self . portfolio_value )
# 检查是否结束
terminated = self . day >= len ( self . dates ) - 1
truncated = False
info = {
"portfolio_value" : self . portfolio_value ,
"cash" : self . cash ,
"holdings" : self . holdings . copy (),
}
return self . _get_observation (), reward , terminated , truncated , info
def _execute_trades ( self , actions , prices ):
"""
执行交易动作
"""
# 计算目标持仓价值
total_value = self . cash + np . sum ( self . holdings * prices )
for i , action in enumerate ( actions ):
if abs ( action ) < 0.01 : # 忽略很小的动作
continue
if prices [ i ] <= 0 : # 跳过价格为 0 或负数的股票
continue
current_value = self . holdings [ i ] * prices [ i ]
target_value = total_value * max ( 0 , action ) # 只允许正持仓
trade_value = target_value - current_value
if trade_value > 0 : # 买入
cost = trade_value * ( 1 + self . transaction_cost )
if cost <= self . cash :
shares_to_buy = trade_value / prices [ i ]
self . holdings [ i ] += shares_to_buy
self . cash -= cost
elif trade_value < 0 : # 卖出
shares_to_sell = abs ( trade_value ) / prices [ i ]
if shares_to_sell <= self . holdings [ i ]:
self . holdings [ i ] -= shares_to_sell
self . cash += abs ( trade_value ) * ( 1 - self . transaction_cost )
def _get_observation ( self ):
"""
获取当前状态观察(使用缓存数据,避免递归)
"""
# 确保 day 在有效范围内
current_day = min ( self . day , len ( self . dates ) - 1 )
current_date = self . dates [ current_day ]
# 现金比例
cash_ratio = self . cash / self . portfolio_value if self . portfolio_value > 0 else 0
# 获取当前价格(使用缓存)
prices = self . price_cache . get ( current_date , np . ones ( self . stock_dim ) * 100.0 )
# 持仓比例
holdings_value = self . holdings * prices
holdings_ratio = (
holdings_value / self . portfolio_value
if self . portfolio_value > 0
else np . zeros_like ( holdings_value )
)
# 技术指标(使用缓存)
tech_values = self . tech_cache . get (
current_date , np . zeros ( len ( self . tech_indicators ) * self . stock_dim )
)
# 标准化技术指标
normalized_tech = []
for i , stock in enumerate ( self . stock_list ):
for j , indicator in enumerate ( self . tech_indicators ):
idx = i * len ( self . tech_indicators ) + j
if idx < len ( tech_values ):
value = tech_values [ idx ]
# 标准化技术指标
if indicator == "rsi_14" :
value = ( value - 50 ) / 50 # RSI 标准化到 [-1, 1]
elif "macd" in indicator :
value = np . tanh ( value / 100 ) # MACD 使用 tanh 标准化
else :
close_price = prices [ i ] if prices [ i ] > 0 else 1
value = np . tanh ( value / close_price )
normalized_tech . append ( value if not np . isnan ( value ) else 0 )
else :
normalized_tech . append ( 0 )
# 组合观察向量
observation = np . concatenate ([[ cash_ratio ], holdings_ratio , normalized_tech ])
# 最终NaN检查和处理
if np . any ( np . isnan ( observation )):
print ( f "⚠️ 观察向量包含NaN,将替换为0" )
observation = np . nan_to_num ( observation , nan = 0.0 )
return observation . astype ( np . float32 )
# 创建环境
print ( " \n 🏗️ 创建交易环境。.." )
train_env = StockTradingEnv ( train_data , initial_amount = 100000 )
test_env = StockTradingEnv ( test_data , initial_amount = 100000 )
print ( " \n ✅ 环境创建完成!" )
# 测试环境重置
print ( " \n 🔄 测试环境重置。.." )
train_obs , _ = train_env . reset ()
print ( f "训练环境观察向量形状: { train_obs . shape } " )
test_obs , _ = test_env . reset ()
print ( f "测试环境观察向量形状: { test_obs . shape } " )
首先,我们定义了一个名为 StockTradingEnv 的类,继承自 gym.Env。在强化学习中, Env (环境)就是智能体交互和学习的“世界”。
动作空间是智能体可以执行的操作。这里是连续的,对于我们投资组合里的每一只股票,智能体都可以决定一个介于-1 到 1 之间的值,代表是卖出(-1 到 0)还是买入(0 到 1)这只股票的资金比例。
Tip
完整地解读这段代码需要很长的篇幅。感兴趣者可以报名《因子挖掘与机器学习策略》课程,获得讲解。
状态空间是智能体观察到的环境信息。它包括了当前的现金比例、每只股票的持仓比例,以及一系列技术指标(比如 MACD, RSI 等)。这是智能体做决策的依据。在代码中,通过_get_observation 方法来构建和获取,返回的信息包含了现金比例,持仓市值、技术指标等。在智能体的每一次决策时,它都会收到这样一个长长的一维数组。
每日持仓记录在 self.holdings 中,每日资产记录在 self.portfolio_history 中,用于后续的性能评估和可视化。
reset 方法的作用是恢复环境的状态。当一轮完整的交易周期(从头到尾回测)结束后,或者我们想开始新的一轮训练时,就要调用 reset 方法。
这部分代码中,最核心的方法是 step 方法。智能体(到目前为止,我们还没有定义智能体,但你马上会看到!)每次执行一个动作 actions ,环境就会调用 step 方法来处理这个动作,并返回结果。
Tip
量化人很熟悉传统回测框架(比如 zipline, backtrader)。你可以把 step 类比成为这些框架中的 handle_data 或者 handle_bar 方法。两者都要『执行交易、更新状态』(市值、现金流、收益/奖励)。不过在 handle_data 中,我们一般要做出决策,而在强化学习的 step 中,决策部分已经被分离出去了--它被交给了 Agent。
在这个框架里,执行交易也变得简单。因为在 step 方法中,传入的 actions 已经包含了目标仓位信息,所以,我们只需要根据现有持仓和目标仓位的数量进行计算,就可以知道如何调仓。
下面,我们就来定义智能体--Agent。
定义 Agent 及训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25 from stable_baselines3 import PPO
model = PPO (
"MlpPolicy" ,
train_env ,
verbose = 1 ,
learning_rate = 0.0003 ,
n_steps = 2048 ,
batch_size = 64 ,
n_epochs = 10 ,
gamma = 0.99 ,
gae_lambda = 0.95 ,
clip_range = 0.2 ,
ent_coef = 0.01 ,
vf_coef = 0.5 ,
max_grad_norm = 0.5 ,
seed = 42 ,
)
print ( "🚀 开始训练。.." )
model . learn ( total_timesteps = 10000 , progress_bar = True )
print ( "✅ 训练完成!" )
# 保存模型
# model.save("ppo_trading_model")
这里我们定义了一个 PPO 类型的智能体,并且使用了多层感知机(Multi-Layer Perceptron)作为网络结构。对于基于数值向量(现金比例、持股比例、技术指标)的输入,MlpPolicy 是最直接和常见的选择。
接下来我们按要求传入环境(这里是 train_env),时间步 (n_steps)、训练轮数(n_epochs)。这里的时间步是强化学习中的一个核心问题,在后面还有一个 total_timesteps 参数,我们结合到一起来讲解。
想象一下我们的智能体是一个正在学习交易的学生。他不是每做一笔交易(一个 step )就马上总结经验、调整策略,那样太短视了,容易被市场的短期随机波动所迷惑 。相反,他会先连续地进行 n_steps 次模拟交易 ,把这一个完整周期(比如 2048 天)的全部经历——包括每天的市场状态、他采取的行动、以及因此获得的收益或亏损——都记录在一个“经验回放缓冲区”(Rollout Buffer)里。
当这个缓冲区被装满(即完成了 n_steps 次的交互)后,他会停下来,拿出这个装满了 2048 天交易记录的“笔记本”,开始进行一次 集中的、深度的复盘和学习 。这就是模型更新(Update)的时刻。
把 n_steps 与 total_timesteps 联系起来,事情就更清晰了:
total_timesteps 是总的学习时长。它除以 n_steps,得到一个学习次数。也就是在一次训练中,会进行这么多次大的更新。
在每一次大的学习更新中,模型会把一个 n_steps 中的数据拿出来,反复学习 n_epochs 次,而在每一个 epoch 中,又会拆分成更小的批次(batch_size)来进行梯度下降和网络权重更新(取决于内存/显存大小)。
Attention
在示例中,n_steps = 2048,大约相当于 8 年。即每次『复盘』,智能体都经历了一个非常长的、足以包含牛市、熊市和震荡市的完整市场周期。这对于学习到一个鲁棒的、能够穿越牛熊的策略至关重要。
不过,尽管我们设置的 total_timesteps 是 10_000,但实际上数据只有约 2880 天,只够 Agent 进行一次大的复盘与学习更新。并且,余下的数据(约 832 天)因为不足以再进行一次完整的更新,这些数据没有被利用,造成了浪费。
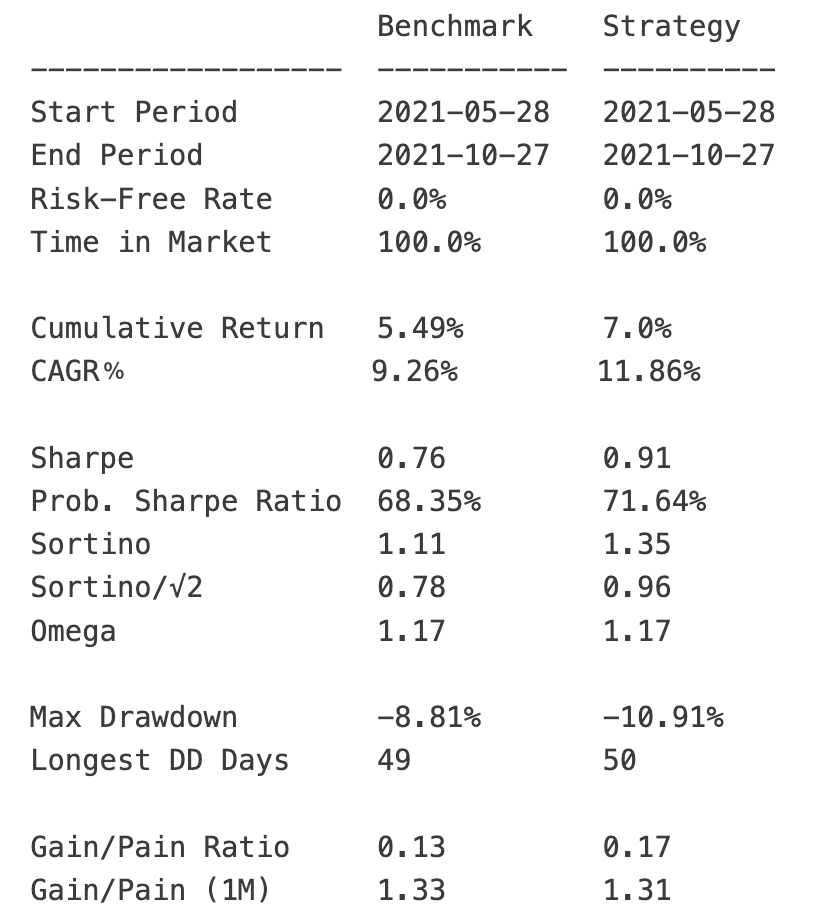
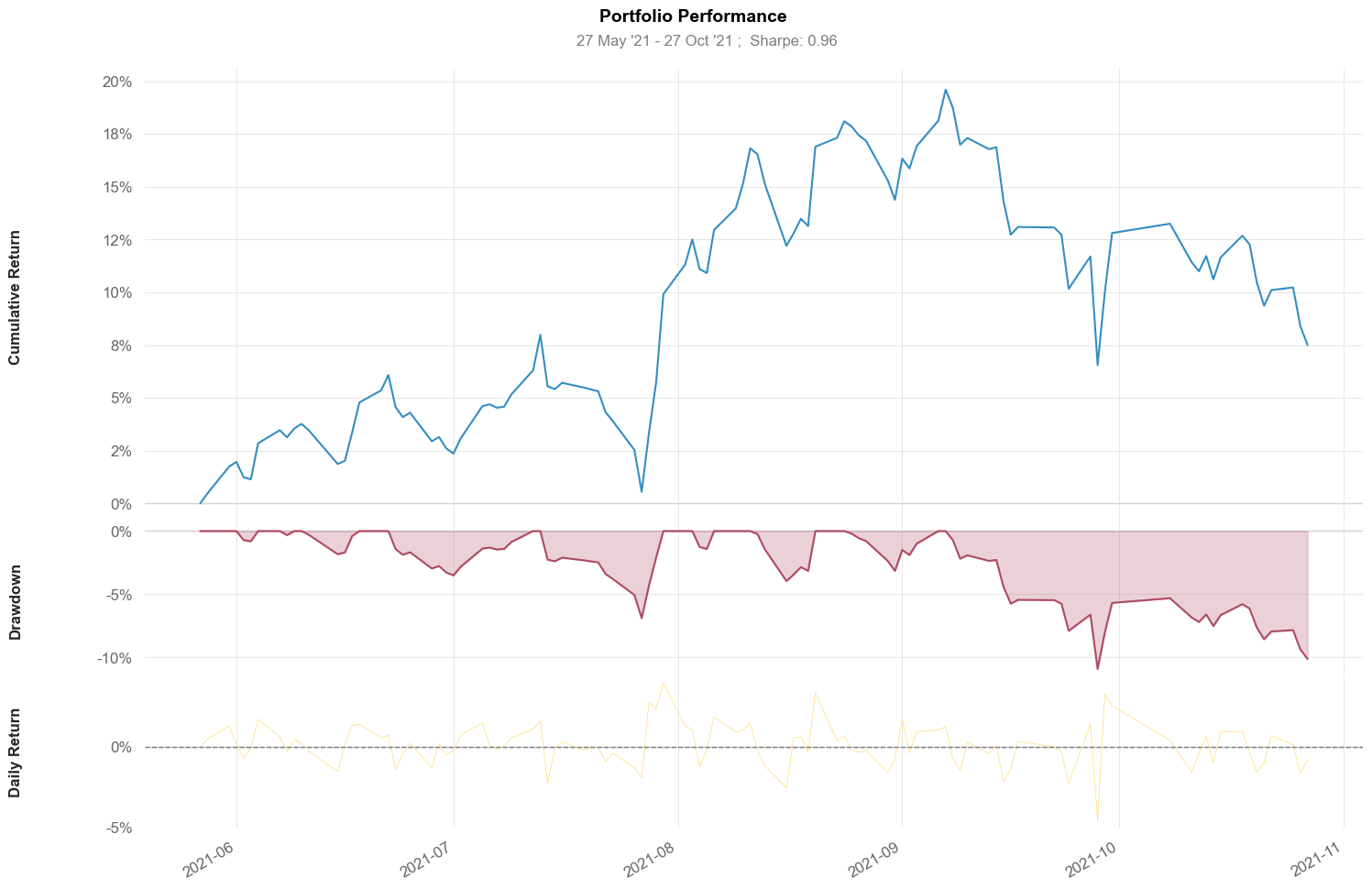
回测与结果
现在,我们开始回测,并使用 quantstats 生成标准化的投资组合分析报表。同时创建等权基准进行对比。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57 import quantstats as qs
import matplotlib.pyplot as plt
def create_equal_weight_benchmark ( test_data ):
"""
创建等权基准组合
"""
prices = test_data [ "close" ] . unstack ( "asset" )
daily_returns = prices . pct_change () . dropna ()
equal_weight_returns = daily_returns . mean ( axis = 1 )
return pd . Series ( equal_weight_returns , index = prices . index )
benchmark = create_equal_weight_benchmark ( test_data )
print ( "📊 开始强化学习模型回测。.." )
obs , _ = test_env . reset ()
done = False
total_reward = 0
step_count = 0
portfolio_values = []
dates = []
test_dates = sorted ( test_data . index . get_level_values ( "date" ) . unique ())
while not done :
action , _ = model . predict ( obs , deterministic = True )
obs , reward , terminated , truncated , info = test_env . step ( action )
done = terminated or truncated
total_reward += reward
portfolio_values . append ( info [ "portfolio_value" ])
# 记录对应的日期
if step_count < len ( test_dates ):
dates . append ( test_dates [ step_count ])
step_count += 1
if step_count % 20 == 0 :
print ( f "步骤 { step_count } : 投资组合价值 = ¥ { info [ 'portfolio_value' ] : ,.2f } " )
print ( f " \n 📈 强化学习模型回测完成!" )
print ( f "总步数: { step_count } " )
print ( f "总奖励: { total_reward : .4f } " )
print ( f "最终投资组合价值:¥ { portfolio_values [ - 1 ] : ,.2f } " )
print ( f "总收益率: { ( portfolio_values [ - 1 ] / 100000 - 1 ) * 100 : .2f } %" )
# 创建投资组合收益率序列
portfolio_returns = pd . Series ( portfolio_values , index = dates ) . pct_change () . dropna ()
qs . extend_pandas ()
qs . reports . metrics ( portfolio_returns , benchmark = benchmark , display = True )
# 生成关键绩效图表快照
qs . plots . snapshot ( portfolio_returns , benchmark = benchmark , figsize = ( 15 , 10 ))
quantstats reloaded!"
这里需要 quantstats,注意它在 python 3.12 下完全不能运行,你需要安装匡醍维护发布的 quanstats-reloaded 版本。
输出大致如下:
这样我们就完整地实现了一个先进的强化学习交易模型!在此基础上,你只需要做好特征工程和数据预处理,就可以不断改进和调优它!
One More Thing
通常,你看到关于强化学习交易模型的介绍,都常常会提到 FinRL。确实,它是一个非常优秀的库,但是,它要求使用YFinance -- 2021年底起在内陆就不再能够使用;并且它还依赖于Alpaca -- 这是一个用于交易美股的库。
这两个依赖会导致使用FinRL的程序,在我们这里无法运行。这是为什么我们要自己从头实现的原因。
另外我们还要多讲一句,魔鬼藏在细节中。比如,在训练时使用的资产集,那么在测试(实盘时)也只能使用同样的资产集。但是当你处理很长时间跨度的回测时,进行数据集划分时,就会容易犯错误,导致这两个集合不一致。在量化交易中,工程实现能力与算法创新(对多数人来讲,实际上是应用)能力都很重要。
在我手动实现完成这个框架之后,想起来其实数据预处理的大部分工作,在Alphalens这个库中都有实现过 -- 至少在这一部分, Alphalens 表现得很健壮。
如果你对本文内容及对应的代码感兴趣,或许应该参加《因子挖掘与机器学习策略》课程。强化学习是这门课的补充课程。
总而言之,强化学习为量化交易打开了一扇通往更高维度智能的大门。它不再是让机器模仿人类,而是让机器在模拟的市场中自我进化、自我博弈,最终习得超越人类直觉的交易智慧。这条路充满挑战,但也同样充满机遇。
那么,你准备好,让你的第一个交易 Agent,开始它的"进化之旅"了吗?
LOXM: https://www.businessinsider.com/jpmorgan-takes-ai-use-to-the-next-level-2017-8
量化交易中的强化学习:https://dl.acm.org/doi/10.1145/3582560
Alphastock,一个追涨杀跌模型:https://arxiv.org/abs/1908.02646