Pandas连续涨停统计
Table of Content

常常需要快速统计出一段时间内,最强的股和最弱的股,以便研究该区间内,强势股和弱势股有什么特点。
如果使用循环,这就跟掰着手指头数数没啥区别,各位藤校生一定是不屑的。所以,我们来看看如何简洁优雅地实现这一功能,同时可以在同事面前zhuangbility.
这里我们以2023年的数据为例,要求统计出连续涨停在n天以上的个股,并且给出涨停时间。同样的方案也可以找出当年最终的股,以及它们的时间。
你可以对着屏幕把代码copy下来,自己找来数据验证。不过要是赶时间的话,建议加入我的部落:
![]()
加入部落者,即可获得Quantide研究环境账号,直接运行和下载本教程。
我们先加载数据:
1 2 3 4 5 6 | |
load_bars函数在我们的研究环境下可用。这将得到以下格式的数据:
| date | asset | open | high | low | close | volume | amount | price |
|---|---|---|---|---|---|---|---|---|
| 2023-12-25 | **** | 30.85 | 31.20 | 30.06 | 30.08 | 3591121.00 | 109649397.62 | 30.14 |
| 2023-12-26 | **** | 30.14 | 30.25 | 26.00 | 27.85 | 9042296.00 | 251945474.00 | 27.90 |
| 2023-12-27 | **** | 27.90 | 28.89 | 27.18 | 28.89 | 5488847.00 | 155156381.16 | 28.58 |
| 2023-12-28 | **** | 28.58 | 29.85 | 28.44 | 29.20 | 5027247.00 | 147201133.00 | 29.25 |
| 2023-12-29 | **** | 29.25 | 30.14 | 29.25 | 29.66 | 3923048.00 | 116933800.77 | NaN |
我们只取价格数据,然后展开成宽表,以求出每天的涨跌符:
1 2 3 | |
现在我们将得到这样的结果:
| date | **** | **** | **** | ... | **** | **** | **** |
|---|---|---|---|---|---|---|---|
| 2023-12-25 | -0.00 | -0.01 | -0.02 | ... | -0.01 | -0.03 | -0.03 |
| 2023-12-26 | -0.01 | -0.01 | -0.02 | ... | 0.00 | -0.02 | -0.07 |
| 2023-12-27 | 0.00 | 0.00 | 0.02 | ... | -0.01 | 0.00 | 0.04 |
| 2023-12-28 | 0.04 | 0.03 | 0.01 | ... | 0.03 | 0.02 | 0.01 |
| 2023-12-29 | -0.01 | -0.01 | 0.02 | ... | 0.00 | -0.00 | 0.02 |
5 rows × 5085 columns
接下来,我们要判断哪一天为涨停。因为我们的目标并不是执行量化交易,只是为了研究,所以,这里可以容忍一定的误差。我们用以下方式决定是否涨停(排除北交所、ST):
1 2 3 | |
这里的语法要点是,如何使用多个条件的组合,以及如何将nan的值转换为0,而其它值转换为1。
这里会出现nan,是因为我们处理的是宽表。在宽表中,有一些列在某个点上(行)不满足条件,而在该点上,其它列满足条件,导致该行必须被保留;不满足条件的列,在该行的值就是nan。然后我们用notna将nan转换为False,其它值转换为True,最后通过astype转换为整数0和1,1代表该天有涨停。
接下来,我们就要对每一个资产,统计它的连续涨停天数。我们用以下函数来处理:
1 2 3 4 5 6 7 8 | |
这个函数的巧妙之处是,它先计算每一行与前一行的差值,并进行累加。如果有这样一个序列: 0 0 1 1 1 0 0,那么diff的结果就是nan, 0, 1, 0, 0, -1, 0。这里不为0的地方,就表明序列的连续状态发生了变化:要么出现连续涨停,要么连续涨停中止。
然后它通过cumsum累计差分序列。这样就与原序列形成如下的对应关系:
| 原序列 | diff | diff!=0 | cumsum |
|---|---|---|---|
| 0 | nan | true | 1 |
| 0 | 0 | false | 1 |
| 1 | 1 | true | 2 |
| 1 | 0 | false | 2 |
| 1 | 0 | false | 2 |
| 0 | -1 | true | 3 |
| 0 | 0 | false | 3 |
如果把这里的cumsum看成组号,那么就可以通过groupby分组,然后计算每组中非0的个数,就得到组内连续涨停次数。这就是第4行的工作。
Marvelous!
最后,我们来应用这个函数:
1 2 | |
我们得到以下结果(部分):
| date | asset | 连续涨停 |
|---|---|---|
| 2023-10-25 | **.XSHG | 14 |
| 2023-10-24 | **.XSHG | 13 |
| 2023-03-21 | **.XSHE | 12 |
| 2023-10-23 | **.XSHG | 12 |
| 2023-03-20 | **.XSHE | 11 |
我们拿其中一个验证一下:
1 2 3 4 5 6 7 | |
我们来看下k线图:
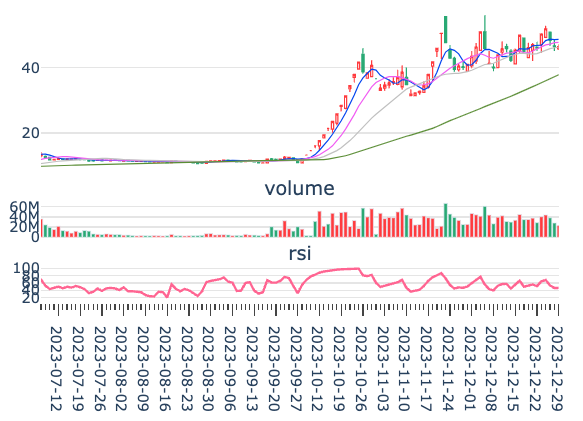
最后,我们把函数封装一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
最后,这一届的奥斯卡颁给...的主力(算了,哪怕是历史数据,也不要透露了)。
当你不知道该往哪里踢时,就往球门里踢!现在,对着你去年错过的连接14个涨停,来找找规律吧!