高效量化编程: Pandas 的多级索引
Table of Content
题图: 普林斯顿大学。普林斯顿大学在量化金融领域有着非常强的研究实力,并且拥有一些著名的学者,比如马克·布伦纳迈尔,范剑青教授(华裔统计学家,普林斯顿大学金融教授,复旦大学大数据学院院长)等。
Pandas 的多级索引(也称为分层索引或 MultiIndex)是一种强大的特性。当我们进行因子分析、组合管理时,常常会遇到多级索引,甚至是不可或缺。比如,Alphalens在进行因子分析时,要求的输入数据格式就是由date和asset索引的。同样的数据结构,也会用在回测中。比如,如果我们回测中的unverse是由多个asset组成,要给策略传递行情数据,我们可以通过一个字典传递,也可以通过这里提到的多级索引的DataFrame传递。
在这篇文章里,我们将介绍多级索引的增删改查操作。
创建一个有多级索引的DataFrame¶
让我们先从一个最普通的行情数据集开始。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
生成的数据集如下:
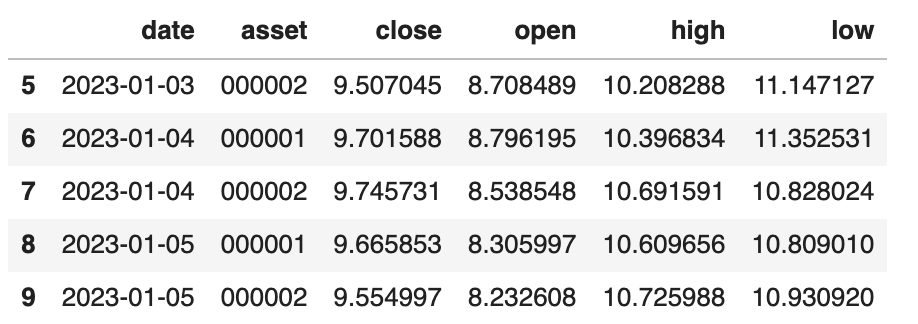
我们可以通过set_index方法来将索引设置为date:
1 2 | |
这样,我们就得到了一个只有date索引的DataFrame。
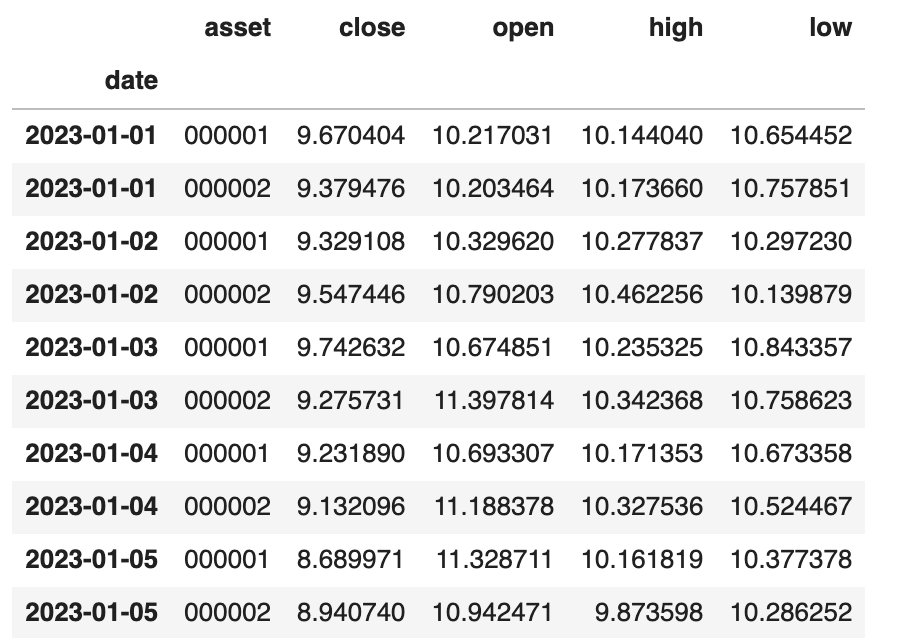
如果我们在调用set_index时,指定一个数组,就会得到一个多级索引:
1 | |
这样就生成了一个有两级索引的DataFrame。
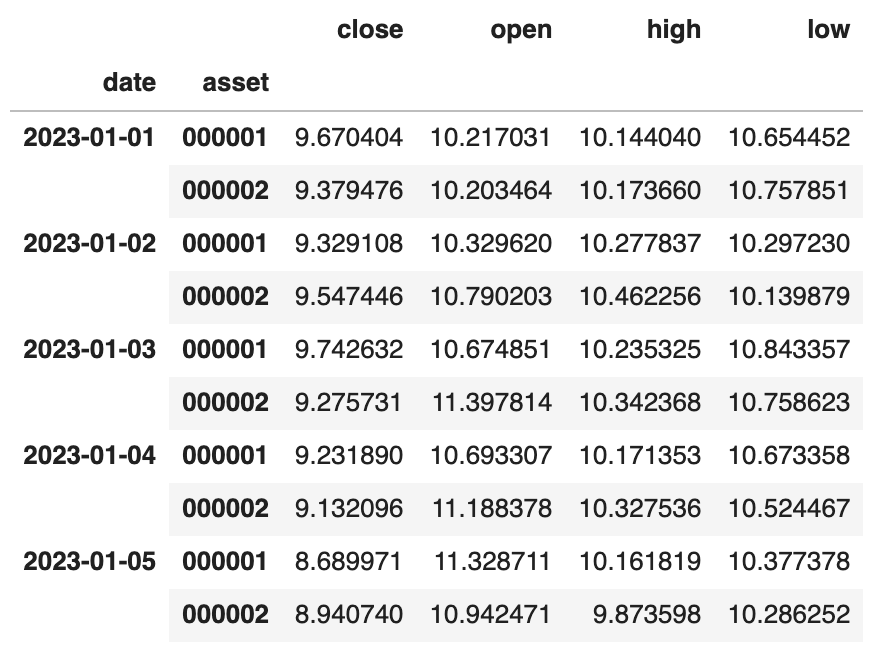
set_index语法非常灵活,可以用来设置全新的索引(之前的索引被删除),也可以增加列作为索引:
1 | |
这样得到的结果会跟上图完全一样。但如果你觉得索引的顺序不对,比如,我们希望asset排在date前面,可以这样操作:
1 2 | |
我们通过swaplevel方法交换了索引的顺序。但如果我们的索引字段不止两个字段,那么, 我们就要使用reorder_levels()这个方法了。
重命名索引¶
当数据在不同的Python库之间传递时,往往就需要改变数据格式(列名、索引等),以适配不同的库。如果需要重命名索引,我们可以使用以下几种方法之一:
1 2 3 4 5 6 7 8 9 10 11 | |
与之区别的是,我们常常使用df.rename来给列重命名,而这个方法也有给索引重命名的选项,但是,含义却大不相同:
1 | |
没有任何事情发生。这究竟是怎么一回事?为什么它没能将index重新命名呢? 实际上它涉及到DataFrame的一个深层机制, Axes和axis。
axes, axis¶
你可能很少接触到这个概念,但是,你可以自己验证一下:
1 2 | |
我们会看到如下输出:
1 2 3 4 | |
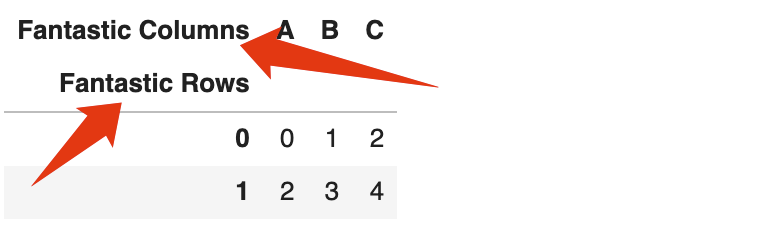
这两个元素都称为Axis,其中第一个是行索引,我们在调用 Pandas函数时,可能会用 axis = 0,或者axis = 'index'来引用它;第二个是列索引,我们在调用Pandas函数时,可能会用axis = 1,或者axis = 'columns'来引用它。
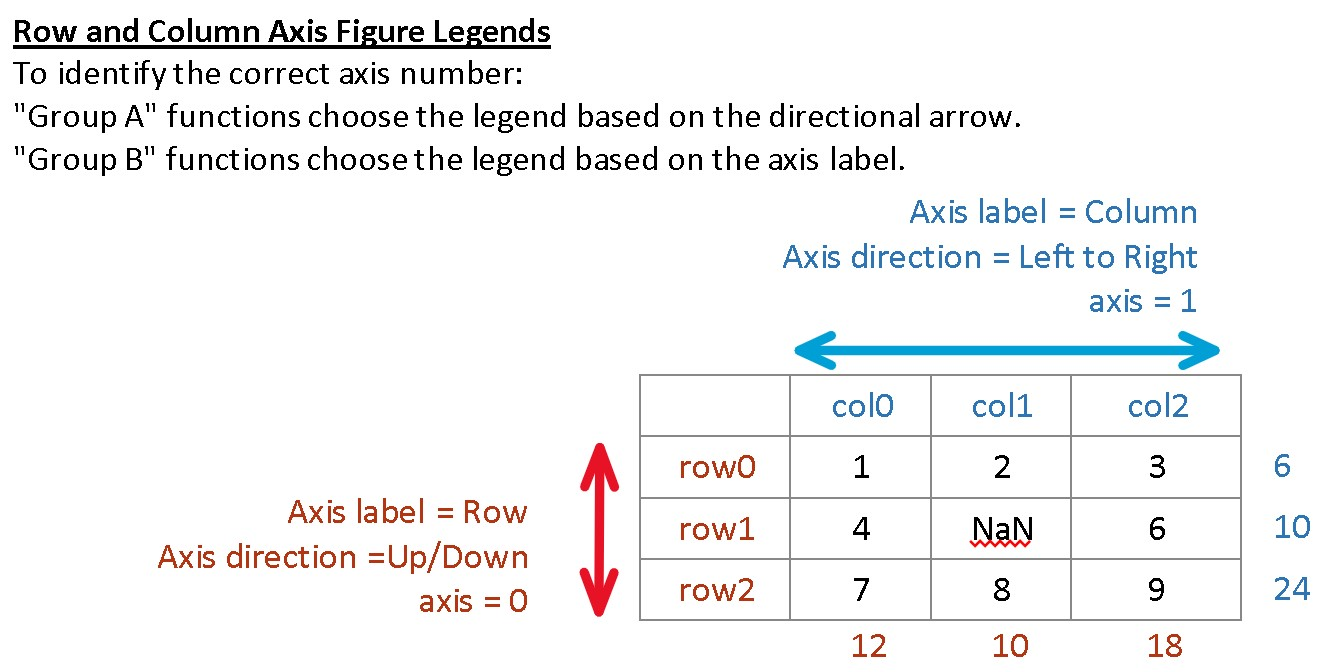
到目前为止,这两个索引都只有一级(level=0),并且都没有名字。当我们说列A,列B并且给列改名字时,我们实际上是在改axis=1中的某些元素的值。
现在,我们应该可以理解了,当我们调用df.rename({"date": "rename_date"})时,它作用的对象并不是axis = 0本身,而是要作用于axis=0中的元素。然而,在index中并不存在"date"这个元素(df中的索引都是日期类型),因此,这个重命名就不起作用。
现在,我们明白了,为什么给索引改名字,可以使用df.index.rename。同样地,我们就想到了,可以用df.columns.rename来改列名。
1 2 3 4 | |
这样显示出来的DataFrame,会在左上角多出行索引和列索引的名字。
同样地,我们也可以猜到,既然行存在多级索引,那么列也应该有多级索引。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
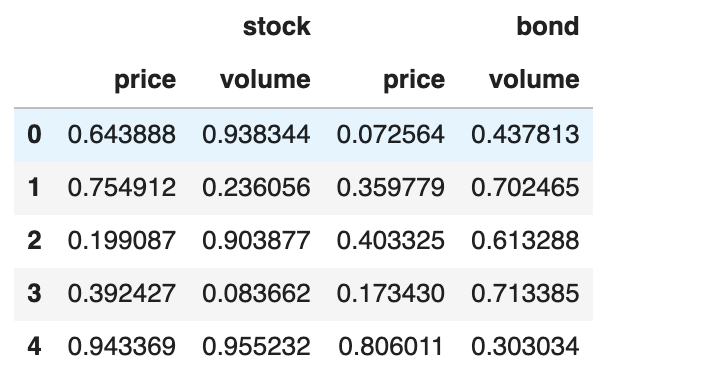
左上角一片空白,因此,这个DataFrame的行索引和列索引都还没有命名(乍一看挺反直觉的,难道列索引不是stock, bond吗)!
总之,如果我们要给行索引或者列索引命名,请使用"正规"方法,即rename_axis。我们绕了一大圈,就是为了说明为什么rename_axis才应该是用来重命名行索引和索引的正规方法。
下面的例子显示了如何给多级索引的column索引重命名:
1 | |
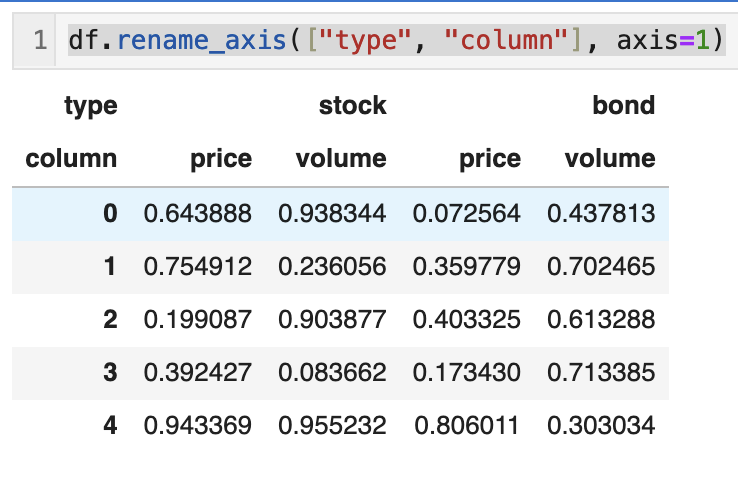
这非常像一个Excel工作表中,发生标题单元格合并的情况。
访问索引的值¶
有时候我们需要查看索引的值,也许是为了troubleshooting,也许是为了传递给其它模块。比如,在因子检验中,我们可能特别想知道某一天筛选出来的表现最好的是哪些asset,而这个asset的值就在多级索引中。
如果只有一级索引,我们就用index或者columns来引用它们的值。如果是多级索引呢?Pandas引入了level这个概念。我们仍以df2这个DataFrame为例。此时它应该是由new_date, new_asset为索引的DataFrame。
此时,new_date是level=0的行索引,new_asset是level=1的行索引。要取这两个索引的值,我们可以用df.index.get_level_values方法:
1 2 3 | |
当索引没有命名时,我们就要使用整数来索引。否则,就可以像第三行那样,使用它的名字来索引。
按索引查找记录¶
当存在多级索引时,检索索引等于某个值的全部记录非常简单,要使用xs这个函数。让我们回到df2这个DataFrame上。此时它应该是由new_date, new_asset为索引的DataFrame。
现在,我们要取asset等于000001的全部行情:
1 | |
我们将得到一个只有一级索引,包含了全部000001记录的DataFrame。