量化研究员如何写一手好代码
Table of Content
即使是Quant Research, 写一手高质量的代码也是非常重要的。再好的思路,如果不能正确地实现,都是没有意义的。只有正确实现了、通过回测检验过了,才能算是真正做出来了策略。
写一手高质量的代码的意义,对Quant developer来讲就更是自不待言了。这篇notebook笔记就介绍一些python best practice。
依赖地狱和解决之道¶
在量化研究中,我们很多功能会借助第三方包。第三方包也必然会依赖其它第三方包。如果有两个以上的包都依赖于某一个包,但是要求的版本不同,这就发生了依赖地狱。
有一些量化研究员常常会把自己的研究环境搞坏,就是因为不断尝试新的技术、新的python库,而这些新的库,依赖的第三方版本和原来的发生冲突,强行覆盖之后,导致之前的python库无法使用造成的。
解决依赖地狱问题,需要在不同的层面上进行解决。
首先,我们一般会为将在进行的新的研究项目,创建一个新的虚拟环境。在这个虚拟环境中,由于只安装了必须的软件库,于是发生冲突的可能性就会小一些。
其次,我们是要通过正确的依赖管理,尽可能地解决依赖冲突。这主要是通过poetry来实现的。
虚拟环境¶
Python中构建虚拟环境的方案有很多,作为量化研究员,我们只需要掌握conda就可以了。其它的方案还有virtualenv, venv和pipenv等。作为QD,需要掌握venv,这是python的一个标准库,用来创建新的虚拟环境,具有轻量、快速的特点。
版本语义¶
在软件开发领域中,我们常常对同一软件进行不断的修补和更新,每次更新,我们都保留大部分原有的代码和功能,修复一些漏洞,引入一些新的构件。
有一个古老的思想实验,被称之为忒修斯船(The Ship of Theseus)问题,它描述的正是同样的场景:

忒修斯船问题最早出自公元一世纪普鲁塔克的记载。它描述的是一艘可以在海上航行几百年的船,只要一块木板腐烂了,它就会被替换掉,以此类推,直到所有的功能部件都不是最开始的那些了。现在的问题是,最后的这艘船是原来的那艘忒修斯之船呢,还是一艘完全不同的船?如果不是原来的船,那么从什么时候起它就不再是原来的船了?
忒修斯船之问,发生在很多领域。比如像IBM这样的百年老店,CEO换了一任又一任,那它还是最初创建时的IBM吗?在软件开发领域中,我们更是常常遇到同样的问题。每遇到一个漏洞(bug),我们就更换一块"木板"。随着这种修补和替换越来越多,软件也必然出现忒修斯船之问:现在的软件还是不是当初的软件,如果不是,那它是在什么时候不再是原来的软件了呢?
解决这个问题的核心是要实现版本的语义化。即,版本号分段为major.minor.patch三个段,如果是破坏性更新,则必须变更主版本号;如果是增加新的功能,但对之前保持兼容,则更新小的版本号(minor)。如果没有功能变更,只是修复了bug、安全性更新,则更新patch版本号。
我们在使用第三方库时,就可以指明自动更新patch,或者允许自动更新到minor,而拒绝major级别的自动更新。

在第三方库遵循这个约定,进行了版本声明之后,我们就可以通过poetry来管理我们项目的依赖了:
poetry是一个版本依赖管理工具。在使用poetry之前,你可能通过requirements.txt来管理过项目的依赖。它的问题是,并不会检查你加入的依赖,是否能与其它软件和睦相处,但Poetry可以。
所以,今后我们开启新的策略研究时,我们应该先通过conda创建一个新的项目环境,然后通过poetry来增加项目依赖:
1 2 3 | |
如此一来,在我们每次增加新的依赖时,poetry就会自动帮我们检查匹配的版本。如果找不到合适的版本,它就会报错,这样我们也有机会思考,是否有别的方案。
书写漂亮的代码¶
在写代码时,我们会有自己的风格。比如变量名如何使用大小写,单词之间如何分隔,如何使用空格和缩进等等。为了统一风格,2001年由Guido等人拟定了一份关于python代码风格的提案,被称为PEP8.
![]()
PEP8的目的是为了提高python代码的可读性,使得python代码在不同的开发者之间保持一致的风格。PEP8的内容包括代码布局、命名规范。比如类要以大写字母开头、函数名以小写开头、单词之间用下划线分隔,等等。
PEP8的内容非常多,在实践中,我们不需要专门去记忆它的规则,只要用对正确的代码格式化工具,最终呈现的代码就一定是符合PEP8标准的。或者lint工具会提示我们相关的错误,照着修改就够了。
一般情况下,我们配置black作为代码格式化工具,就能保证风格符合PEP8的要求。
推荐black的原因是,它基本上不接受定制。实际上,代码风格的定制几乎没有意义。一个人即使长得丑点,你强迫自己多看他几眼,就会发现其实也是能看的。所以black的成功就在这地方,它的motto是不妥协的格式化工具。很多事情就是这样,坚持自己的风格,宁可站着死,不愿跪着生,向死而生,反倒是机会。
语法检查工具¶
在运行代码之前,我们也有一些方法来检查编码中的错误。这类工具被称为lint工具。一般我们配置flake8, isort(用来给导入排序),mypy等工具。mypy是用来做类型检查的。
类型提示¶
类型提示(type hint)可以帮助IDE实现代码自动完成,也可以帮助我们尽早发现错误。这是从python 3.4起开始导入,到python 3.8框架完成的一个功能。
我们知道,python是一门动态语言。它是有类型的,但这个类型检查只在运行时才能执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
上面的代码演示了在编码阶段,python和IDE不会提示任何类型错误。所以,第一段代码永远不会抛出错误。但如果我们有机会执行 1 + "two"的话,就会得到一个TypeError错误,提示我们不能把int和str相加。这就是运行时检查。
如果我们按照type hint的要求来书写代码,就可以在早期发现一些错误,比如下面的例子:
1 2 3 4 5 | |
在这段代码中,如果我们在IDE(比如vscode)中,把光标移动到foo(10)的位置,就会出现如下的错误提示:
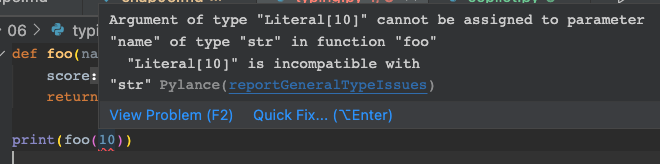
这样我们就能在运行前,发现调用foo方法时,传入了错误的参数。
下面的代码演示了多数常见的type hint用法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | |
如果我们是在vscode中写代码,它自带一个pylance工具,将根据我们提供的type hint,来推断哪些代码在调用上,类型不对,这样可以尽早排除错误。
如果我们习惯使用notebook进行策略研究,也可以在vscode中创建notebook,此时也可以得到pylance的帮助。
Tip
vscode提供的Jupyter notebook除了在排版上可能不如原生的jupyter notebook之外,在很多方面都是胜出的。比如,除了语法检查,还有记住上一个编辑位置并实现跳转、支持单元格调试等等。
单元测试: mock it till you make it!¶
在策略研发时,我们要多用单元测试。单元测试有几个用处,第一,我们可以用它来学习第三方库的一些用法。第二,确保我们自己写的可复用的功能模块得到充分测试。
单元测试并不复杂,主要难点在于如何将待测试的代码与系统中的其它部分隔离开来。这里我们一般使用mock对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
更多¶
更多关于Python编程最佳实践,请阅读《Python能做大项目》。
这本书除涵盖上述内容(当然讲得更详细)之外,还介绍了如何进行代码版本管理(即使用git),如何进行持续集成(CI/CD)和如何撰写和生成技术文档。