[0901] QuanTide Weekly
Table of Content
本周要闻¶
- 市场传闻存量房贷利率下调,房地产 ETF 大涨,但尾盘多股炸板
- 中国 8 月官方制造业 PMI 为 49.1% 比上月下降 0.3 个百分点
- 国家市监总局宣布阿里整改完成
- 半年报第一股!桐昆股份同比增长 911.35%,为已发布半年报公司中净利润增速最高。
下周看点¶
- 下调存量房贷利率传闻能否兑现?
- 周一财新制造业 PMI 发布
- 周五,2024 低空经济发展大会将于 9 月 6 日至 8 日在芜湖举行
本周精选¶
- 主力正在进场?快速傅里叶变换与股价预测研究
- 连载!量化人必会的 Numpy 编程 (1)
本周要闻¶
- 市场传出的信息,有关方面正在考虑进一步下调存量房贷利率,允许规模高达 38 万亿元人民币的存量房贷寻求转按揭,以降低居民债务负担、提振消费。
截至周六,上述传闻并未获得官方证实。 - 8 月份,PMI 为 49.1%,环比下降 0.3 个百分点。从企业规模看,大型企业 PMI 为 50.4%,仍高于临界点;中、小型企业 PMI 分别为 48.7%和 46.4%,环比下降 0.7 和 0.3 个百分点。
8 月 PMI 受高温天气影响,并未显著超预期 - 8 月 30 日下午,国家市场监督管理总局宣布阿里巴巴完成三年整改,取得良好成效。阿里巴巴股价从 2020 年峰值以来,跌去七成。
- 美东时间周五,美股三大指数集体收涨,道指收涨 0.55%,报 41563.08 点,创历史新高。标普 500 上涨 1.01%,纳斯达克上涨 1.13%。美联储青睐的 7 月份 PCE 通胀数据基本符合预期,市场押注 9 月美联储大幅降息的可能性减少,但市场仍然预计 11 月或 12 月可能会有大幅降息。
- 易方达纳斯达克 100ETF 发布 2024 年中期报告,常州投资集团持有 5.92%份额,成为第一大持有人。该 ETF 在去掉净值上涨 49.21%的情况下,今年仍上涨 14.91%。该 ETF2017 年发行,现净值 3.16。
- 半年报第一股!桐昆股份发布半年报,公司实现净利润 10.65 亿元,同比增长 911.35%,为已发布半年报公司中净利润增速最高。报告期内,涤纶长丝行业下游需求较去年同期边际改善显著,产品销量与价差有所增大,行业整体处于复苏状态。整体看,电子行业成大赢家,与上年同期相比,电子行业营收增速高居首位,上半年整体营收为 1.59 万亿元,同比增长 17.3%。
下周看点¶
- 周五市场传闻,下调存量房贷利率正在考虑中,随即房地产 ETF 大涨,银行股大跌以回应传闻,但尾盘回落,涨停个股纷纷炸板。下周,此传闻是被证实还是被证伪?或将对市场有重要影响。
- 周一财新制造业 PMI 发布
- 周五,2024 低空经济发展大会将于 9 月 6 日至 8 日在芜湖举办
- 周五,美国 8 月失业率和非农报告公布
主力正在进场?快速傅里叶变换与股价预测研究¶
一个不证自明的事实:经济活动是有周期的。但是,这个事实似乎长久以来被量化界所忽略。无论是在资产定价理论,还是在趋势交易理论中我们几乎都找不到周期研究的位置 -- 在后者语境中,大家宁可使用“摆动”这样的术语,也不愿说破“周期”这个概念。
这篇文章里,我们就来探索股市中的周期。我们将运用快速傅里叶变换把时序信号分解成频域信号,通过信号的能量来识别主力资金,并且根据它们的操作周期进行一些预测。最后,我们给出三个猜想,其中一个已经得到了证明。
FFT - 时频互转¶
(取数据部分略)。
我们已经取得了过去一年来的沪指。显然,它是一个时间序列信号。傅里叶变换正好可以将时间序列信号转换为频域信号。换句话说,傅里叶变换能将沪指分解成若干个正弦波的组合。
1 2 3 4 5 6 7 8 | |
1 2 3 4 5 | |
我们得到的输出如下:
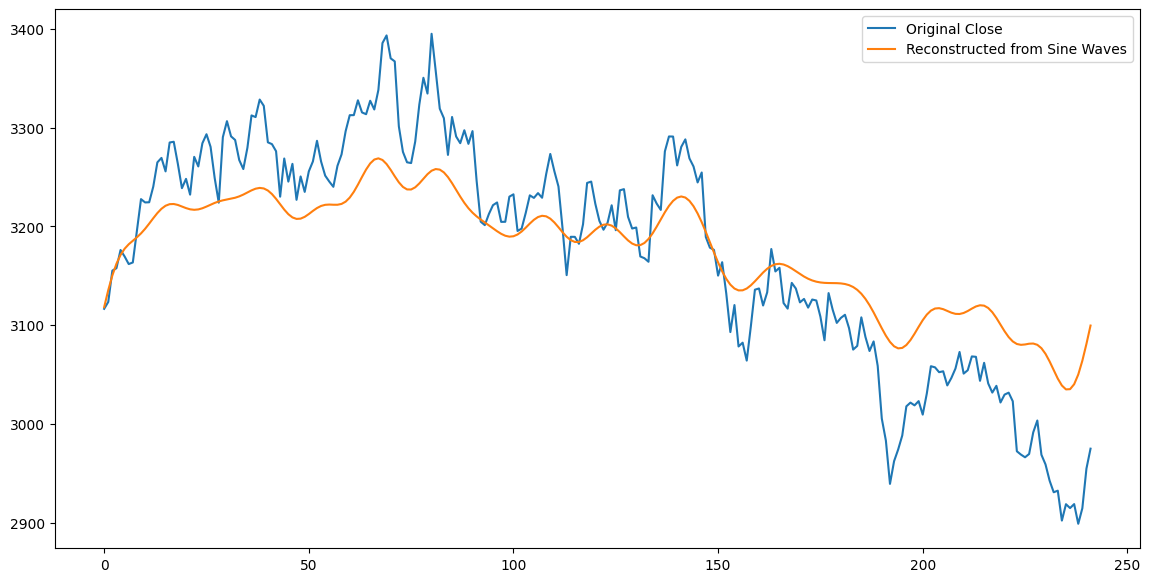
在数字信号处理的领域,时间序列被称为时域信号,经过傅里叶变换后,我们得到的是频域信号。时域信号与频域信号可以相互转换。Numpy 中的 fft 库提供了 fft 和 ifft 这两个函数帮我们实现这两种转换。
np.fft.fft 将时域信号变换为频域信号,转换的结果是一个复数数组,代表信号分解出的各个频率的振幅 -- 也就是能量。频率由低到高排列,其中第 0 号元素的频率为 0,是直流分量,它是信号的均值的某个线性函数。
np.ff.ifft 则是 fft 的逆变换,将频域信号变换为时域信号。
将时域信号变换到频域,就能揭示出信号的周期性等基本特征。我们也可以对 fft 变换出来的频域信号进行一些操作之后,再变换回去,这就是数字信号处理。
高频滤波和压缩¶
如果我们把高频信号的能量置为零,再将信号逆变换回去,我们就会得到一个与原始序列相似的新序列,但它更平滑 -- 这就是我们常常所说的低通滤波的含义 -- 你熟悉的各种移动平均也都是低通滤波器。

在上面的代码中,我们只保留了前 20 个低频信号的能量,就得到了与原始序列相似的一个新序列。如果把这种方法运用在图像领域,这就实现了有损压缩 -- 压缩比是 250/20。
在上世纪 90 年代,最领先的图像压缩算法都是基于这样的原理 -- 保留图像的中低频部分,把高频部分当成噪声去掉,这样既保留了图像的主要特征,又大大减少了要保存的数据量。
当时做此类压缩算法的人都认识这位漂亮的小姐姐 -- Lena,这张照片是图像算法的标准测试样本。在漫长的进化中,出于生存的压力,人类在识别他人表情方面进化出超强的能力。所以相对于其它样本,一旦压缩造成图像质量下降,肉眼更容易检测到人脸和表情上发生的变化,于是人脸图像就成了最好的测试样本。
 Lena
Lena
Lena 小姐姐是花花公子杂志的模特,这张照片是她为花花公子 1972 年 11 月那一期拍摄的诱人照片的一小部分 -- 在原始的照片中,Lena 大胆展现了她诱人的臀部曲线,但那些不正经的科学家们只与我们分享了她的微笑 -- 从科研的角度来讲,这也是信息比率最高的部分。
无独有偶,在 Lena 成为数字图像处理的标准测试样本之前,科学家们一直使用的是另一位小姐姐的照片,也出自花花公子。
好,言归正传。我们刚刚分享了一种方法,去掉信号中的高频噪声,使得信号本身的意义更加突显出来。我们也希望在证券分析中使用类似的技法,使得隐藏在 K 线中的信号显露出来。
但如果我们照搬其它领域这一方法,这几乎就不算研究,也很难获得好的结果。实际上,在证券信号中,与频率相比,我们更应该关注信号的能量,毕竟,我们要与最有力量的人站在一边。
 愿原力与你同在 -- 星球大战
愿原力与你同在 -- 星球大战
所以,我们换一个思路,把分解后的频域信号中,能量最强的部分保留下来,看看它们长什么样。
过滤低能量信号¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
1 2 3 4 5 6 7 8 9 10 | |
FFT 给出的频率总是一正一负,我们可以简单地认为,负的频率对我们没有意义,那是一种我们看不到、也无须关心的暗能量。所以,在代码中,我们就忽略了这一部分。
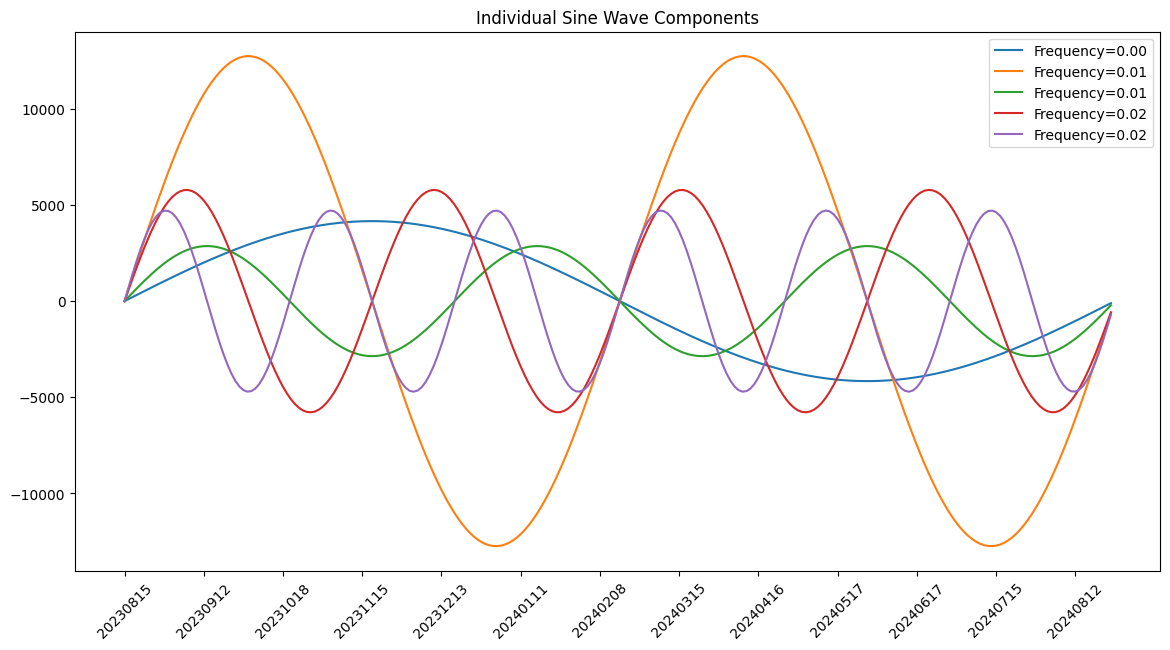
我们看到,对沪指走势影响最强的波(橙色)的周期是 7 个月左右:从峰到底要走 3 个半月,从底到峰也要走 3 个半月。由于它的能量几乎是其它波的一倍,所以它是主导整个叠加波的走势的:如果其它波与它同相,叠加的结果就会使得趋势加强;反之,则是趋势抵消。其它几个波的能量相仿,但频率不同。
这些波倒底是什么呢?它可以是一种经济周期,但是说到底,经济周期是人推动的,或者反应了人的判断。因此,我们可以把波动的周期,看成资金的操作周期。
从这个分解图中,我们可以猜想,有一个长线资金(对应蓝色波段),它一年多调仓一次。有一个中线资金(对应橙色波段),它半年左右调一次仓。其它的资金则是短线资金,三个月左右就会做一次仓位变更。还有无数被我们过滤掉的高频波段,它们操作频繁,可能对应着散户,但是能量很小,一般都可以忽略;只有在极个别的时候,才能形成同方向的叠加,进而影响到走势。
现在,我们把这几路资金的操作合成起来,并与真实的走势进行对比,看看情况如何:
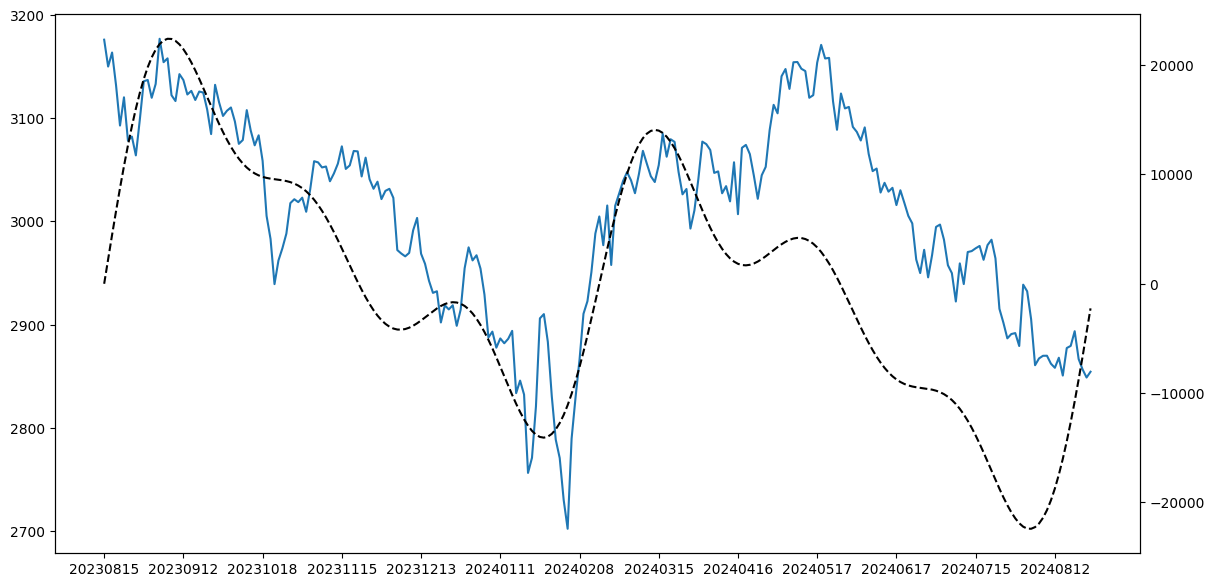
在大的周期上都基本吻合,也就是这些资金基本上左右了市场的走势。而且,我们还似乎可以断言,在 3 月 15 到 5 月 17 这段时间,出现了股价与主力资金的背离趋势:主力资金在撤退了,但散户还在操作,于是,尽管股价还在上涨,但最终的方向,由主力资金来决定。
Tip
黑色线是通过主力资金波段合成出来的(对未来有预测性),在市场没有发生根本性变化之前,主力的操作风格是相对固定的,因此,它可能有一定的短时预测能力。如果我们认可这个结论的话。那么就应该注意到,末端部分还存在另一个背离 -- 散户还在离场,但主力已经进场。当然,关于这一点,请千万不要太当真。
关于直流分量的解释¶
我过去一直以为直流分量表明资产价格的趋势,但实际上所有的波都是水平走向的 -- 但只有商品市场才是水平走向的,股票市场本质上是向上的。所以,直流分量无法表明资产价格的趋势。
直到今天我突然涌现一个想法:如果你把一个较长的时序信号分段进行 FFT 分解,这样会得到若干个直流分量。这些直流分量的回归线才是资产价格的趋势。
这里给出三个猜想:
-
如果分段分解后,各个频率上的能量分布没有显著变化,说明投资者的构成及操作风格也没有显著变化,我们可以用 FFT 来预测未来短期走势,直到条件不再满足为止。
-
沪指 30 年来直流分量应该可以比较完美地拟合成趋势线,它的斜率就等于沪指 20 年回归线的斜率。
- 证券价格是直流分量趋势线与一系列正弦波的组合。
下面我们来证明第二个猜想(过程略)。最终,我们将直流分量及趋势线绘制成下图:
而 2005 年以来的 A 股年线及趋势线是这样的:
不能说十分相似,只能说几乎完全一致。
趋势线拟合的 p 值是 0.055 左右,也基本满足 0.05 的置信度要求。
这篇文章是我们《因子投资与机器学习策略》中的内容,出现在如何探索新的因子方法论那一部分。对 FFT 变换得到的一些重要结果,将成为机器学习策略中用以训练的特征。更多内容,我们课堂上见!
量化人必会的 NUMPY 编程 (1) - 核心语法¶
1. 基本数据结构¶
NumPy 的核心数据结构是 ndarray(即 n-dimensional array,多维数组)数据结构。这是一个表示多维度、同质并且大小固定的数组对象。
ndarray 只能存放同质的数组对象,这样使得它无法表达记录类型的数据。因此,numpy 又拓展出了名为 structured array 的数据结构。它用一个 void 类型的元组来表示一条记录,从而使得 numpy 也可以用来表达记录型的数据。因此,在 Numpy 中,实际上跟数组有关的数据类型主要是两种。
前一种数组格式广为人知,我们将以它为例介绍多数 Numpy 操作。而后一种数据格式,在量化中也常常用到,比如,通过聚宽 [^聚宽] 的 jqdatasdk 获得的行情数据,就允许返回这种数据类型,与 DataFrame 相比,在存取上有不少简便之处。我们将在后面专门用一个章节来介绍。
在使用 Numpy 之前,我们要先安装和导入 Numpy 库:
1 2 | |
一般地,我们通过别名np来导入和使用 numpy:
1 | |
为了在 Notebook 中运行这些示例时,能更加醒目地显示结果,我们首先定义一个 cprint 函数,它将原样输出提示信息,但对变量使用红色字体来输出,以示区别:
1 2 3 4 5 6 7 8 | |
接下来,我们将介绍基本的增删改查操作。
1.1. 创建数组¶
1.1.1. 通过 Python List 创建¶
我们可以通过np.array的语法来创建一个简单的数组:
1 2 | |
在这个语法中,我们可以提供 Python 列表,或者任何具有 Iterable 接口的对象,比如元组。
1.1.2. 预置特殊数组¶
很多时候,我们希望 Numpy 为我们创建一些具有特殊值的数组。Numpy 也的确提供了这样的支持,比如:
| 函数 | 描述 |
|---|---|
| zeros zeros_like |
创建全 0 的数。zeros_like 接受另一个数组,并生成相同形状和数据类型的 zeros 数组。常用于初始化。以下*_like 类推。 |
| ones ones_like |
创建全 1 的数组 |
| full full_like |
创建一个所有元素都填充为n的数组 |
| empty empty_like |
创建一个空数组 |
| eye identity |
创建单位矩阵 |
| random.random | 创建一个随机数组 |
| random.normal | 创建一个符合正态分布的随机数组 |
| random.dirichlet | 创建一个符合狄利克雷分布的随机数组 |
| arange | 创建一个递增数组 |
| linspace | 创建一个线性增长数组。与 arange 的区别在于,此方法默认生成全闭区间数组。并且,它的元素之间的间隔可以为浮点数。 |
1 2 3 4 5 6 7 8 9 10 11 12 | |
Warning
尽管 empty 函数的名字暗示它应该生成一个空数组,但实际上生成的数组,每个元素都是有值的,只不过这些值既不是 np.nan,也不是 None,而是随机值。我们在使用 empty 生成的数组之前,一定要对它进行初始化,处理掉这些随机值。
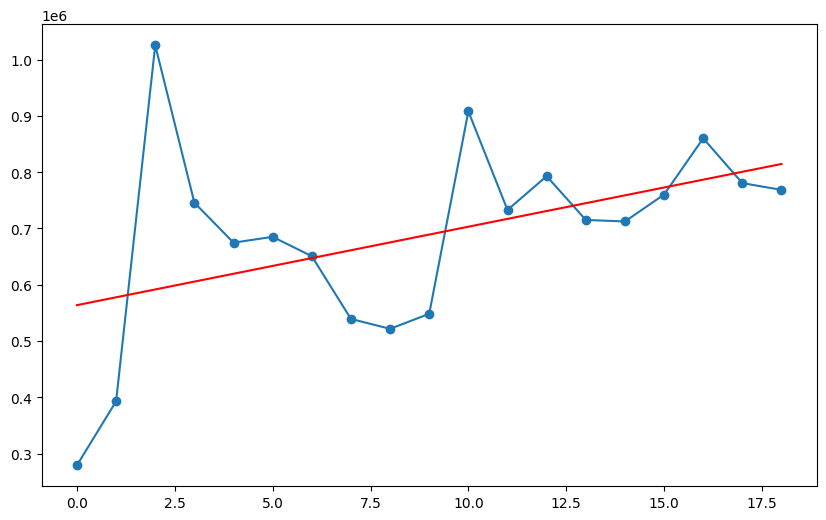
生成正态分布数组很有用。我们在做一些研究时,常常需要生成满足某种条件的价格序列,再进一步研究和比较它的特性。
比如,如果我们想研究上升趋势和下降趋势下的某些指标,就需要有能力先构建出符合趋势的价格序列出来。下面的例子就演示了如何生成这样的序列,并且绘制成图形:
1 2 3 4 5 6 7 8 9 10 11 12 | |
绘制的图形如下:

示例中还提到了 Dirichlet(狄利克雷)分布数组。这个数组具有这样的特点,它的所有元素加起来会等于 1。比如,在现代投资组合理论中的有效前沿优化中,我们首先需要初始化各个资产的权重(随机值),并且满足资产权重之和等于 1 的约束(显然!),此时我们就可以使用 Dirichlet[^dirichlet] 分布。
Info
狄利克雷,德国数学家。他对数论、傅里叶级数理论和其他数学分析学领域有杰出贡献,并被认为是最早给出现代函数定义的数学家之一和解析数论创始人之一。
1.1.3. 通过已有数组转换¶
我们还可以从已有的数组中,通过复制、切片、重复等方法,创建新的数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Question
np.copy 与 arr.copy 有何不同?在 Numpy 中还有哪些类似函数对,有何规律?
注意在 concatenate 函数中,axis 的作用:
1 2 3 4 5 6 | |
1.2. 增加/删除和修改元素¶
Numpy 数组是固定大小的,一般我们不推荐频繁地往数组中增加或者删除元素。但如果确实有这种需求,我们可以使用下面的方法来实现增加或者删除:
| 函数 | 使用说明 |
|---|---|
| append | 将values添加到arr的末尾。 |
| insert | 向obj(可以是下标、slicing)指定的位置处,插入数值value(可以是标量,也可以是数组) |
| delete | 删除指定下标处的元素 |
示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Tip
请一定运行一下这里的代码,特别是关于 insert 的部分,了解所谓的扁平化是怎么回事。
有时候我们需要修改个别元素的值,应该这样操作:
1 2 3 | |
这里涉及到如何定位一个数组元素的问题,也正是我们下一节的内容。
1.3. 定位、读取和搜索¶
1.3.1. 索引和切片¶
Numpy 中的索引和切片语法大致类似于 Python,主要区别在于对多维数组的支持:
1 2 3 4 5 6 7 8 9 10 | |
上述切片语法在 Python 中也存在,但只能支持到一维,因此,对下面的 Python 数组,类似操作会出错:
1 2 3 | |
提示 list indices must be integers or slices, not tuple。
1.3.2. 查找、筛选和替换¶
在上一节中,我们是通过索引来定位一个数组元素。但很多时候,我们得先通过条件运算把符合要求的索引找出来。这一节将介绍相关方法。
| 函数 | 使用说明 |
|---|---|
| np.searchsorted | 在有序数组中搜索指定的数值,返回索引。 |
| np.nonzero | 返回非零元素的索引,用以查找数组中满足条件的元素。 |
| np.flatnonzero | 同 nonzero,但返回输入数组的展平版本中非零的索引。 |
| np.argwere | 返回满足条件的元素的索引,相当于 nonzero 的转置版本 |
| np.argmin | 返回数组中最小元素的索引(注意不是返回满足条件的最小索引) |
| np.argmax | 返回数组中最大元素的索引 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
1 2 3 4 5 6 7 8 9 10 11 12 | |
使用 searchsorted 要注意,数组本身一定是有序的,不然不会得出正确结果。
第 10 行到第 21 行代码,显示了如何查找一个数组中符合条件的数据,并且返回它的索引。
argwhere 返回值相当于 nonzero 的转置,在多维数组的情况下,它不能直接用作数组的索引。请自行对比 nonzero 与 argwhere 的用法。
在量化中,有很多情况需要实现筛选功能。比如,在计算上下影线时,我们是用公式\((high - max(open, close))/(high - low)\)来进行计算的。如果我们要一次性地计算过去 n 个周期的所有上影线,并且不使用循环的话,那么我们就要使用 np.where, np.select 等筛选功能。
下面的例子显示了如何使用 np.select 来计算上影线:
1 2 3 4 5 6 7 8 9 | |
1 2 3 4 5 6 7 | |
np.where 是与 np.select 相近的一个函数,不过它只接受一个条件。
1 2 | |
这段代码实现了将 3 以上的数字截断为 3 的功能。这种功能被称为 clip,在因子预处理中是非常常用的一个技巧,用来处理异常值 (outlier)。
但它没有办法实现两端截断。此时,但 np.select 能做到,这是 np.where 与 np.select 的主要区别:
1 2 | |
1.4. 审视 (inspecting) 数组¶
当我们调用其它人的库时,往往需要与它们交换数据。这时就可能出现数据格式不兼容的问题。为了有能力进行查错,我们必须掌握查看 Numpy 数组特性的一些方法。
我们先如下生成一个简单的数组,再查看它的各种特性:
1 2 3 4 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
正如 Python 对象都有自己的数据类型一样,Numpy 数组也有自己的数据类型。我们可以通过arr.dtype来查看数组的数据类型。
从第 3 行到第 6 行,我们分别输出了数组的 shape, ndim, size 和 len 等属性。ndim 告诉我们数组的维度。shape 告诉我们每个维度的 size 是多少。shape 本身是一个 tuple, 这个 tuple 的 size,也等于 ndim。
size 在不带参数时,返回的是 shape 各元素取值的乘积。len 返回的是第一维的长度。
1.5. 数组操作¶
我们在前面的例子中,已经看到过一些引起数组形状改变的例子。比如,要生成一个\(3×2\)的数组,我们先用 np.arange(6) 来生成一个一维数组,再将它的形状改变为 (2, 3)。
另一个例子是使用 np.concatenate,从而改变了数组的行或者列。
1.5.1. 升维¶
我们可以通过 reshape, hstack, vstack 来改变数组的维度:
1 2 3 4 5 6 7 8 9 | |
1.5.2. 降维¶
通过 ravel, flatten, reshape, *split 等操作对数组进行降维。
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
这里一共介绍了 4 种方法。ravel 与 flatten 用法比较接近。ravel 的行为与 flatten 类似,只不过 ravel 是 np 的一个函数,可作用于 ArrayLike 的数组。
通过 reshape 来进行扁平化也是常用操作。此外,还介绍了 vsplit, hsplit 函数,它们的作用刚好与 vstack,hstack 相反。
1.5.3. 转置¶
此外,对数组进行转置也是此类例子中的一个。
比如,在前面我们提到,np.argwhere 的结果,实际上是 np.nonzero 的转置,我们来验证一下:
1 2 3 4 5 | |
两次输出结果完全一样。在这里,我们是通过.T来实现的转置,它是一个语法糖,正式的函数是transpose。
当然,由于 reshape 函数极其强大,我们也可以使用它来完成转置:
1 2 3 | |