捕捉主力-最大成交量因子
Table of Content
 因为黑夜,更能看见满天星光 | ©️ Nathan Jennings
因为黑夜,更能看见满天星光 | ©️ Nathan Jennings
今天跟一位朋友聊天,他想换到量化行业,有点担心是否有点为时已晚,又或者大环境不好。于是我用这句话鼓励他:
因为黑夜,更能看见满天星光。
低谷之中,必有转机,熬过黑暗,前方自有光明。
其实在我身边,已经有好几位『普通人』成功地转向了量化。我之前有一位策略研究员,前几天跟我通了个电话,告诉我已经有私募接洽他,希望买他的策略。他已经注册了自己的公司。他是一个真正的传奇,我会在恰当的时候,讲述他的故事,带给更多人启迪。
做你热爱的事情,不用管其它人给现在的你打上的标签,不要被他人定义。
You gotta be brave。
只要你还愿意追逐梦想,你就不是平庸的。
言归正转。
在第十二课,我承诺给大家讲如何发现新的因子。这活儿光说不练不行,我得真真正正拿出一个还没有广泛传播的因子(策略)出来。今天就来兑现这个承诺。我们探索因子,无非就是量价时空四大维度。这里面关于成交量的因子最少,所以,今天就介绍一个我自己探索的因子。
如有雷同,纯属巧合(读书太少)。这个因子是基于成交量,运用羊群效应的原理构建的。
因子还没被挖完吗?¶
在说书之前,先回答一个问题。因子难道还没有被挖掘完吗?毕竟,全世界有这么多做量化的人。
事实是,这世界算力不够,所以,还存在大量的关系没有发掘出来。小市值因子之父,Rolf Banz探索小市值因子的故事,也许能很好说明这一点。
1980年前后,Rolf Banz发表了一篇论文《The relationship between return and market value of common stocks》,向世界介绍了小市值因子。
Banz 的这篇论文并不复杂,只有 16 页纸。论文中并没有使用高深的数学,只是使用了基础的统计科学,GLS 和 OLS。如果当时有计算机可用的话,这个推导过程会显得格外简单。
甚至,我们可以仅凭他论文中的这张图来理解小市值因子:
 收益与市值分导关系
收益与市值分导关系
在这张图中,Banz把资产按市值大小分成了5组,第一组是市值最小的一组,第5组是市值最大的一组。很显然,其它几组的收益都与市值大小有着线性关系,但第一组,即小市值组有更大的月度收益,不能被线性回归。
就是这样简单的一个事实,帮助Banz获得了小市值之父的称号。如果说威廉.夏普发现了第一个因子的话,Banz就是发现第二个因子的人。
Banz 用到的数据来自 1926 年到 1975 年。这些数据就在芝大的 CRSP 数据库里。在漫长的 50 多年时间里,一直在静静地等待有人发现她的价值。芝大经济学人才辈出,期间不知道有多少人接触过这份数据。如此低垂和芳香的果实最终却被 Banz 采摘。
我想,这足以说明,在任何时代,在任何圈子,都会有一些低垂的果实,等待有心人去采摘。
但是,更加惊人的是,另一颗低垂的果实,就出现在Banz自己的论文里。在上图中,资产实际上是被分成了25组。在按市值划分的每个组内,Banz又按波动率将资产分成了5组(在图上纵向分布)。第一组是波动率最大的一组,第5组则是波动率最小的一组。
很显然,在每一个组合中,低波动率的资产收益都大于高波动率的资产。
实际上,这里出现了另外一个因子,就是低波动因子。我们回测过,日线低波动因子可以达到16.4%的年化Alpha。月线可以达到6.3%左右的年化,因子IC是0.04,相当可观。
然后,直到10年之后,Haugen和Baker才发现和命名了低波动因子。Banz做完了几乎所有工作,但却与这项发明失之交臂。
低垂的果实永远都会有的
最大成交量因子¶
这个因子也可以叫做主力因子。它的构造原理是,价格的方向是由资金里的主力决定的。因为当个体处于群体中时,其行为和决策受到群体影响,往往会失去理性,变得更加情绪化和冲动。个体往往会受到他人引导,最终会跟随头羊的方向前进,这就是羊群效应。
主力才能决定方向,决定方向的力量也就是主力。因此,主力方向是可以建模的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
这段代码的逻辑是,如果某个bar的成交量相对于过去一段时间的平均成交量异常放大(用该bar的成交量除以平均成交量,记为vr),那么它就可能是主力的操作。我们认为,该根bar的方向,有较大概率是此后主力的运作方向。
如果这根bar是阳线,它反应的是买入操作;如果这根bar是阴线,它反应的是卖出操作(记为flag)。
主力为了测试对手盘和跟风盘,在试盘之后,有可能中断操作一段时间,借此观察盘面变化。因此,我们要考察该bar之后一段时间的交易情况,把这部分成交量换算成净余成交量(记为move_balance),再除以主力操作的那个bar的成交量(『归一化』)。如果净余成交量与主力bar是同向的,说明对手盘很小(或者没有成为对手的意愿);如果净余成交量与主力bar相反且较大,则主力的意图有可能难以实现,主力可能暂时放弃操作。
我们拿一个样本测试一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
Attention
由于akshare无法按时间段获取30分钟线,并且只能获取固定长度的30分钟线(更早的会丢弃)k线,所以,这段代码运行的结果将会与下图不同。
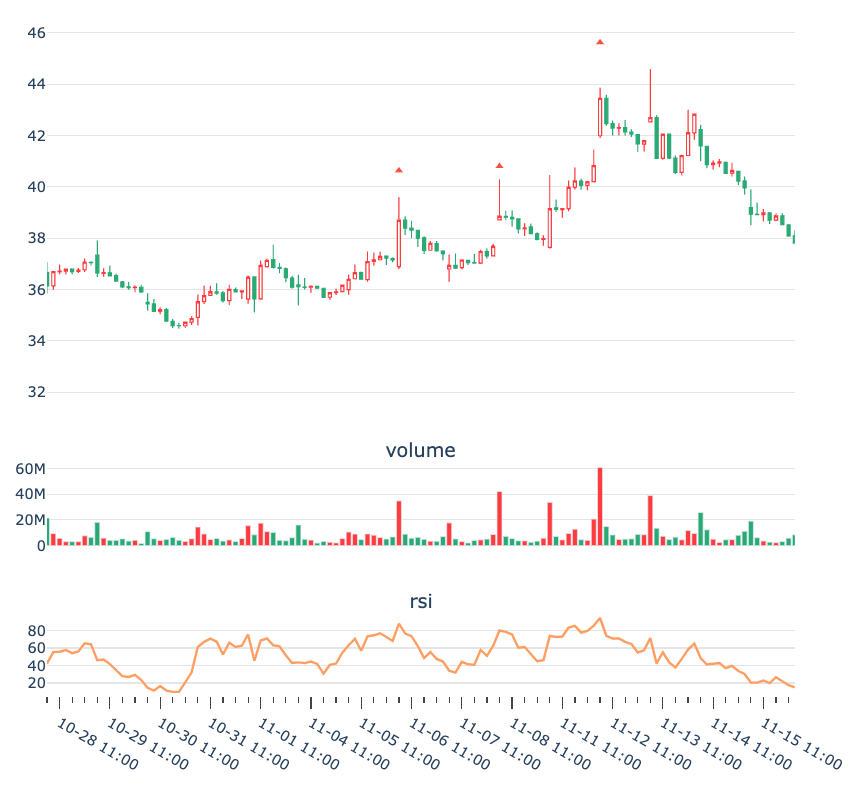
在测试中,我们设置vr的阈值为5。在一些比较激进的个股上,设置为8以上可能效果会更好。
在示例中,我们看到三个向上箭头。其中前两个出现后,随后股价下跌,但反向成交量很小,表明没有对手抛盘。于是主力随后又进行了拉升。第三个箭头出现后,此后出现了比较明显的抛压信号(墓碑线),随后股价下跌。
当然,我们还需要对其进行大规模的测试。这些正是《因子分析与机器学习策略》要介绍的内容。在因子创新上,我们从量、价、时、空四个维度,都给出了创新的思路和方向,保持关注,持续为你更新!