strategy »
ESG策略初探-01
全球资本正在用脚投票!
从化石燃料到金融市场,绿色转型已不可逆。到2024年,151个国家宣布碳中和目标,120个将其纳入法律,86个给出清晰路线图。资本正在用估值与资金流向表态:可持续发展是新的共识。而在资本对“可持续价值”的抉择中,ESG正成为衡量企业与经济体可持续竞争力的核心标尺。
1. 何为ESG
ESG是Environmental、Social和Governance的缩写。
E|环境:碳排放、能源与水资源效率、污染与减排路径、供应链环境风险。
S|社会:员工健康与安全、劳动权益与多元包容、产品安全与数据隐私、社区影响与社会投入。
G|治理:股权与董事会结构、内部控制与合规、反腐与关联交易披露、高管薪酬与激励一致性。
不同评级机构口径各异,但本质都在判断:在绿色时代的优胜劣汰中,谁更具持续创造自由现金流的能力与抗风险韧性。
那高ESG分数的公司有什么特征呢?
E,环境指标到位:
- 具有 科学碳目标 与中长期减排路线图(含范围1/2/3),并披露达成进度。
- 资本开支中绿色技术与能效改造占比上升,单位产出能耗强度、用水强度持续下降。
- 供应链设定环境准入与审计机制,重大环境事故发生率接近零并有应急预案。
S,对社会有贡献:
* 工伤率/流失率/缺勤率低于行业均值,员工满意度与培训时长可量化提升。
G,公司治理规范:
* 董事会独立性与多元化达标,设审计与风控的有效委员会,相关会议与结论可追溯。
ESG为何重要?
这些特征并非偶然,而是优质企业长期积累的结果——ESG不仅是责任的体现,更是企业韧性与可持续能力的外化。
传统财务与行情因子早已拥挤,Alpha 衰减肉眼可见;
同质化策略在信息完全竞争下只能互相稀释。要想在边际上多挖一点超额收益,就得去“信息尚未充分交易”的地方找增量。
ESG 正是当前另类数据里仍未被彻底开垦的蓝海,尤其是更高频的 ESG 资讯与事件数据,在国内市场已被实证为具备可观的超额收益潜力与更好的风险暴露结构,且通过负面事件剔除还能显著提升信息比率。
把 ESG 加入信号池,不是为了贴道德标签,而是为了引入“异质信息源”,降低拥挤度、改善左尾风险,同时提升组合在不同市况下的稳健性。
获取之前先选源:ESG 数据该怎么挑
为避免“垃圾进垃圾出”,需要确保我们的数据是能交易的口径:
接下来我们将展示数据的下载操作。
2. 下载数据
数据的下载我们借助Akshare来实现,目前Tushare平台不提供ESG数据。
2.1. 新浪财经ESG数据
运行下列代码,我们就可以获取新浪上所有的ESG数据:
| import akshare as ak
import pandas as pd
#新浪数据下载
stock_esg_rate_sina_df = ak.stock_esg_rate_sina()
|
| sina = data_home / "sina_esg_data.xlsx"
# 保存为Excel文件
stock_esg_rate_sina_df.to_excel(sina, index=False)
# 输出保存成功的消息
print(f"File saved at: {sina}")
stock_esg_rate_sina_df
|
新浪ESG数据结构如下图所示:
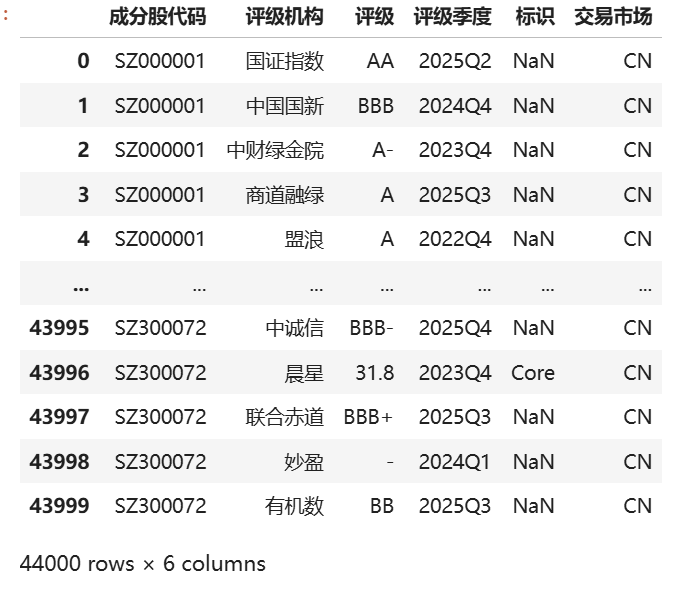
针对这种ESG数据格式的分析中,我们通常有两条思路:
1. 从评级机构 的角度出发,把不同机构的数据拆分开来,比较它们在维度划分与打分体系上的差异;
2. 根据单只股票查询各个评级机构的不同评价。
我们以中国国新为例:
| rating_agencies = df['评级机构'].unique()
# 字典装机构
df_institution = {}
# 按评级机构分割数据
for agency in rating_agencies:
df_institution[agency] = df[df['评级机构'] == agency]
df_zhongxin = df_institution.get('中国国新')
|
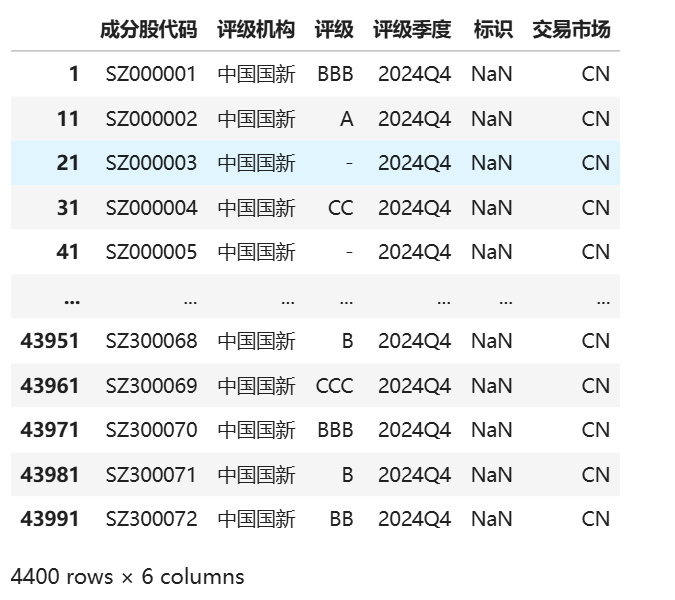
这样我们便能直观地看到中国国新对各个上市公司的评级
那如果我们想要看看一个公司的所有评级情况呢?同样可以实现:
| stock_lists = df['成分股代码'].unique()
# 字典装机构
df_stocks = {}
# 按评级机构分割数据
for stocks in stock_lists:
df_stocks[stocks] = df[df['成分股代码'] == stocks]
df_s = df_stocks.get('SZ300072')
df_s
|
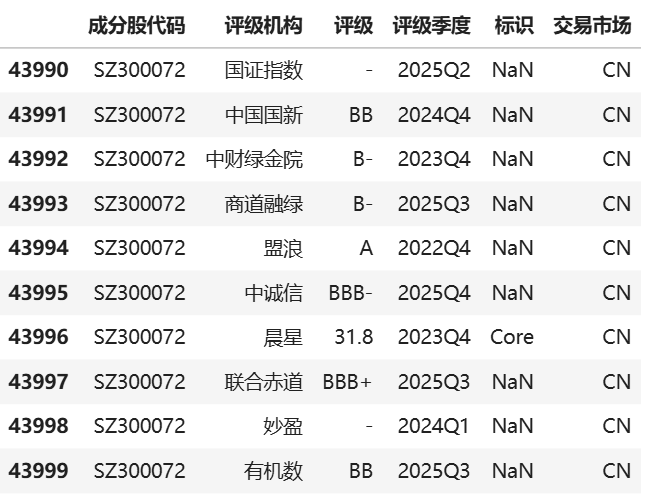
由此,我们已经完整地分析了Akshare数据库中对于新浪财经ESG数据的下载,其他来源数据下载方式类似,接下来我们来展示一下别的评级机构的数据特征。
2.2. msci ESG数据
通过以下代码片段来获取msci的ESG数据:
| stock_esg_msci_sina_df = ak.stock_esg_msci_sina() #msci
msci = data_home / "msci_esg_data.xlsx"
stock_esg_msci_sina_df.to_excel(msci, index=False)
print(f"File saved at: {msci}")
stock_esg_msci_sina_df
|
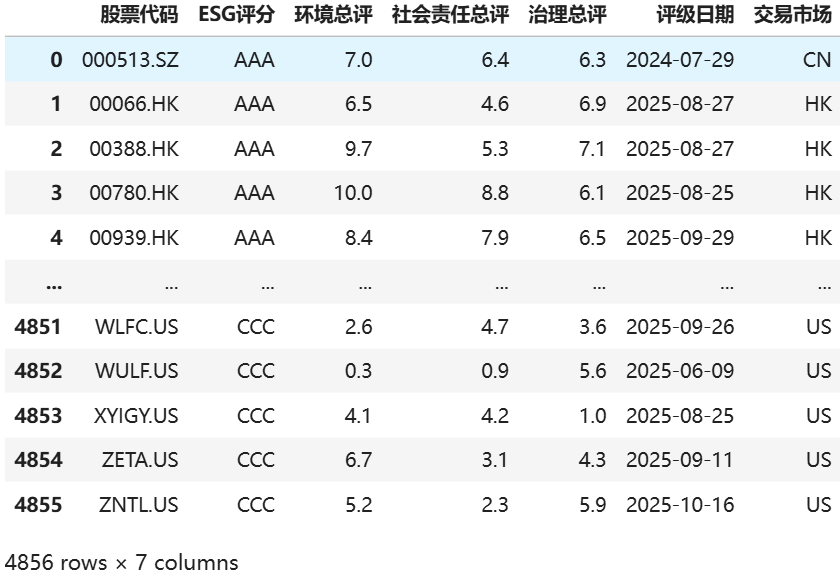
msci的评级涵盖了不同市场的公司,其评分内容详实,既有ESG总分评级也有单项评分,如果数据齐全的话是非常适合用于后续的量化分析的。
可惜该指标的国内公司样本数量偏少,不适合我们后续分析。
2.3. 路孚特ESG数据
通过以下代码片段来获取路孚特的ESG数据:
| stock_esg_rft_sina_df = ak.stock_esg_rft_sina() #路孚特
rft = data_home / "rft_esg_data.xlsx"
stock_esg_rft_sina_df.to_excel(rft, index=False)
print(f"File saved at: {rft}")
stock_esg_rft_sina_df
|
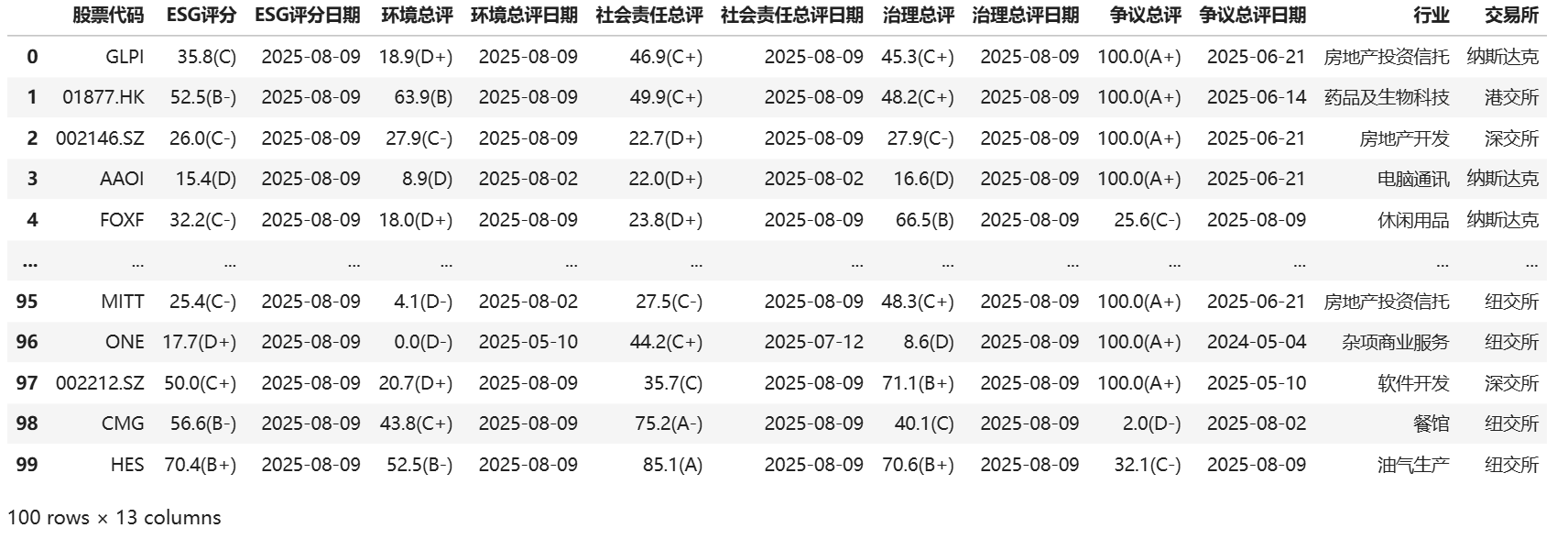
路孚特采取了评级和评分共同披露的形式,但也是信息有限,一共只有100只股票的截面信息,大部分也是境外股票,同样不适合后续研究。
2.4. 华证ESG数据
| stock_esg_zd_sina_df = ak.stock_esg_zd_sina() #秩鼎
zd = data_home / "zd_esg_data.xlsx"
stock_esg_zd_sina_df.to_excel(rft, index=False)
print(f"File saved at: {zd}")
stock_esg_zd_sina_df
|
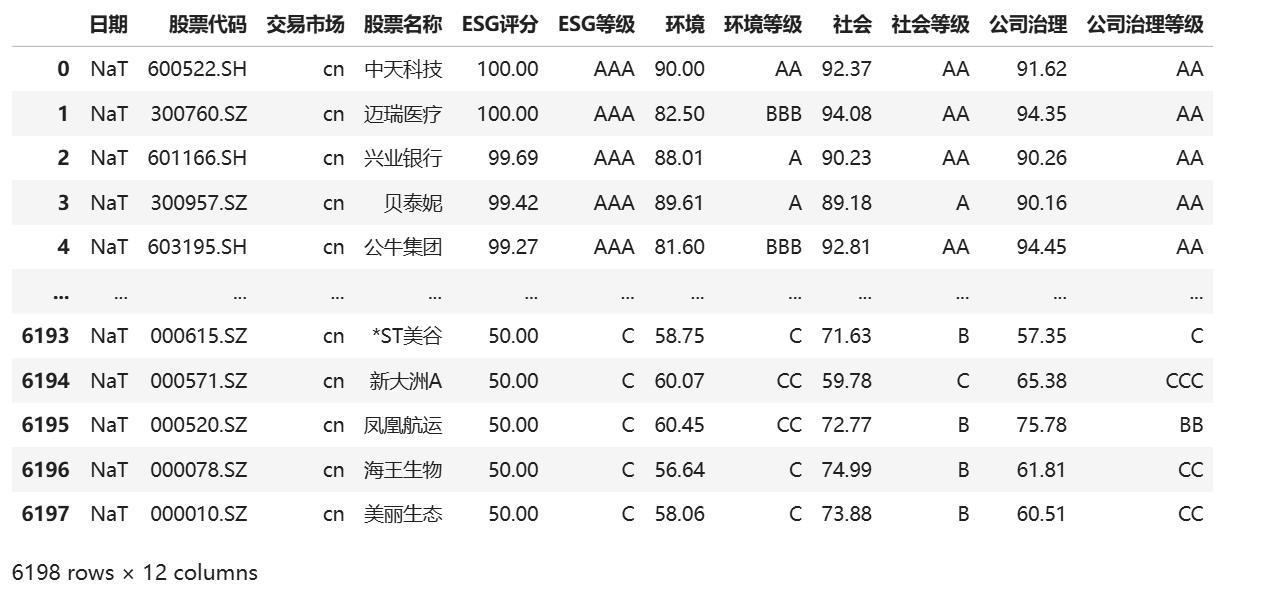
可以看到通过Akshare获取的华证数据是没有日期的,可能是接口出bug了
但是华证ESG评级变量齐全:针对国内公司,评分从总分到各个单项都有披露,因此我们决定选用华证数据进行后续策略的试验。
2.5. 评分比较
接下来对以上数据进行简短总结:
| 分数来源 |
评级情况 |
| 新浪 |
涵盖多家评级机构,推荐拆分后分析 |
| msci |
ESG总分为AAA-CCC七个等级,另外各单项有具体评分。 |
| 路孚特 |
满分100,ESG总分以及其各个单项均有披露。 |
| 华证 |
满分100,ESG总分以及其各个单项均有详细披露。 |
3. 基金ESG评级
下面,我们来看一个 ESG 数据的简单应用,即如何获得基金的在不同时间点上的 ESG 评级。目前还没有比较好的渠道可以直接获得这一数据,我们必须用『穿透式』方式,来自己计算出基金的 ESG 评级。
前面提到过,华政的数据分类子项比较齐全,可研究性更强一点,所以,我们希望通过华证的数据来计算基金的 ESG评级。但是,通过 Akshare 的API,我们只能拿到最新一期的截面数据,无法获取到历史数据。
所以我们从第三方渠道单独下载了完整的华证评级数据,在Quantide Research平台上读者可以看到这些文件。
接下来我们以华夏大盘精选混合A(000011.OF)开始对基金ESG进行评级估算:
评级的主要思路是按照权重,对基金的成分股进行加权计算,所以第一步我们需要知道基金持有了哪些股票,用tushare实现:
| pro = ts.pro_api()
df_hold = pro.fund_portfolio(ts_code='000011.OF')
df_hold
|
持仓信息样例如下所示:
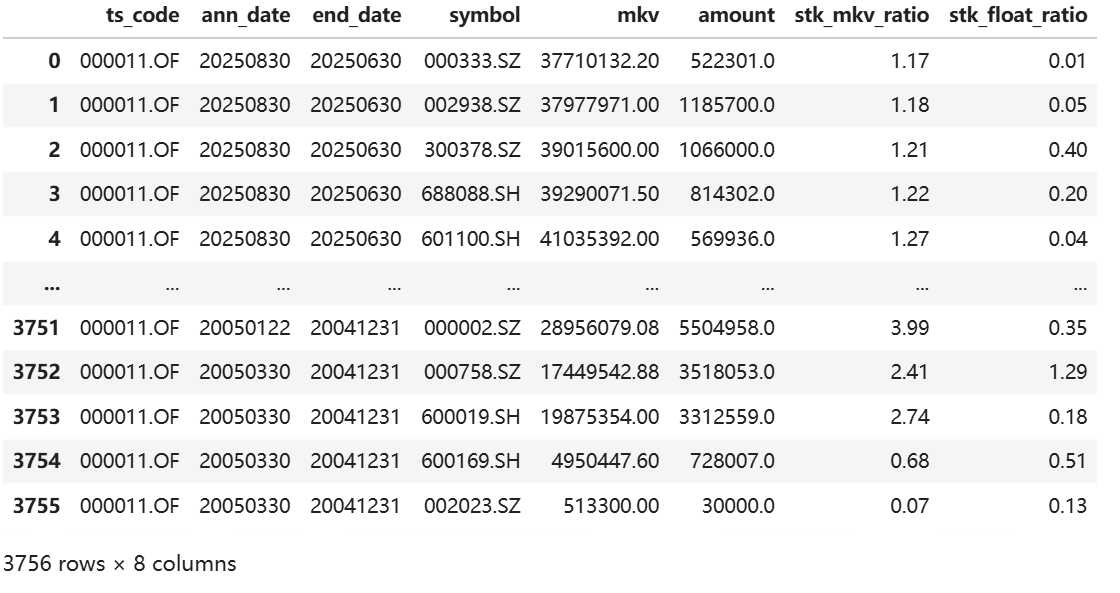
有了持仓信息之后,我们与ESG数据进行匹配,然后按照持仓市值加权运算,就可以算出基金ESG在不同时期的分数了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87 | import pandas as pd
import numpy as np
# ================= 0) 清洗函数 =================
def to_datetime_safe(s):
# 统一成字符串,去掉空白,把'--'、空串、'nan'统统变 NaT,再混合解析
s = s.astype(str).str.strip().replace({"--": None, "": None, "nan": None, "NaN": None})
return pd.to_datetime(s, errors="coerce", format="mixed")
def to_quarter_end(dt_series):
# 转成季度末日期(Timestamp,00:00时间)
q_end = dt_series.dt.to_period("Q").dt.to_timestamp(how="end")
return q_end.dt.normalize()
# ================= 1) 持仓(df_hold)日期与季度 =================
df_hold = df_hold.copy()
df_hold['end_date'] = to_datetime_safe(df_hold['end_date'])
df_hold['quarter'] = to_quarter_end(df_hold['end_date'])
# 仅保留需要列并汇总权重(市值)
hold_q = (df_hold
.dropna(subset=['symbol'])
[['ts_code','symbol','quarter','mkv']]
.groupby(['ts_code','symbol','quarter'], as_index=False)['mkv'].sum())
# ================= 2) ESG(df_esg)日期与季度 =================
df_esg = df_esg.copy()
# 标准化常见列名(你的表可能叫“证券代码”“评级日期”“综合评级”“综合得分”等)
rename_map = {
'证券代码':'股票代码',
'评级日期':'评级日期',
'综合评级':'华政评级',
'综合得分':'综合得分',
'E得分':'E得分', 'S得分':'S得分', 'G得分':'G得分'
}
df_esg.rename(columns={k:v for k,v in rename_map.items() if k in df_esg.columns}, inplace=True)
# 日期安全解析
df_esg['评级日期'] = to_datetime_safe(df_esg['评级日期'])
df_esg['quarter'] = to_quarter_end(df_esg['评级日期'])
# 只保留每股票每季度“最后一条”(按评级日期排序)
df_esg_sorted = df_esg.sort_values(['股票代码','quarter','评级日期'])
# 选出可用的得分列:优先综合得分,其次 E/S/G 平均;再不行才用字母评级映射
score_cols = [c for c in ['综合得分','E得分','S得分','G得分'] if c in df_esg_sorted.columns]
# 构造最终 esg_score
df_esg_sorted['esg_score'] = pd.to_numeric(df_esg_sorted['综合得分'], errors='coerce')
# 每股票每季度仅留最后一条
df_esg_q = (df_esg_sorted
.drop_duplicates(['股票代码','quarter'], keep='last')
[['股票代码','quarter','esg_score']])
# ================= 3) 合并并按持仓权重加权 =================
merged = hold_q.merge(df_esg_q.rename(columns={'股票代码':'symbol'}),
on=['symbol','quarter'], how='left')
def _weighted_score(g):
g_valid = g.dropna(subset=['esg_score']).copy()
if len(g_valid) == 0:
return pd.Series({'fund_esg_score': np.nan,
'coverage_weight': 0.0,
'n_positions': len(g),
'n_rated': 0})
w = g_valid['mkv'].values
w = w / w.sum()
s = float(np.dot(w, g_valid['esg_score'].values))
coverage = float(g_valid['mkv'].sum() / g['mkv'].sum())
return pd.Series({'fund_esg_score': s,
'coverage_weight': coverage,
'n_positions': len(g),
'n_rated': len(g_valid)})
fund_quarter_esg = (merged
.groupby(['ts_code','quarter'])
.apply(_weighted_score)
.reset_index()
.sort_values(['ts_code','quarter'])
)
fund_quarter_esg
|
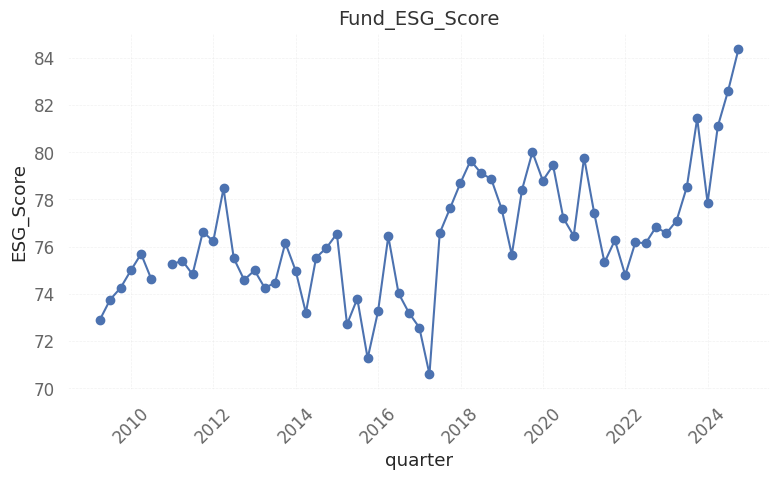
最后,我们可以把该基金历年的 ESG 得分走势画出来:
1
2
3
4
5
6
7
8
9
10
11
12
13 | x = pd.to_datetime(fund_quarter_esg['quarter'])
y = fund_quarter_esg['fund_esg_score']
# 3. 画图
plt.figure(figsize=(8,5))
plt.plot(x, y, marker='o')
plt.title('Fund_ESG_Score', fontsize=14)
plt.xlabel('quarter')
plt.ylabel('ESG_Score')
plt.grid(True, ls='--', alpha=0.4)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
|
如需获取完整代码,可以订阅「Quantide Research」平台会员。平台介绍及付费方式https://mp.weixin.qq.com/s/j1r-cH_3Agc7fz1WwGrYFQ