量化面试神题:圆上随机点的概率陷阱
Table of Content
常常有人问,做量化交易需要什么样的数学基础?
不同领域的量化研究员需要数学基础是不一样的,一般是期权 > 高频 > 期货 > 股票中低频量化。
今天我们就聊聊各个领域要求的数学基础,并且以一道经典的量化面试题(来自绿皮书),介绍在概率知识上,从低级到中级,机构可能会考察哪些概念。
本文较长,将分两部分刊出。
股票中低频量化¶
我们需要掌握基础的概率论与数理统计。比如统计变量的分布特征(均值、方差、分位数);掌握什么是假设检验(如何判断显著性等);线性回归;相关性分析等。
统计变量的分布特征是基础中的基础,在量化中无时不刻被使用。比如,要评判两个量化策略谁更好?最基础的指标就是它的日均收益率。但是,如果你有基础的统计学知识,就很容易明白,均值相同,并不意味着两个随机变量具有同一性。因此,就很容易理解为什么要使用几何收益代替日均收益率来判断两个策略赚钱能力的指标了。扎实的统计学基础,可以帮助我们拓展概念,懂得什么场合下使用哪一个概念。这只是其中一例。
在多因子策略中,我们会广泛使用线性回归,来确定因子权重(因子权重对远期收益率的回归)。此外,在多因子策略中,我们需要通过正交化,以抵消关联因子的影响,常常也是通过线性回归求残差的方法,来获得正交化后的因子。
在判断因子有效性时,就会涉及到显著性检验相关理论,要理解什么是 p 值,什么是 t 值。
相关性分析也用在因子挖掘中。我们通过相关性检验(Pearson 或者 Spearman)来判断因子对远期收益的涨跌是否有相关性。
当然,我们还要掌握正态分布。了解它的分布特性,几个关键分位数(\(\mu + \sigma, \mu + 2\sigma, \mu + 3\sigma\))等,了解它产生的原理以及适用范围。
线性代数和微积分这一块,如果不接触机器学习,可以不必掌握太深入。在使用时,借用现成的 Python 库即可。但是建议深入掌握 PDF(概率密度函数)和 CDF(累积分布函数),掌握它们之后,理解初等概率问题,就会像掌握微积分之后,再来解小学奥数问题那么简单。
这些知识基本上都涵盖在《量化 24 课》中。
期货量化¶
这部分要求掌握时间序列分析,比如 GARCH 模型,协整检验等。比如,我们可能有一个螺纹钢期货跨期套利策略,要确认近月与远月合约价格存在长期均衡关系,然后才有套利的基础。这就要求深入理解时间平稳序列的意义,协整的概念以及如何进行协整检验等等。
高频量化¶
高频量化涉及到订单流建模、短期价格预测、最优下单策略等算法,对概率与数理统计的要求就更高一些。
比如,在订单流方向预测中,往往会用到条件概率、极值理论。对价格分布建模时,就要用到核密度估计(KDE 法)建模,通过假设检验来验证。在订单到达模型中,可能要使用泊松过程;在短期价格状态转移预测时,可能要使用马尔可夫链。这些都是随机过程中的内容,属于概率论中的高级阶段了。
此外,还常常涉及优化理论(凸优化),比如,高频做市商的最优报价策略,就是一个凸优化求解过程,也可能使用动态规划算法(最优下单时点选择)。
当然,也存在另外一条路径,就是深入掌握机器学习理论与实践框架之后,力大飞砖,这种情况下,对上述数学的要求可能可以降低。
由于高频量化对速度要求很高,因此很多运算要求通过矩阵运算来提高效率。所以,也会对线性代数有一些要求。
期权量化¶
期权量化中的核心问题是衍生品定价、波动率建模、风险对冲(Greeks 计算)。这部分对数学的要求最高,一般要掌握布朗运动、伊藤引理、随机微分方程、偏微分方程、高阶导数(用于 Greeks 的计算)、复分析等。
总之,期权是一种被『设计』出来的衍生品,对数学深度和推导能力要求极高,是量化领域中,对数学能力要求最高的一个。
那么,在机构招人时,对概率、统计题一般会考察到什么深度?我们下面拿一道机构面试题作为例子,说明在不涉及期权交易的情况下,我们需要对概率统计掌握到什么程度。
我们会讲得细一点,题目的解法会分两部分,分步涵盖初等概率解法和积分、PDF 等工具解法。
多点共半圆问题¶
这是绿皮书上的一道题:一个圆里随机取 n 个点,它们在同一个半圆的概率是多少?
Tip
不要把这个问题与经典的多点共圆问题混淆。多点共圆是指在同一个平面上的 n 个点,是否存在一个共同的圆,使得这 n 个点都落在该圆的圆周上。
这道题可以用初等概率知识来解答,也可以使用积分、PDF 等工具来解答。这里我们两种解法都提供,特别是通过后一种,把相关的概念都串联起来。
初等概率法¶
初等概率侧重直观理解和基本计算,不涉及过于复杂的数学工具。但如果构思巧妙,也可以解决比较复杂的概率问题。本题即是一例。
我们首先引入下图:
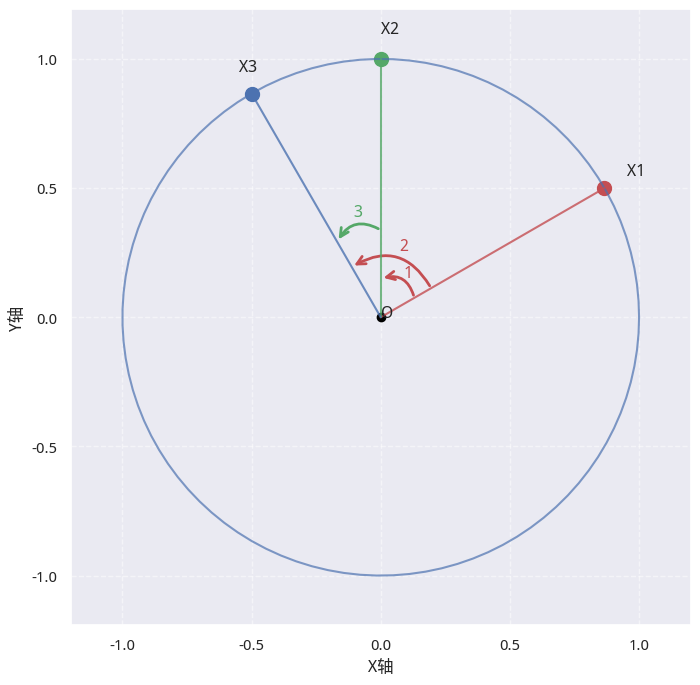
在图中,三个点可能张出的最大角可能是 \(\angle X_1OX_2\) 、\(\angle X_1OX_3\) 和 \(\angle X_3OX_2\) 之一(在此图中为 \(\angle X_1OX_3\)),同时,它还存在一个对称角即 \(\angle X_3OX_1\),本质上,它们指的是同一段弧。
假设我们把 \(n\)个点中能张出的最大角记为 \(\alpha\) , 则当 $\alpha \le \pi $ 时,就满足题目条件。因此,我们要统计『n个点是否在同一半圆』这一事件( \(a\) ),实际上就是『n个点所能张出的最大角 \(\alpha \le \pi\) 』是否成立( \(b\) ),两者具有同一性:也就是,我们对事件 \(b\) 计数,也就是对事件 \(a\) 计数。
现在,我们就正式开始讨论。
第一步,假设我们从 n 个点中,随机抽取一个点进行固定(记该点为 \(X_1\)),以此为基础,计算后面发生符合题目要求情况的概率,记为 \(P_{X_1}\) 。根据全概率公式,有
由于在随机抽取中,每个点都是平等的,所以每个 \(P_{X_i}\) 在概率上应该是一致的。接下来我们讨论\(P_{X_i}\) 。
第二步,假设我们选中第 i 个点作为固定点,则余下的 \(n-1\) 个点,全部落在 \(X_i\) 的右侧(即线 \(X_iO\) 的右侧)的概率是 \(\frac{1}{2^{n-1}}\) 。因为线 \(X_iO\) 把圆分成两等份,而点落入任意部分是一个独立、概率均为 \(\frac{1}{2}\) 的随机事件。因此,我们得到此时 \(P_A\)的概率为:
这里的\(P_{X_iL}\)是事件(其余点全部落在\(X_iO\)的左侧、且张角<\(\pi\))。\(P_{X_iR}\)则是事件(其余点全部落在\(X_iO\)的右侧、且张角<\(\pi\))。
所以,现在所有事件的总和概率是:
下面,我们来检验这个结论的正确性。当 \(n = 2\)时,得到概率 \(P = 2\),这显然是错误的,原因何在?
原来,在全概率公式中,要求我们只统计互斥事件。但是,在前面的统计中,存在看起来不同,实际上一样的事件,被重复统计了。
我们以两个点 \(X_1, X_2\)为起点开始讨论。此时,我们有:
由于同在一个圆上的两点,在任何时候,都是共半圆(左侧不行就右侧)的,所以,任选一点开始计数,另一点落入该点的半圆内的概率都是1,这一点是确信无疑的。
问题是,两点之间的最大张角, \(\angle X_1OX_2\) 与 \(\angle X_2OX_1\) 实际上是同一个事件,我们却统计了两次,即,当我们选定 \(X_1\) 固定时,我们统计 \(X_2\) 落入 \(X_1\) 的右半侧时,就把张角 \(\angle X_1OX_2\) 对应的事件统计了一次;而固定 \(X_2\) ,统计 \(X_1\) 落入 \(X_2\) 的左半侧时,张角 \(\angle X_2OX_1\) 对应的事件也会统计进来,但它实际上是与 \(\angle X_1OX_2\) 对应的是同一事件。因此,我们对式5的结果应该除以2.
推而广之,对任何一个满足条件的最大张角 \(\angle X_iOX_j\) ,我们都会对同一事件统计两次,一次是固定 \(X_i\) 时,一次是固定 \(X_j\) 时。因此,对任意 \(n\) 个点,我们都应该对式4)中求得的概率除以2。于是,我们得到最终的公式如下:
在初等概率的范畴内,我们需要理解一些初级分布(比如均匀分布、伯努利分布)、独立事件等等原理,并巧用几何概率的思想来进行解题。
在下一篇,我们将全面还原概率、概率密度函数、分布函数、期望等关键概念,以及数学概念是如何由具体到抽象的。