谁压垮了这个基站?用XGBoost如何进行时序事件归因
Table of Content
当一个系统(比如交易系统、服务器基站)意外宕机,我们能否像侦探一样,从海量监控数据中抽丝剥茧,找出导致事故的“罪魁祸首”?这是我们的一位学员最近提出来的一个问题。
本文将通过一个“基站宕机”的真实案例,演示如何利用机器学习模型XGBoost,对时序事件进行归因分析。这个问题看似与量化无关,但其核心思想——从多个潜在因素(时序因子)中定位关键驱动因素——与量化中的多因子模型如出一辙。
我们的“案发现场”数据如下:
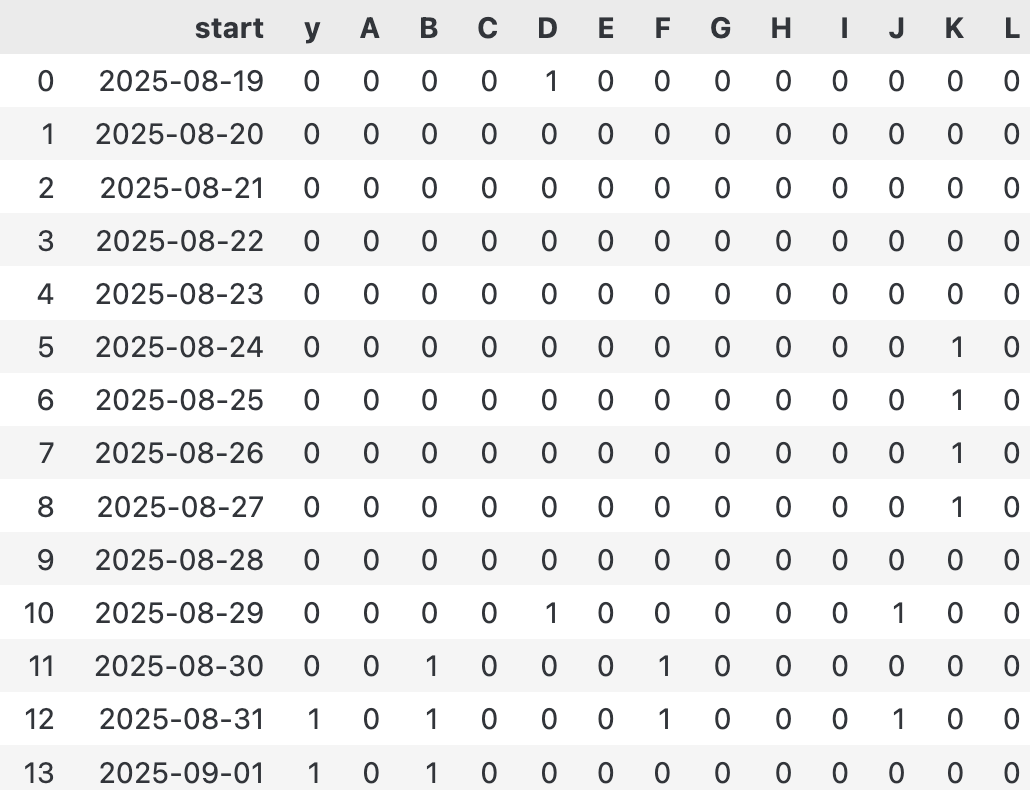 已脱敏的监控数据
已脱敏的监控数据
其中,列Y是我们的目标:1代表基站宕机,0代表正常。其他A到L列是各种监控指标的布尔值。在8月31日,基站不幸宕机。面对一堆0和1,我们需要回答:
- 是哪些因素的组合导致了故障?
- 是单次异常还是连续多天的异常更致命?
- 我们能否构建一个模型,来预测未来的风险?
初看数据,我们发现一些看似矛盾的记录,这表明故障可能是概率性的。这恰好是机器学习大显身手的领域,特别是被誉为“表格数据之王”的XGBoost。
定义问题:让XGBoost看懂时间¶
要让XGBoost理解“过去N天”的数据,我们不能直接将一个时间窗口内的数据矩阵扔给它。XGBoost处理的是表格数据,每一行代表一个独立的样本,每一列是一个特征。
因此,我们必须将时间序列“压平”(Flatten),将过去N天的所有监控值,转换为一个长长的一维特征向量。这个过程称为特征工程,是连接时序数据和机器学习模型的关键桥梁。
具体来说,对于第i天的样本,它的特征向量\(X_i\)将由过去n天所有监控指标A到L的值拼接而成:
下面的Python代码实现了这个转换过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | |
以n=3为例,转换后的数据形态如下,每一行都包含了当天(y)以及过去3天所有指标(A_1到L_3)的信息:
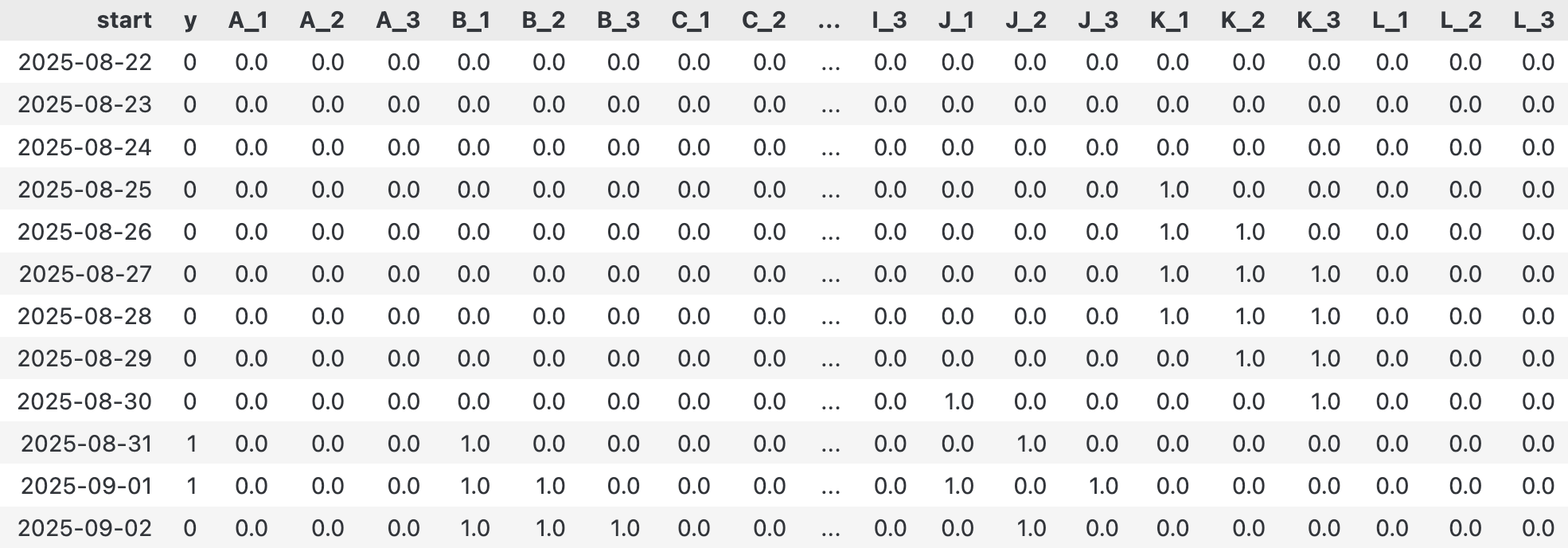 展开后的特征矩阵
展开后的特征矩阵
训练:请XGBoost出马¶
数据准备就绪后,我们就可以请出主角——XGBoost。训练过程本身非常直接。我们使用XGBClassifier,并选择适合二分类问题的目标函数(如binary:logistic)和评估指标(如logloss)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | |
训练完成后,模型就学习到了各个特征与“宕机”之间的复杂关系。接下来,就是揭开谜底的时刻。
归因分析:全局与局部¶
全局重要性:谁是关键嫌疑人?¶
首先,我们可以通过模型的get_booster().get_score()方法,查看每个特征的全局重要性(gain)。这告诉我们,在模型看来,哪些特征对区分“正常”与“宕机”的贡献最大。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
在我们的案例中,结果可能显示K_2(即两天前的K指标)的重要性远超其他特征,成为头号“嫌疑人”。同时,它还展示了K_1(即一天前的K指标)也会对此有所贡献。
为了进一步验证它的“罪行”,我们可以使用部分依赖图(Partial Dependence Plot, PDP)进行一次“思想实验”。PDP的逻辑是:假设我们能控制变量,当其他所有特征保持不变时,仅仅改变特征K_1的取值(从0到1),观察模型的平均预测概率会如何变化。这能帮助我们隔离并理解单个特征对最终结果的纯粹影响。
1 2 3 4 5 6 | |
我们将这个结果绘制成为热力图,再来讨论:
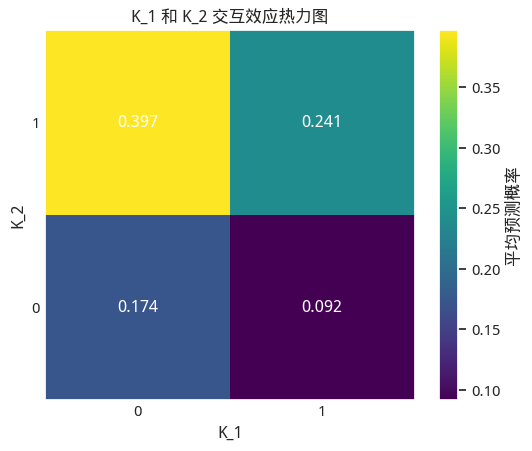 K_1 和 K_2 交互效应热力图
K_1 和 K_2 交互效应热力图
结果非常有意思!
- 如果前天异常,昨天正常,此时风险最高,达到了近40%。这比较反直觉。
- 强烈的交互效应: K_1 (昨天状态)的影响完全取决于 K_2 (前天状态)。
- 如果前天正常 ( K_2=0 ),那么昨天出现异常 ( K_1=1 ) 反而让风险从 17.4% 下降 到 9.2%。
- 如果前天异常 ( K_2=1 ),那么昨天继续异常 ( K_1=1 ) 会让风险从 39.7% 下降 到 24.1%。
- 这说明,一个“持续的”异常信号反而没有一个“刚刚恢复的”异常信号危险。
- 最安全的情况: 当 前天正常,昨天出现异常 ( K_2=0, K_1=1 ) 时,风险概率反而最低,仅为 9.2% 。
Attention
有必要强调一下,我只拿到了19条记录。出现这么奇怪的结果也不奇怪。
使用 SHAP 进行局部归因:重回“案发现场”¶
全局分析告诉我们K_2很重要,K_1也有一定的贡献,但这还不够。要进行“事件归因”,我们更关心的是:在8月31日基站挂掉那一天,各个因素到底扮演了什么角色?是哪个或哪些特征的取值,最终导致了“死亡”?
这就是局部可解释性(Local Explainability)要解决的问题,而 SHAP (SHapley Additive exPlanations) 是解决这个问题的最佳工具。它可以清晰地展示出对于单次预测,每个特征值是“推手”还是“拉手”,以及各自贡献了多少。
让我们聚焦到“案发”当天的样本,用 SHAP 来进行一次“法医鉴定”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
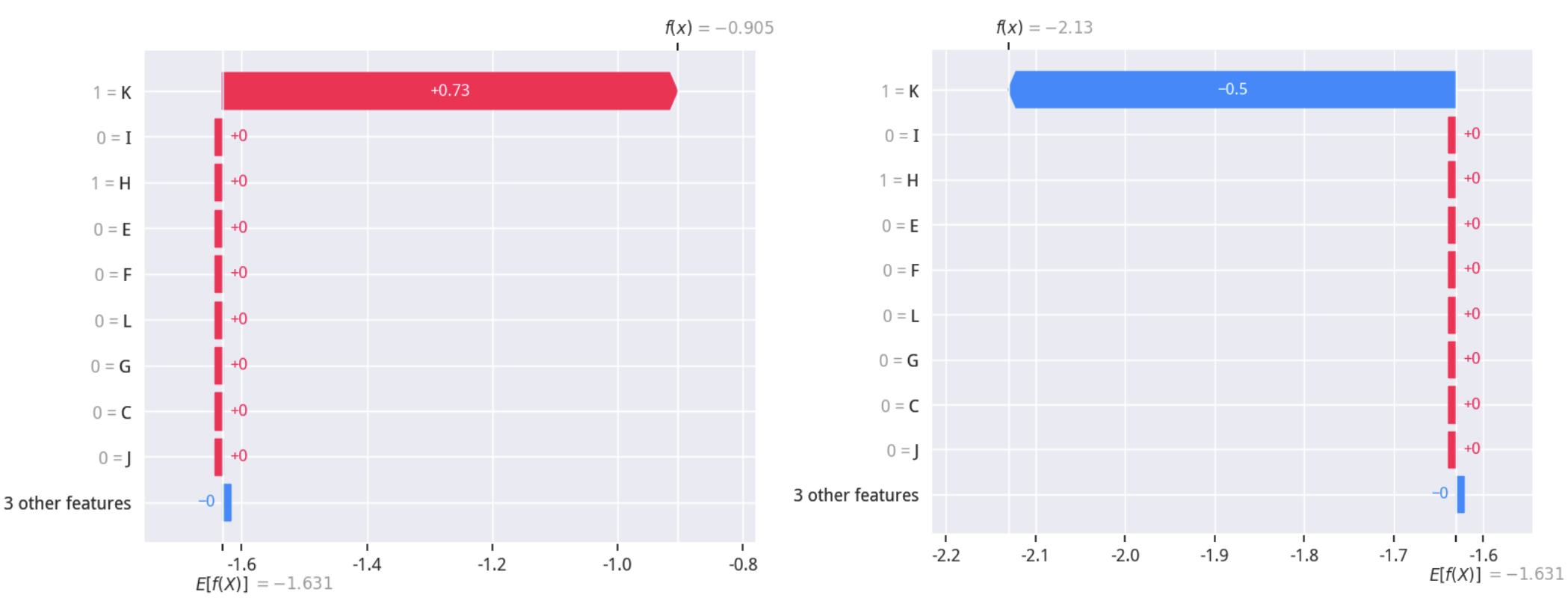
输出的图被称为SHAP Waterfall 图。如何解读它呢?
E[f(X)]是模型的基准值,代表所有样本的平均预测概率。但这里输出的都是对数几率,需要通过公式\(p = \frac{1}{1 + e^{-E[f(X)]}}\) 转换为概率。当前值转换的结果大致是21%,也就是从已知数据来看,基站挂掉的概率大概是21%。- 图表从基准值开始,自下而上展示每个特征的贡献(SHAP值)。
- 红色条块代表该特征的当前取值推高了最终的预测概率(风险因素)。
- 蓝色条块代表该特征的当前取值拉低了最终的预测概率(安全因素)。
- 所有特征的贡献累加,将预测从基准值
E[f(X)]推向了该样本的最终预测值f(x)(右上)。
通过左图,我们可以一目了然地看到,在宕机那天,K_1=1 是导致预测概率大幅上升的主要元凶。这为我们的归因分析提供了最直接、最微观的证据。
现在,我们可以输出 y = 1的那些天,究竟是哪些因素导致了基站挂掉:只要找出 shap_values 中那些大于0的列,把序号转换成对应的天,即可输出:
| 故障日期 | 故障原因及发生日期 | 说明 |
|---|---|---|
| 8月31日 | 8月30日,因素 k | 即 K_1 = 1 |
| 8月29日,因素 k | 即 K_2 = 1 |
模型思考:XGBoost与时序的正确关系¶
我们把时序数据“压平”喂给XGBoost,这种操作是否总是有效?
答案是:这取决于我们面对的是哪种“时序数据”。
XGBoost本身无法直接学习时间序列中的自相关性、趋势或季节性。它看待每个特征(比如K_1, K_2)都是独立的,无法理解K_1是K_2的“昨天”。因此,如果数据的核心在于时间上的连续动态(比如股价的连续波动),这种“压平”操作会丢失关键信息,模型效果将大打折扣。
然而,在我们的基站案例中,这种方法是有效的。为什么?因为这里的“时序”更多是事件日志的性质。我们关心的是在故障发生前,某个特定事件(如K=1)是否出现过,以及它出现的时间点(昨天、前天)。每个滞后特征(K_1, K_2)本身就是一个独立的事件标志。模型要学习的不是K这个指标的动态变化,而是K_1=1这个事件与故障y=1之间的关联强度。
这引出了一个核心观点:XGBoost无法替代时序分析,但可以成为强大特征工程的“裁判”。
在量化交易中,我们不会直接将过去10天的收盘价作为10个特征输入模型。我们会先通过特征工程,将这些时序信息提炼成有经济学或统计学意义的指标,比如移动平均线(MA)、相对强弱指数(RSI)、动量等。这些指标本身就是对时间序列的高度浓缩和降维。
然后,我们将这些“因子”作为特征,送入XGBoost进行打分和组合。此时,XGBoost判断的是你的特征工程是否有效,而非直接处理原始时序。如果你的特征工程做得好,XGBoost将非常高效地告诉你哪些因子在当前市场环境下最重要。这正是我们在《因子挖掘与机器学习策略》课程中深入揭示和反复演示的核心思想。