前视偏差 - 看似明白,实则糊涂
Table of Content
之前有一篇关于数据标注的笔记,得到了较多关注,也引起了一些同学质疑:
你使用了zigzag函数,这不会引起未来数据吗?
未来数据更学术化的说法叫前视偏差(look-ahead bias),回测中引入了未来数据,确实是做量化中很容易犯的一个错误。
这篇笔记解释了zigzag为什么用在标注中,不会产生未来数据。我们还列举了一些其它前视偏差的例子。这些是量化的经验之谈,来自实践,很少能在论文中看到。
Zigzag与 peak_and_valley_pivots¶
在之前的笔记中,我提到了使用zigzag函数来寻找k线中的波峰与波谷,并作为监督学习的标注数据。如果波峰记为1,波谷记为-1,其它的都记为0,则我们一共生成了三类标签。
这个标注数据还包含了原始的k线数据。因此,你可以基于这个数据集,构造自己的特征数据来训练模型,使之能预测一段行情的顶和底。
构建特征数据(因子)时,可以用RSI、均线拐头、上下影线、成交量放大、整数位等支撑、压力指标、压力线、支撑线等等。
数据标注使用zigzag包里的peak_and_valley_pivots函数。这个包可以通过以下命令进行安装:
1 | |
peak_valley_pivots接受三个参数,第一个是要检测峰谷的时间序列,第二个参数用来设置下跌的幅度、第三个参数用来设置上涨的幅度。
也就是说,在序列\([t_0, t_1, t_2]\)中,如果\(th_1\)是下跌阈值,\(th_2\)是上涨阈值,则当 \(t_1 >= t_0 \times (1 + th_2)\) 并且 \(t_2 <= t_1 \times (1 + th_1)\)时,\(t_1\)就会被标记为波峰,如下图所示:
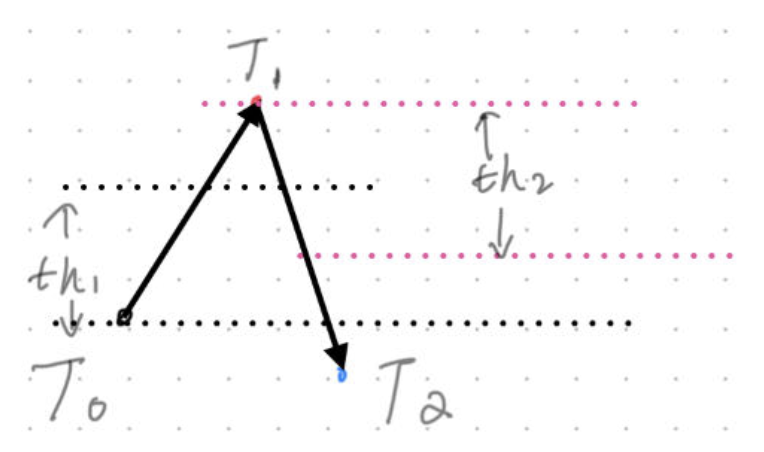
在Python中,还存在其它许多类似的库,最著名的是来自scipy.signals模块下的 find_peaks, find_peaks_cwt, argrelextrema 等。这些函数都要求我们至少设置判断峰谷的涨跌阈值(绝对值),有的还会允许设置驻点窗口大小。但是,zigzag 包中的peak_valley_pivots 方便之处在于,它不是通过绝对值来设置阈值,而是通过输入一个百分比来设置 -- 这是我们更常遇到的场景。
Tip
数字信号处理(Digital Signal Processing)在量化上有特殊的用途。文艺复兴早期在招人时,就很看重具有数字信号处理经验的人,他们从IBM viavoice团队挖了不少人。早期的声音识别是典型的数字信号处理应用,现在才全部转为深度学习。像傅立叶变换、小波变换等技巧,至今仍有不少论文在研究。
在具体使用peak_valley_pivots时,有两个简单的技巧。
首先,如何设置涨跌阈值?在实践中,我们常常先求得时间序列的每期涨跌幅。对股价波动而言,这是一个近似于平稳的序列。对这个序列求其标准差,±2倍标准差就可以作为阈值。
如果股价的涨跌近似于正态分布,那么如果t1超过t0达到2倍标准差的概率应该小于5%,把它认为是一个Outlier(离群值)显然是合适的(注意这里有很多近似处理的地方。严格来讲,股价涨跌近似于正态分布,并且股价超过平均值2倍标准差,概率才会小于5%)-- 换句话说,它就是我们要找的峰(或者谷)。
另一个技巧是,你必须理解peak_valley_pivots是如何处理头尾的数据的。
为什么说“zigzag会引起前视偏差”?¶
无论如何,peak_valley_pivots都在序列索引为0和-1的位置处,返回峰(1)或者谷(-1)的标签,无论这些点上的涨跌是否达到了阈值。这也是我们这篇笔记讨论前视偏差的起点。
我们再回顾一次之前的标注图。这一次,我们加入了一些序号以方便讨论。
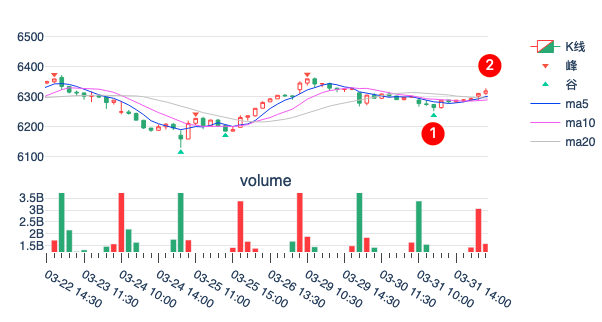
在这个图中,peak_valley_pivots 对位置1和位置2都给出了标注,分别是-1和1。
但是,我们的标注工具没有显示位置2的标注。因为此时这个标注并不能固定下来。当我们投喂更多的数据时,我们发现,在位置2处的标注消失了(指peak_valley_pivots的返回结果,而非图中的显示),直到4月6日下午14:30分,peak_valley_pivots 才重新给出了标注(见位置3)。
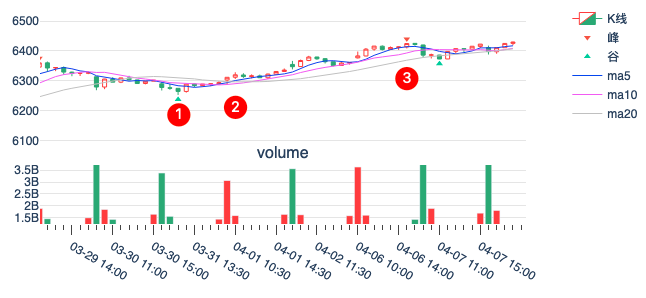
这是我们在标注历史数据时会发生的情况。如果我们的标注工具是一次性地对一个非常长的序列进行的标注,那么我们将只会在头和尾遇到一次这样的问题(⚠️⚠️但是,此时阈值会在这个序列的全生命期上进行计算,这个阈值将会与只在近期较短一段时间上计算出来的不一致)。
在对数据进行分批标注时,数据被截断,从而引入了更多的头和尾,在这些边界上, peak_valley_pivots都给出标注,但往往是不稳定的(对开头而言,它很可能是错的或者多出来的)。但从倒数第二个标注起,它就已经被固定下来,不会变更。
这样会引起未来数据吗?
当然不会。这个标注过程完全正确。
⚠️但一些同学使用zigzag,并不是用来做数据标注的,而是用它来做回测的,这就会出现问题。⚠️
这个回测错误具体地说是这样产生的:在\(t_2\)时间点时,检测到了发生在\(t_1\)时间点上的一个峰,此时,如果按\(t_1\)的价格去卖出:
- 如果回测系统是正确的,模拟交易不可能完成。如果能够完成,意味着股价又返身向上了,此时在\(t1\)和现在的时间点\(t_0\)之间,已经出现一个谷底。这意味着我们把该持有的股票,错误地卖出了。
- 有的同学可能使用自己写的回测系统,比如,通过pandas dataframe来做向量回测,此时就非常容易引入错误,导致在\(t_0\)时间点时,回到\(t_1\)时间点,以该点时的价格,将股票卖出在最高点。
这是一个很容易理解,但又常常会隐藏在你的代码中的错误 -- 如果你不了解回测系统的运行原理的话。
Tip
既然zigzag的顶底标注不能用来预测,那么它还有用吗?答案是肯定的。虽然我们不能用zigzag来预测顶底,但是,它可以用来标注历史数据,以验证我们找出来的关于顶和底的特征是否属于高概率特征。
如果是,那么在实盘中,当这些特征再次出现时,我们就敢于预测,一个顶或者底出现了。
前视偏差常见的场景¶
产生前视偏差的场景很多。一般来说,它往往产生于数据的采集和发布过程,或者产生于加工处理方法。
比如,财务数据很容易产生前视偏差。财务数据常常以季度为单位进行“索引”。很自然地,财务数据的编制和发布时间要晚于这个“索引”时间。
以2019年一季度美国的宏观经济数据发布为例。GDP预估值发布于2019年4月25日;5月30日进行第一次修正;最终修正则是在当年的6月27日。这是正常和可预料的情况。
Tip
在回测和实盘中如何避免这种前视偏差?在我们的《量化二十四课》的第22课有详细说明。
财务造假也会造成前视偏差。举一个A股中真实的例子。某海产品养殖公司,2014,2015年连续两年亏损被ST,如果2016年再亏损,按当时规则将进入退市流程。于是,2017年3月,该公司公布了2016年年报,净利润7571万,扭亏为盈,成功保壳。2019年,最终查实他们虚增利润1.3亿,追溯修订2016年财报为亏损-5543万。
如果我们现在(2024年)运行回测,由于这些数据已经得到了修正,当回测运行到2017年3月,我们取得的财报数据将是-5543万,这会帮助我们在回测中避开这个雷;但在2017年5月,实盘中获取到的该公司上年净利润为7571万。但你的模型在实盘中无法避开这种雷。
其它引起前视偏差的典型场景还有:
- 前复权
- 引用错误
- 偷价
- 统计函数如max、min、rank等,也包括zigzag类的函数
除了前视偏差,我们在回测中还可能遇到幸存者偏差、过度拟合、冲击成本、交易容量不足、回测时长不足、交易规则错误等各种偏差。这些都是只有在实战中才能获得的经验,我们在《量化二十四课》中都有介绍,可以帮你迅速提升经验值,由量化萌新成长为量化高手。
你也可以继续关注本号,我们后续会有机会深入讲解这些概念。
封面故事¶
封面是石溪大学的Charles & Wang中心,由美籍华人、亿万富翁、CA科技创始人王嘉廉捐助修建,是一座帮助人们了解亚洲文化和世界其它文化相互作用的建筑。

该建筑由砖块和白色半透明玻璃组成,象征着中国传统建筑中的窗楹蒙纸,此外还有一座带台阶的拱桥,让人联想到中国的寺庙。其内部有一个供学生使用的东亚美食广场,以便让人了解东亚、特别是中国的美食文化。
石溪大学与华人很有缘。杨振宁在此执教37年。丘成桐在此担任过助教。陈省身则是石溪的荣誉博士。
石溪大学出了很多名人,共拿了至少8个诺奖。量化教父James Simons则曾任该校数学系主任。